没错,你猜对了——答案是“42”。在这篇文章中,你就会看到关于 C++编程的 42 条建议, 这些建议可以帮助程序员避免很多错误,节省时间和精力。本文的作者是 Andrey Karpov ——“程序验证系统”项目(Program Verification Systems,PVS)的技术总监,他们这个项目组 主要是负责 PVS-Studio 静态代码分析器。检查过那么多开源项目的代码,我们看到过很多 犯错的方式,所以我们有很多经验可以分享给读者。每一条建议我们都用一个例子来解释以 证明问题的时效性。这些建议主要是面向 C/C++开发人员的,但是大多数是通用的,所以可 能对其他语言的开发人员也有益。

前 言
关于作者,我叫 Andrey Karpov。我的兴趣就是 C/C++以及改进代码分析的方法论。在 Visual C++的五年里,我获得了微软最具价值专家奖(Microsoft MVP)。我的这些文章和工作的首要目的就是让代码更安全。若这些建议能够让你避免一些常见的错误并写出更好的代码,我将不胜荣幸。那些为企业写代码规范的人也可从本文中得到一些有用的信息。
有个小背景。不久前,我创建了一个资源文件夹,在那里我分享了一些对 C++编程比较有用 的技巧。但这个资源文件夹的订阅用户并没有我预料的那么多,所以我觉得没有在这里放链 接的必要。这个文件夹应该会在网上放一段时间,但最终,会被删掉。然而,文件夹中的技 巧依旧有价值。这也是为什么我要更新它们,增加了几条新的技巧,然后把它们整合在一个 单独的文本里。阅读愉快。
1. 别 做 编 译 器 的 活
来看一段选自 MySQL 项目代码块,这段代码包含有一个错误,在 PVS-Studio 代码分析器中 表现为:V525 代码包含一系列相同的代码块。检查在 680、682、684、684、689、691、693、695 行 的“0”、“1”、“2”、“3”、“4”、“1”、“6”项。

解 释
这是一个关于代码复制粘贴的典型错误。很显然,程序员复制代码“if (a[1] != b[1]) return (int) a[1] - (int) b[1];”,然后开始改变下标,但是忘了将“1”改为“5”。结果导致在这 个比较函数中会返回不正确的值。这个问题比较不容易注意到,而且很难被检测到,因为在 我们使用 PVS-Studio 浏览 MySQL 之前所有的测死用力都没有检测出来。
正 确 代 码
if (a[5] != b[5])
return (int) a[5] - (int) b[5];
建 议
尽管这段代码简洁、易读,但是开发人员还是比较容易忽视掉这个错误。在阅读类似这样的 代码的时候你会比较难集中精力,因为你所看的都是相似的代码。
这些相似的语句块经常会导致一个结果,就是程序员会想要尽可能的优化代码。他手动“展开循环”。我认为在这里,循环展开并不是一个好法子。
首先,我会怀疑程序员能否真的从这里获得任何益处。现代的编译器都非常的智能,也非常善于在可以提升代码能力的情况下自动展开循环。
其次,这段代码块的 bug 是因为他想要优化代码。如果你把它写成一段比较简单的循环的话, 犯错的几率应该会小一点。
我会建议用下面的方式重写这个函数:
static int rr_cmp(uchar *a,uchar *b)
{
for (size_t i = 0; i < 7; ++i)
{
if (a[i] != b[i])
return a[i] - b[i];
}
return a[7] - b[7];
}
优 点
函数更易于阅读和理解
犯错的几率比较小
我敢肯定这个函数不会比原来那个版本运行慢。
所以,我的建议就是——写简单和易于理解的代码。具体来说,简单的代码就是正确的代码。 不要尝试去做编译器的活——比方说,展开循环。如果展开会比较好的话,编译器会去做的。 做这种手动优化的工作只有在一些比较重要的代码块那里才会有意义,而且这只有在 profiler 已经将这些代码块判断为有问题(慢)的时候才成立。
2. 大于 0 并不意味着是 1
下面这个代码块选自 CoreCLR 项目。这个代码包含一个错误,在 PVS-Studio 分析器中诊断 为:V698 表达式“memcmp(....) == -1”不正确。这个函数的返回值不是只有“-1”,可以是任意 的负数值。可以考虑用“memcmp(....) < 0”来代替。
bool operator( )(const GUID& _Key1, const GUID& _Key2) const
{ return memcmp(&_Key1, &_Key2, sizeof(GUID)) == -1; }
解 释
让我们来看一下memcmp()函数的描述:
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
将ptr1指向的存储单元里的前num个字节和 ptr2 指向的存储单元里的前num个字节做比较。 如果它们都相等就返回0,如果不等,返回一个非0的数来表示大于。
返回值:
<0< span="">—— 两个存储单元里的字节不相等,ptr1里的值小于ptr2里的值(如果以无符号 char 值作为比较)
==0——两个存储单元里的内容相等
>0——两个存储单元里的字节不相等,ptr1里的值大于ptr2里的值(如果以无符号char值作为比较)
注意到如果存储块里的东西不一样的话,函数的返回值会大于或小于0。大于或小于。这很重要。你不能将memcmp(), strcmp(), strncmp(),等等这些函数的返回值与常数1或-1进行比较。
有趣的是,这段将返回值和1/-1进行比较的错误代码,多年来也能返回程序员所期望的值。 但只是运气而已,别无其他。函数的行为可能产生意想不到的变化。比如说,你可能换了一 个编译器,或者开发人员会以一种新的方式优化memcmp()函数,那你的代码就不起作用了。
正 确 代 码
bool operator( )(const GUID& _Key1, const GUID& _Key2) const
{ return memcmp(&_Key1, &_Key2, sizeof(GUID)) < 0; }
建 议
不要觉得函数现在起作用就好。如果文档说一个函数可以返回大于和小于 0 的值,那么它就 真的会。它意味着这个函数可以返回-10 ,2 ,或 1024. 你经常见到它返回-1 ,0 ,1 并不意 味着什么。
还有,函数能返回类似于 1024 的事实表明了memcmp()的运行结果不能以 char 变量进行排序。 这是一个比较多人会犯的一个错误,其后果很严重。这个错误就是 MySQL/MariaDB 5.1.61、5.2.11, 5.3.5 ,5.5.22 版本以前一些高危漏洞的根源。当用户连上 MySQL/MariaDB 的时候,代码会记录一个值(对 hash 和密码进行 SHA 安全哈希算法后的值),然后这个值 将会用来和 memcmp() 函数的返回值进行比较。但是在一些平台下,返回值会超出 {-128… 127}。结果就是,有 1/256 的几率在比较 hash 值与预期值的时候总返回 true,不管 hash 值是 怎样的。因此,只要一条简单的命令行黑客就能无须密码黑进 MySQL 服务器。原因就是 “sql/password.c”文件里的这部分代码:
typedef char my_bool;
...
my_bool check(...) {
return memcmp(...);
}
3. 一次复制,多次检查
下面这段代码块选自 Audacity 项目。PVS-Studio 检测到的错误是:V501 在“-”的左边和右边 有相同的子表达式。
sampleCount VoiceKey::OnBackward (....) {
...
int atrend = sgn(buffer[samplesleft - 2]-
buffer[samplesleft - 1]);
int ztrend = sgn(buffer[samplesleft - WindowSizeInt-2]-
buffer[samplesleft - WindowSizeInt-2]);
...
}
解释 “buffer[samplesleft – WindowSizeInt-2]”这个表达式减去它本身。出现这个错误是因为在复制 代码块( 复制 -粘贴)的时候,程序员忘了把 2 改为 1。
这真是一个很不起眼的错误,但它终究是个错误。这样的错误于程序员而言确实是一个残酷 的事实,所以我们要在这里多讲几遍。我要向它们宣战。
正 确 代 码
int ztrend = sgn(buffer[samplesleft - WindowSizeInt-2]-
buffer[samplesleft - WindowSizeInt-1]);
建 议
在复制代码的时候须谨慎小心。
让程序员拒绝使用复制粘贴是没意义的。因为它太方便,太有用了,我们怎能弃之不用。 所以,要谨慎小心,不要急——凡事欲则立。
记得复制代码可能会引起很多错误。大部分被诊断为 V501 错误的代码都是因复制粘贴引起 的。
如果你要复制代码后编辑它,记得检查一下代码,不要偷懒。
我们稍后会详谈复制粘贴。我希望你能记住,这个问题比我们想象的要严重。
4. 当心三元运算符“?:”,用括号把它括起来
下面这段代码块选自 Haiku 项目(BeOS 的继承者)。这段代码中的错误被 PVS-Studio 诊断 为:V502,有可能“?:”不能返回你所期望的值。“?:”的优先级低于“-”。
bool IsVisible(bool ancestorsVisible) const
{
int16 showLevel = BView::Private(view).ShowLevel();
return (showLevel - (ancestorsVisible) ? 0 : 1) <= 0;
}
解 释
让我们来看一下 C/C++运算符的优先级.三元运算符“?:”的优先级非常低,比/,+,<这些 运算符的优先级要低,甚至低于减号运算。所以,刚刚那段代码的返回值可能不能如程序员 预期的那样。
程序员认为那些操作会以如下顺序执行:
(showLevel - (ancestorsVisible ? 0 : 1) ) <= 0
但事实上,它的顺序是这样的:
((showLevel - ancestorsVisible) ? 0 : 1) <= 0
在这样简单的代码发生这样的错误,也说明了“?:”有多么难搞。在使用它的时候很容易出 错,尤其是当这个三元运算符的判断条件比较复杂的时候,它可能就是代码中唯一的错误。 而且不是你会出错这么简单,这样的表达式也比较不易读。
真的,要当心“?:”运算。我看到过蛮多在使用这个运算符的时候出现的错误。
正 确 代 码
return showLevel - (ancestorsVisible ? 0 : 1) <= 0;
建 议
在之前的文章中,我们已经讨论过关于三元运算符所引起的错误,但自从那以后我就变得更 多疑了。上面给的那个例子说明了在使用三元运算符时是多么容易出错,就算在简短简单的 表达式中也不例外,这也是为什么我要修改我之前的那些技巧。 我不建议完全不用“?:”。有时它也很有用很必要的。然而,请勿滥用。如果你已经决定要 使用它,那我的建议就是:要加括号。
假设你有这样一个表达式:
A = B ? 10 : 20;
那我建议你这样写:
A = (B ? 10 : 20);
好吧,括号在这里有点多余……
但是, 当以后你或者你的同事要重构函数时,比如说在 10 或 20 那里加一个变量 x: A = X + (B ? 10 : 20);
没有括号,你可能会忘记“?:”的优先级非常低,然后就会出错哦。
当然啦,你也可以把“x+”写在括号里,然后也会导致同样的错误。
虽然看上去好像有保护到 它,但并没有。
5. 使用可利用的工具去分析你的代码
下面的代码来自 LibreOffice 项目。其错误在 PVS-Studio 中诊断为:V718 “Create Thread”不 能被“DllMain”调用。
BOOL WINAPI DllMain( HINSTANCE hinstDLL,
DWORD fdwReason, LPVOID lpvReserved )
{
....
CreateThread( NULL, 0, ParentMonitorThreadProc, (LPVOID)dwParentProcessId, 0, &dwThreadId );
....
}
解 释
过去有段比较长的时间我都有在兼职网站找兼职做。有次,我没能完成我接的任务。任务本身就没表述正确,但是我那个时候并没有意识到。毕竟它乍一看挺简单清晰的。
在 DllMain 里的特定条件下,我要使用 Windows API 的函数来做一些操作,具体什么操作我忘了,但是应该不难。
我花了蛮多时间在上面,然而代码就是运行不了。更离奇的是,当我新做一个标准化应用的 时候,它又运行得了,但在 DllMain 函数里面就是运行不了。好神奇,对不对?那个时候我 没能找出问题的根源。
直到多年后的现在,我在 PVS-Studio 部门工作,我才突然意识到当年我代码运行不了的原因。在 DllMain 这个函数里,你所能做的动作是有限的。因为有些动态链接库还没有加载进 来,那当然你就不可以调用它们啦。
现在,当程序员要在 DllMain 里删除一些危险操作的时候,我们就会有一个诊断程序来提醒程序员。也就是这个,来源于我当年的一个任务。
细 节
更多关于 DllMain 的使用都可以在 MSDN 的这篇文章找到:Dynamic-Link Library Best Practices ,在这里我放一些那篇文章的摘要:
在加载器锁被挂起的时候就会调用 DllMain。因此那些能调用 DllMain 的函数会有比较多的限制。结果就是,DllMain 被设计为只能使用小部分的微软的 Windows API 来执行很少的初始化任务。你不能在 DllMain 里直接或间接的调用任何函数来尝试申请加载器锁。不然,你 的应用程序会有可能死锁或崩溃。DllMain 里的一个错误可能危及整个进程以及它的所有线程。
最理想的 DllMain 应该是一个空的桩代码(stub)。但是考虑到很多应用程序的复杂性,这样太受限了。所以使用 DllMain 的一条比较好的原则就是尽可能的延长初始化。晚点初始化能增强应用程序的鲁棒性,因为当加载器锁被挂起的时候,初始化无法完成。而且,晚点初 始化能让你更安全地使用比较多的 Windows API。
一些初始化任务无法推迟。举个例子,如果布局文件(configuration file)出错了或者包含有 垃圾,那么依赖于布局文件的动态链接库(DLL)就无法加载。对于这种类型的初始化,那 些动态链接库应该尝试着去加载,如果加载失败就立马退出,而不是浪费其他资源去做其他 事。
在 DllMain 里面你不应该做以下这些事:
调用 LoadLibrary 或者 LoadLibraryEx(不管是直接还是间接)。这样会引起死锁或崩溃。
调用 GetStringTypeA, GetStringTypeEx,或者 GetStringTypeW(不管是直接还是间接), 这样会引起死锁或崩溃。 于其他进程同步。这样会引起死锁。
申请一个同步对象,而该产生该对象的代码正在等待申请加载器锁。这样会引起死锁。
在一定条件下用 CoInitializeEx 初始化 COM 进程。这个函数会调用 LoadLibraryEx.
调用注册函数。这些注册函数是由 Advapi32.dll 来实现的。如果 Advapi32.dll 没有在 你的动态链接库之前初始化完成,那你的动态链接库可能就会访问非初始化的内存, 然后引起进程崩溃。
调用 CreateProcess. 创建一个进程会加载其他动态链接库。
调用 ExitThread. 在动态链接库没加载的情况下退出一个进程需要再次申请加载器锁, 然后就会引起死锁或者进程崩溃。
调用 CreateThread. 新建一个进程后就算你不把它与其他进程同步它可能也能运行,但 是很危险。
创建一个命名 pipe 或者其他命名对象(仅针对 Windows 2000)。在 Windows 2000 中, 命名对象由终端服务的动态链接库(Terminal Services DLL).如果这个动态链接库还没 有初始化,调用它就会引起进程崩溃。
使用 C 语言的动态运行时库(CRT)里的内存管理函数。如果 CRT DLL 还没有初始 化,调用这些函数就会引起进程崩溃。
调用 User32.dll 或 Gdi32.dll 里的函数。有些函数会加载其他 DLL,而这些 DLL 可能 还没有初始化。
使用受监督代码
正 确 代 码
上面那段引自 LibreOffice 项目的代码块有的时候能运行,有的时候不能运行。——全凭运气。
要解决类似这样的问题比较麻烦。你需要尽可能地重组你的代码以使 DllMain 函数更简单, 更简短。
建 议
很难给出建议。你不可能万事皆知,每个人都有可能遇到这种离奇的错误。所能给的建议无 非是:对于你所负责的项目,要仔细阅读所有文档。但你也知道,我们无法预见所有的问题。 当你把所有的时间都用来阅读文档,那就没有时间来编程了。还有,就算你已经看了 N 篇文 章,你也无法确定你有没有漏掉那些告诉你如何应付其他问题的文章。
我希望我可以给你一些有用的小贴上,但很遗憾,我只能想到一个:使用静态分析器。不, 这也不能保证你的代码没有任何 bug。如果多年前有一个代码分析器告诉我说,我不能再 DllMain 调用 foo 函数,我可能会节省很多时间和精力:无法完成那个任务真的让我蛮生气的,快要气炸了。
6. 检查所有指针强制转换成integer类型的代码快
下面的代码选自 IPP Samples 项目。这里的错误被 PVS-Studio 诊断为:V205 强制转换指针 类型为 32 位 integer 类型:(unsigned long)(img)
void write_output_image(...., const Ipp32f *img,
...., const Ipp32s iStep) {
...
img = (Ipp32f*)((unsigned long)(img) + iStep);
...
}
注意。有人会说因为一些原因,这段代码并不是最好的例子。我们并不关注为什么一个程序 员会需要以这样奇怪的方式进入数据缓冲区。我们在意的仅仅是,指针被转换成了“unsigned long”类型。我选择这个例子只是因为它简洁。
解 释
一个程序员想要把一个指针转换为特定数目的字节。这段代码在 win32 下能够正确运行,因 为指针的大小正好等于 long 类型的大小。但是如果我们编译的是这段代码的 64 位版本,指 针就会变成 64 位,将它强制转换成long类型会确实高位。
注意。Linux 使用不同的数据模型。在 64 位的 Linux 项目中,“long”类型也是 64 位。虽然如 此,但用“long”来存储指针委实不是一个好主意。首先,这样的代码比较常用于 Windows 应 用程序中,但是在 Windows 下面,它是出错的。其次,有专门用来存储指针类型的数据类型, 比如说,intptr_t.用这些类型可以让程序看上去更干净一些。
在上面的例子中,我们可以看到一个发生于 64 位程序中的典型错误。更直白一点说,在 64 位编程的道路上,程序员还会遇到很多其他的错误。但是把指针转换为 32 位integer变量是 一个最常见也最隐秘的问题。 这个错误可以用下面的图来表示:
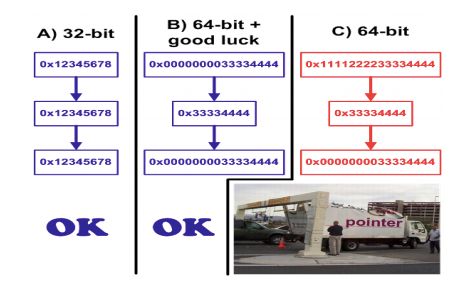
图 1 A)32 位程序 B)指向低位地址的 64 位指针。C)被破坏的 64 位指针。
讲一下它的隐秘性,这个错误有时候真的很难注意到。程序大多数都运行正确。在使用这个函数时,丢失指针里的重要位数这种事可能只会出现在少有的几个小时里。因为分配到的内存是来自低位地址的,也就是为什么所有的对象和数组都保存在前 4G 内存里。一切都很顺利。
当程序持续运行,内存变得四分五裂的,这样即使这个程序并没有用到那么多内存,新建的 对象也可能会被创建在前 4GB 以外。然后,问题开始产生了。要重现这样的错误非常难。
正 确 代 码
你可以使用size_t, INT_PTR, DWORD_PTR, intrptr_t,等等这些类型来存储指针。
img = (Ipp32f*)((uintptr_t)(img) + iStep);
事实上,我们可以不强制转换指针的。并没有见到在哪里有提到过说格式化不同于标准化的, 也就是为什么使用__declspec(align( # ))这样函数也没产生作用。
所以,除非要转换成数字类 型的指针能被Ipp32f整除,不然我们会触发一些没有定义过的行为。(详情看:EXP36-C)
所以,我们可以这样写:
img += iStep / sizeof(*img);
建 议
使用特定的类型来存储指针——把int和long忘掉吧。最常用来存储指针的类型是:intptr_t和uintptr_t。在 Visual C++ 里面,也可以用这些类型:INT_PTR, UINT_PTR, LONG_PTR, ULONG_PTR, DWORD_PTR。从它们的名字你就可以看出来,用它们来存储指针很安全。
size_t和ptrdiff_t也可以用来存储指针,但是我不建议用,因为它们原本的目的是用来存储 大小和下标的。
你不能用uintptr_t类里的成员函数来存储指针。成员函数跟标准函数还是有些许不同的。除 去指针本身,成员函数会隐藏掉指向其他类对象的this指针的值。然而,这也不重要——在 32 位程序中,你无法把这样一个指针赋值给unsigned int类型。这些指针一般会以一些特殊 的方式处理的,这就是为什么 64 位程序里没那么多错误。至少,我没有看到这样的错误。
如果你打算把你的程序编译成 64 位,第一件事就是,你需要检查并修改所有把指针强制转 换为 32 位integer类型的代码块。记住——可能程序里还是有其他错误,但是你应该从指针开始检查。
对于那些在开发或者打算开发 64 位应用程序的,我建议你们看一下这个材料:Lessons on development of 64-bit C/C++ applications.
7. 别在循环里调用 alloca() 函数
在 Pixie 项目中发现了这个 bug。该错误被 PVS-Studio 诊断为:V505 在循环里使用了“alloca” 函数。这样很快就会导致栈溢出。
inline void triangulatePolygon(....) {
...
for (i=1;i
...
do{
...
do{
...
CTriVertex*snvertex=
(CTriVertex *) alloca(2*sizeof(ctrivertex));
...
}while(dvertex != loops[0]);
...
}while(svertex=!= loops[i]);
...
}
...
}
解 释
alloca(size_t) 函数使用栈来分配内存。由 alloca() 分配到的内存要在函数执行完的时候才被回收。
分给程序的栈内存通常不多。当你在 visual c++里新建一个项目的时候,你可以看到默认就分配 1mb 的栈内存,这也就是为什么如果 alloca() 函数是在循环里的话,它很快就把可用的栈内存耗光了。
在上面那个例子中,一次就有三个循环,所以会造成栈溢出。
在循环里使用类似 a2w 的宏也不安全,因为它们中都有调用 alloca() 的函数。
就像我们前面所说的,windows 程序默认使用的栈内存。我们可以修改这个值,在项目设置里找到并“stack reserve size”和“stack commit size”的参数值。详情:“stack (stack allocations)”。然而我们应该明白,扩大栈内存并不能解决这个问题——你只是推迟了项目栈溢出的时间。
建 议
不要在循环里调用函数。如果你有一个循环,然后你又需要开辟一块临时缓冲区,用下面的 3 个法子中任意一个来解决:
提前申请内存,然后使用一个缓冲区来进行所有操作。如果你每次需要的缓冲区大小都不一样,申请最大块的内存。如果不行(你不知道具体它会需要多少内存),使用法2。
把循环单独放在一个函数里。这样,缓冲区在每一次迭代的时候都会申请、释放。如果这样也不行,就只剩下法3了。
用malloc()m或者其他操作来代替alloca(),或者使用类似std::vector函数。但是这样分配内存会比较耗时间。如果使用malloc/new你就要考虑到它的释放。另一方面,这样你在用比较大的数给客户演示程序的时候不会发生栈溢出。
8. 记住析构函数里的异常很危险
这个问题是在libreoffice项目里发现的。在 pvs-studio 中诊断为:v509 应该在 try……catch 里放‘dynamic_cast’操作,因为可能会产生异常。在析构函数里出现异常是非法的。
virtual ~LazyFieldmarkDeleter()
{
dynamic_cast
(*m_pFieldmark.get()).ReleaseDoc(m_pDoc);
}
解 释
析构函数可以在异常发生后在清理栈内存的过程中调用,也可以在对象生命周期结束时被调 用。如果在异常已经发生时调用析构函数,而在清理栈内存时又发生异常,异常之上又有异常,C++库只能调用terminate()来终止程序。所以从中我们可以知道,不要在析构函数中抛 出异常。析构函数中的异常要在同一个析构函数中处理。
上面引用的代码不只是危险那么简单。动态强制转换操作失败的话会生成一个名为 “std::bad_cast”的异常。
类似的,任何可以抛出异常的构造函数也是危险的。比如说,在析够函数中用new操作来分 配内存就不安全,因为如果分配不成功会抛出“std::bad_alloc”异常。
正 确 代 码
要解决dynamic_cast可以不用引用类型而是用指针类型。这样,就算转换类型失败也不会抛 出异常。
virtual ~LazyFieldmarkDeleter()
{
auto p = dynamic_castm_pFieldmark.get();
if (p)
p->ReleaseDoc(m_pDoc);
}
建 议
让析够函数尽可能的简单。析够函数不是用来分配内存和文件读取的。
当然,有时候我们无法做到让析够函数变得简单,但是我们要尽力达到这一点。此外,复杂 的析够函数也说明类的设计不合理,以及这个方案不是最简便的方案。 你在析够函数里写的代码越多,它越难把问题解决好。因为这样,更难指出那个代码块可以 或者不可以抛出异常。
如果有一定几率会发生异常的话,我们可以把它都最后写在catch(...)里:
virtual ~LazyFieldmarkDeleter()
{
try
{
dynamic_cast
(*m_pFieldmark.get()).ReleaseDoc(m_pDoc);
}
catch (...)
{
assert(false);
}
}
没错,这样使用可能会掩盖住一些发生在析构函数里的错误,但这也有助于程序更稳定的运 行。
我并不坚持说一定不要在构造函数里抛出异常——视情况而定吧。有时在析构函数里抛出异 常会更有用。我也看到过一下专门的类中是可以抛出异常的,但这些情况很少,而且那些类 就是被设计为可以在析够函数里抛出异常的。如果是比较常见的类如:"own string","dot", "brush" "triangle", "document"等等,就不应该在析构函数里抛出异常。
只要记住,在一个异常之上又抛出异常会让程序终止。所以,一切都取决于你想不想让这种 事发生在你的程序身上。
9. 用 '\0' 来结束空字符
片段选自 Notepad++项目。其错误被 PVS-Studio 诊断为:V528 'char' 指针要跟'\0' 比较值很奇 怪。 可能是想表达:*headerM != '\0'。
TCHAR headerM[headerSize] = TEXT("");
...
size_t Printer::doPrint(bool justDoIt)
{
...
if (headerM != '\0')
...
}
解 释
感谢这段代码的作者,使用'\0'来作为结束空字符,这让我们很容易定位和修正这个错误。作 者大大做得好,但还不够好。
假设代码是这样写的:
if (headerM != 0)
数组地址和 0 比较,这其实没什么意义,因为比较结果总是 true。所以这是什么——一个错 误或者多余的检查?很难说,尤其是如果这个代码是别人的代码或者说这个代码写了很久。
但既然程序员在这段代码中用了'\0',我们就假设程序员是想要检查某一个字符的值。然 后我们又知道,比较 headerM 指针和 NULL 没意义。所以我们认为作者是想知道那个字符 串是否为空或者在写检测的时候没出错。要修改这段代码,我们需要增加一个指针间接引用 操作。
正 确 代 码
TCHAR headerM[headerSize] = TEXT("");
...
size_t Printer::doPrint(bool justDoIt)
{
...
if (*headerM != _T('\0'))
...
}
建 议
0 可以表示 NULL,false,空字符'\0',或者仅仅是 0。所以请不要偷懒——避免在任一个 案例中使用 0 作为简写的符号。
用下面的符号:
0——整数 0;
nullptr——C++中的空指针;
NULL——C 中的空指针
'\0', L'\0', _T('\0')——空结束
0.0, 0.0f——浮点类型的 0
false,FALSE——’false‘值
用这种方法会让你的代码更干净,也让你和其他程序员在重新检查代码时更容易定位 bug。
10. 避免使用过多的小块 #ifdef代码
代码选自 CoreCLR 项目。其错误被 PVS-Studio 诊断为:V522 可能会发生空指针‘hp’的间接引用。

解 释
我总觉得#ifdef/#endif是有害的——一个无可避免的害处。不幸的是,它们是必须的,我们 不得不使用它们。所以我不主张让你停止使用#ifdef,这么做没意义。但我想让你注意别“滥用”它。
我猜,你们中很多人都有见到过那种代码,满屏的#ifdef. 要看那种每十行就来一个#ifdef,或者更频繁的代码,真的很痛苦。这种代码是依赖于系统的,而且你不能不用#ifdef。尽管它 的存在没有让你更快乐一些。
你看,要阅读上面那段代码是多么难!有些程序员的基本工作就是阅读代码。是的,你没看错。我们花了非常非常多的时间来检查和学习已经写好的代码,比花在写新代码的时间上要 多得多。这也就是为什么阅读难读的代码会降低我们的效率,而且也比较容易出错。
回过头来看我们的代码,错误是在空指针间接引用的时候发现的,在没有声明 MULTIPLE_HEAPS 宏的时候发生的。为让你更容易理解,我们来展开那个宏:
heap_segment* gc_heap::get_segment_for_loh (size_t size)
{
gc_heap* hp = 0;
heap_segment* res = hp->get_segment (size, TRUE);
....
程序员声明了hp变量,初始化为null,然后立刻就间接引用它了。如果此时 MULTIPLE_HEAPS 还没有定义,自然会出错。
正 确 代 码
虽然我的同时已经在“25 Suspicious Code Fragments in CoreCLR”这篇文章中报告了这个错误, 但是这个问题依然存在于CoreCLR(12.04.2016)中。所以我也不知道解决这个错误的最好 的法子是什么。
我的想法是,既然(hp == nullptr), 那变量‘res’就应该也初始化为其他值——但是我不知道 具体是什么值。所以这次我们什么也不用做。
建 议
从你的代码中消除小块#ifdef/#endif——它们的存在真的让代码阅读与理解变得很困难。过多 的ifdef更容易出现错误。
并没有适用于任何情况的建议——都得视具体情况而定。无论如何,记住,ifdef 是麻烦之源。 所以你应该努力使你的代码尽可能的干净整洁。
Tip N1: 试着拒绝#ifdef
#ifdef有时可以用常量和if代替。比较一下下面两段代码:一个宏的变体:
#define DO 1
#ifdef DO
static void foo1()
{
zzz();
}
#endif //DO
void F() { #ifdef DO
foo1();
#endif // DO
foo2();
}
这段代码不好读,你不会愿意读的。我打赌,你直接略过了,有没有? 现在来看下面的代 码:
const bool DO = true;
static void foo1()
{
if (!DO)
return;
zzz();
}
void F()
{
foo1();
foo2();
}
现在更好读一点了。有人会说这样的话代码效率就没那么好了,因为它要调用函数,然后还 要在函数里检查它有没有定义过。我不同意这样的说法。首先,当代的编译器都非常智能, 你非常有可能会在 release 版本看到这样的代码:没有任何外部检查和函数调用。其次,这一点点损失就没必要过分纠结了,好吗。代码的干净整洁更重要。
Tip N2 :让你的#ifdef 代码块更大一点
如果我要写那个get_segment_for_loh()函数,我不会在其中使用很多#ifdef,我会用两个版本的函数来代替。对,字可能会比较多一点,但是函数很容易阅读和编辑了。
再者,有人会说,这是复制代码,既然每个#ifdef都有很多长度比较长的函数。每个函数都有两个版本容易让人在修改其中一个版本时忘记修改另一个版本。
嘿,等一下。为什么你的函数长度那么长?把所有的逻辑放到额外的备用函数——这样你两 个版本的函数都会变得更段一些。我敢肯定这样能让你更容易找出它们之间的不同。
我知道这个 Tip 并不能包治百病,但也要考虑这么做。
Tip N3. 考虑使用模板(templates)——有时它们也能帮到你。
Tip N4.在使用#ifdef 之前花点时间来考虑:你可以不用它吗?或者,你可以少用它并且只在 一个地方使用它吗?
原文:https://software.intel.com/en-us/articles/the-ultimate-question-of-programming-refactoring-and-everything
本文由看雪翻译小组 lumou 编译