自己喜欢在上班的途中听点有声书,所以经常在喜马拉雅上找资源,要找到一个好听的节目不容易,虽然在喜马拉雅官网上可以按分类来看,但是却不能按点赞数或者评论内容排序找,不是很方便,于是就用Python写了个爬虫,把所有声音的相关信息、评论内容都抓取下来,然后放到数据库来分析,这样喜欢什么样的资源,直接根据声音或评论的内容来汇总分析,结果就一目了然了。
流程实现图

Urllib,request, selenium
Web的访问使用urllib和urllib2,相比request、selenium来说,效率更高些,感觉也稳定些,之前使用request的遇到https的网址处理起来有点问题。而selenium呢,自动化操作可以不用分析具体页面的处理逻辑,不过对于这种海量数据,处理起来速度就会慢很多。
多线程和队列
使用了2个threading.Thread的继承类,Ximalaya类用来解析声音专辑,分析提取专辑内的声音信息,解析出评论地址;CommentDown类专门用来提取保存评论内容信息;一般一个声音会有多条评论,多的上千条评论,所以CommentDown分配了10个线程来提取评论,Ximalaya分配了3个线程来分析专辑的声音信息。
使用了2个队列,1个用来保存专辑url,大小100,1个用来保存评论url,大小设置为200;这样在超过队列最大值的时候就会停下来,等待前面队列里处理了再继续,可以有效控制整个爬虫速度,以免访问太过频繁被网站给屏蔽了。
数据保存
使用了Mongodb数据库,Nosql处理高并发的,相比SQL速度和效率要高得多。Mongodb里在music下保存声音的相关信息(比如声音的专辑名、专辑地址、声音的地址、声音的时长、点赞数等等),bookcomment下保存声音的评论内容。
断点续传、重复处理
遇到中途中断后要继续执行,还得考虑下断点续传,这里处理得比较简单粗暴,在Ximalaya处理声音的时候,会先判断数据库是否有声音的地址,如果存在就是跳过不再处理,在CommentDown处理评论的时候,判断判断数据库是否有声音的地址,如果存在就是跳过不再处理,这样对于后面比较费时处理部分都可以直接跳过,也不会存在有重复的数据会影响最后的分析的问题。
异常处理
程序在解析页面的时候,可能会有超时之类的异常情况,增加了对应的异常处理,socket.setdefaulttimeout(20)设置全局超时为20秒,超过20秒就会超时报错,这样再通过异常捕获来处理,设置了异常处理记数器,对于异常页面重复处理指定次数后不再处理,避免部分声音页面被删除一直访问异常的情况。
数据分析
最后对保存到数据库的数据进行分析,做分析的时候Nosql做关联分析太痛苦了,完全不如sql查询方便,于是把数据导入到Oracle来进行的分析,根据评论内容中的关键字来标识判断(例如:“点赞”,“好听”,“太棒“之类的都判断成受欢迎),最后再用汇总统计出结果。
评论最受欢迎的TOP20有声书:
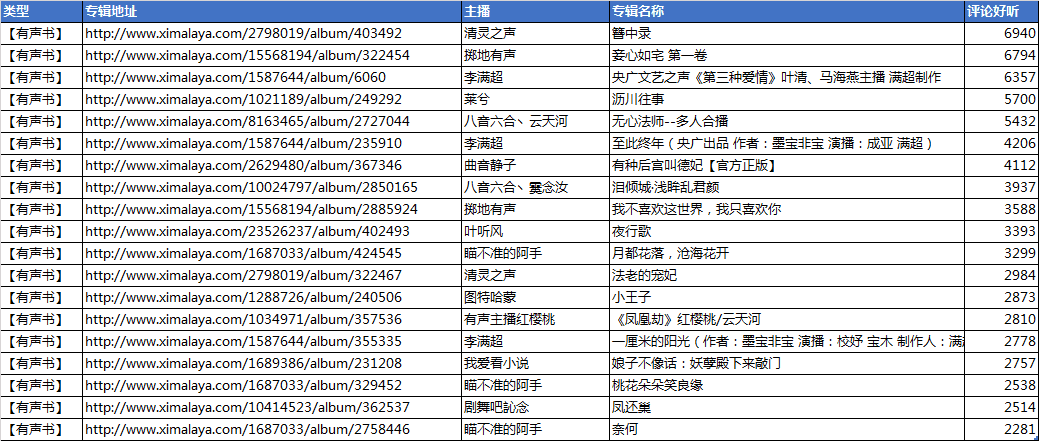
评论最受欢迎的TOP10综艺节目:

评论最受欢迎的TOP20音乐:

评论普通话说得最好的节目:

最后源代码也附上了,有兴趣的朋友可以自己看看:
爬虫源代码
#coding:utf-8
import urllib
from lxml import etree
import re
from pymongo import MongoClient
import socket
import threading
from Queue import Queue
import time
import random
import sys
import traceback
socket.setdefaulttimeout(20)
PgEr = 0
queue = Queue(200)
queue_in = Queue(100)
class Ximalaya(threading.Thread):
def __init__(self, queue, queue_in):
threading.Thread.__init__(self)
self.queue = queue
self.queue_in = queue_in
self.host = 'http://www.ximalaya.com'
self.client = MongoClient()
self.db = self.client.test
self.musicInfo = self.db.music
self.commentInfo = self.db.bookcomment
self.AgsEr = 0
self.SdEr = 0
self.ClgEr = 0
self.headers = {'Accept-Language': 'zh-CN',
'User-Agent': 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'www.introducer.westpac.net.au',
'Connection': 'Keep-Alive',
}
def run(self):
while not exit_flag.is_set():
time.sleep(random.uniform(1,3))
album_url = self.queue_in.get()
self.albumGetSounds(album_url)
self.queue_in.task_done()
print '*** Album done, url: %s, Queue: %s, Queue_in: %s, Page: %s ***' % (album_url, self.queue.qsize(), self.queue_in.qsize(), page)
def albumGetSounds(self, ab_url):
try:
html = urllib.urlopen(ab_url).read()
tree = etree.HTML(html)
sound_urls = tree.xpath("//div[@class='miniPlayer3']/a/@href")
album_title = tree.xpath("//div[@class='detailContent_title']/h1")[0].text
if sound_urls:
for sound_url in sound_urls:
sound_url = self.host + sound_url
#print 'Sound url is: ', sound_url
#如果在数据库找到声音url地址,就不再解析声音
exists_flag = self.Musicinfo_find(sound_url)
if not exists_flag:
print '>>> Sound put %s, Queue: %s, Queue_in: %s, Page: %s' % (sound_url, self.queue.qsize(), self.queue_in.qsize(), page)
self.soundpage(ab_url, album_title, sound_url)
else:
pass
#print 'Sound %s already exists, goto next >>>' % sound_url
except Exception as e:
print '***albumGetSounds error, error: %s, album url: %s' % (e, ab_url)
print traceback.print_exc()
self.AgsEr += 1
if self.AgsEr < 3:
print 'time sleep 15s.'
time.sleep(15)
self.albumGetSounds(ab_url)
def soundpage(self, a_url, a_title, s_url):
try:
html = urllib.urlopen(s_url).read()
tree = etree.HTML(html)
title = tree.xpath("//div[@class='detailContent_title']/h1")[0].text
music_type = tree.xpath("//div[@class='detailContent_category']/a")[0].text
tags = tree.xpath("//div[@class='tagBtnList']/a[@class='tagBtn2']/span")
tagString = ','.join(i.text for i in tags)
playcount = tree.xpath("//div[@class='soundContent_playcount']")[0].text
likecount = tree.xpath("//a[@class='likeBtn link1 ']/span[@class='count']")[0].text
commentcount = tree.xpath("//a[@class='commentBtn link1']/span[@class='count']")[0].text
forwardcount = tree.xpath("//a[@class='forwardBtn link1']/span[@class='count']")[0].text
mp3duration = tree.xpath("//div[@class='sound_titlebar']/div[@class='fr']/span[@class='sound_duration']")[0].text
username = tree.xpath("//div[@class='username']")[0].text
username = username.split()[0]
track_id = re.search(r'track_id="(\d+)"', html)
track_id = track_id.group(1) if track_id else None
comment_url = 'http://www.ximalaya.com/sounds/'+ track_id + '/comment_list'
#print likecount, commentcount, forwardcount, mp3duration, username, track_id, comment_url
info_sound = {}
info_sound['album_title'] = a_title
info_sound['album_url'] = a_url
info_sound['title'] = title
info_sound['music_type'] = music_type
info_sound['tags'] = tagString
info_sound['music_id'] = track_id
info_sound['playcount'] = playcount
info_sound['likecount'] = likecount
info_sound['commentcount'] = commentcount
info_sound['forwardcount'] = forwardcount
info_sound['mp3duration'] = mp3duration
info_sound['user'] = username
info_sound['url'] = s_url
#把声音信息插入数据库
self.Musicinfo_insert(info_sound)
#把生成评论url地址,交给commenlistGet处理
self.CommenlistGet(comment_url)
except Exception as e:
print '***soundpage error: %s, Album url: %s, sound url: %s' % (e, a_url, s_url)
print traceback.print_exc()
self.SdEr += 1
if self.SdEr < 3:
print 'Time sleep 15s'
time.sleep(15)
self.soundpage(a_url, a_title, s_url)
def CommenlistGet(self, url):
try:
html = urllib.urlopen(url).read()
tree = etree.HTML(html)
pages = tree.xpath("//div[@class='pagingBar_wrapper']/a/text()")
#如果存在多页评论,就提取最大页数, 循环各页加入队列
if pages:
pages =[ int(i) for i in pages if i.isdigit()] #判断是数字,只保留数字
max_page = max(pages)
for i in xrange(1, max_page+1):
comment_url = url + '?page=%s' % i
#如果数据存在评论url地址,就不再把评论url地址加入队列处理
com_count = self.CommentInfo_find(comment_url)
if not com_count:
self.queue.put(comment_url)
#print 'Queue size is: %s' % self.queue.qsize()
#print 'Comment url %s put in queue' % comment_url
else:
#pass
print 'Comment already in posts database, url: %s' % comment_url
else:
#如果数据存在评论url地址,就不再把评论url地址加入队列处理
com_count = self.CommentInfo_find(url)
if not com_count:
self.queue.put(url)
#print 'Queue size is: %s' % self.queue.qsize()
#print 'Comment url %s put in queue' % url
else:
pass
#print 'Comment already in posts database, url: %s' % url
except Exception as e:
print '***CommenlistGet get %s error, error: ' % (url, e)
print traceback.print_exc()
self.ClgEr += 1
if self.ClgEr < 3:
time.sleep(15)
self.CommenlistGet(url)
def Musicinfo_insert(self, infoData):
music_id = self.musicInfo.insert(infoData)
return music_id
def Musicinfo_find(self, url):
count = self.musicInfo.find_one({"url": url})
return count
def CommentInfo_find(self, url):
comCount = self.commentInfo.find_one({"url": url})
return comCount
class CommentDown(threading.Thread):
def __init__(self, queue, queue_in):
threading.Thread.__init__(self)
self.queue = queue
self.queue_in = queue_in
self.client = MongoClient()
self.db = self.client.test
self.PgEr = 0
def run(self):
while not exit_flag.is_set():
flag = self.queue.qsize()
#print 'flag is : %s' %flag
if flag < 30:
print 'Queue size < 30, Time sleep 60s.'
time.sleep(60)
url = self.queue.get()
time.sleep(random.uniform(1,3))
self.postpage(url)
sys.stdout.flush()
self.queue.task_done()
print '*** Comment done, url: %s ***, Queue: %s, Queue_In: %s, Page: %s' % (url, self.queue.qsize(), self.queue_in.qsize(), page)
def postpage(self, post_url):
try:
html = urllib.urlopen(post_url).read()
tree = etree.HTML(html)
contents = tree.xpath('//div[@class="right"]')
music_id = re.search(r'sounds/(\d+)/comment_list', post_url)
music_id = music_id.group(1) if music_id else None
for content in contents:
user = content.xpath("div/a")[0].text
mark = content.xpath("div/span")[0].text
comment_list = content.xpath(".//div[@class='comment_content']/text()")
comment_txt = comment_list[0] if comment_list else None
reply_time = content.xpath(".//span[@class='comment_createtime']/text()")[0]
user = user.encode('raw_unicode_escape').strip()
mark = mark.encode('raw_unicode_escape').strip()
comment_txt = comment_txt.encode('raw_unicode_escape').strip() if comment_txt else None
#print user
#print mark
#print comment_txt
#print reply_time
info_comment = {}
info_comment['music_id'] = music_id
info_comment['user'] = user
info_comment['mark'] = mark
info_comment['content'] = comment_txt
info_comment['reply_time'] = reply_time
info_comment['url'] = post_url
self.Post_insert(info_comment)
except Exception as e:
print '***postpage get %s error, error: %s' % (post_url, e)
print traceback.print_exc()
self.PgEr += 1
if self.PgEr < 5:
print 'time sleep 15s.'
time.sleep(15)
self.postpage(post_url)
def Post_insert(self, postdata):
Post_data = self.db.bookcomment
post_id = Post_data.insert(postdata)
return post_id
#把每一页的各专辑地址放入queue_in队列
def pageGetAlbums(url):
try:
html = urllib.urlopen(url).read()
tree = etree.HTML(html)
album_urls = tree.xpath("//div[@class='albumfaceOutter']/a/@href")
if album_urls:
for album_url in album_urls:
# 'Album url is: ', album_url
global queue_in
global queue
queue_in.put(album_url)
print 'Queue_in: %s, Queue: %s, Page: %s' % (queue_in.qsize(), queue.qsize(), page)
except Exception as e:
print '****pageGetAlbums %s get error, error: %s' % (url, e)
print traceback.print_exc()
global PgEr
PgEr += 1
if PgEr < 5:
print 'time sleep 15s'
time.sleep(15)
pageGetAlbums(url)
if __name__ == '__main__':
exit_flag = threading.Event()
exit_flag.clear()
for i in range(3):
xi = Ximalaya(queue, queue_in)
xi.start()
for i in range(10):
downer = CommentDown(queue, queue_in)
downer.start()
url_host = 'http://www.ximalaya.com/dq/music/'
#对热门页面分析后,把每一页的各专辑地址放入queue_in队列
html = urllib.urlopen(url_host).read()
tree = etree.HTML(html)
pages = tree.xpath("//div[@class='pagingBar_wrapper']/a/text()")
pages =[ int(i) for i in pages if i.isdigit()] #判断是数字,只保留数字
max_page = max(pages)
for page in xrange(1, max_page+1):
print 'Page No: %s' % page
url = '%s%s' % (url_host, page)
pageGetAlbums(url)
queue_in.join()
queue.join()
exit_flag.set()
print 'All downloaded!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!'