你是否已经冲入了大数据的浩瀚海洋,然后在里面跌宕起伏,遇坑无数?你是否被一堆API,接口,命令,文档而折磨?初入大数据不禁让我们感叹一声,这玩意儿不好搞啊!
今天我就来介绍一个可以让我们十五分钟就能使用分布式列式数据库HBase的工具:Phoenix。这真的不是我标题党,绝非十五分钟从入门到跑路,从跑路到删库。
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs来创建表,插入数据和对HBase数据进行查询。
注:Hive和Impala也可以对HBase进行查询,但是Phoenix在HBase上的性能远超他们,对于简单查询来说,Phoenix的性能量级是毫秒,对于百万级别的行数来说,性能量级是秒
Phoenix为啥这么厉害,见标题:Phoenix,Put the SQL back in NoSQL。这里的NoSQL特指HBase。啥意思呢,就是Phoenix又把sql语句放回HBase里面了。我们知道HBase不支持SQL语句,我们想去操作HBase的时候要么通过HBase的shell要么通过通过他提供的Java API等等。而Phoenix可以让我们通过我们非常熟悉的SQL语句对HBase进行操作,同时提供标准的JDBC API可以让我们通过编程来使用HBase。JDBC我们不能再熟悉了,有了他我们就可以像操作mysql数据库一样来操作HBase,这个门槛不是低了一点半点啊。而且还可以将Phoenix和mybatis相结合更加方便快捷的开发我们的业务。Phoenix更加厉害的是它本身具有很多的特性,比如完整的事务,二级索引,高性能等等,我们后续会逐个介绍。这篇文章我们主要介绍一下Phoenix的安装和基本使用。
Phoenix安装
下载Phoenix的安装包,比如我的HBase版本为1.2.4,所以我这里选择HBase1.2的Phoenix,大家这里要注意与你部署的HBase版本一致。HBase伪分布式集群搭建大家可以参考我的另外一篇手记《HBase伪分布式集群安装》。
下载完成之后我们将其解压:
cd phoenix_download_dir # 跳转到下载目录
tar zxvf phoenix_tar_gz # 解压缩
mv phoenix_dir dest_path # 移动到我们想要安装的位置

Phoenix的安装非常之简单,我们只需要将相关的jar包拷贝到hbase的classpath(即HBASE_HOME/lib目录下)即可。
我们需要拷贝phoenix-[version]-HBase-1.2-server.jar和phoenix-core-[version]-HBase-1.2.jar
cp phoenix-4.13.1-HBase-1.2-server.jar HBASE_HOME/lib/
cp phoenix-core-4.13.1-HBase-1.2.jar HBASE_HOME/lib/
我们列出一下HBase的lib目录下关于Phoenix的jar包。

好,我们的Phoenix已经安装完成了,接下来我们重新启动我们的hbase就可以了。
cd HBASE_HOME/bin # 跳转到HBase的执行目录
./start-hbase.sh
./start-hbase.sh
使用Phoenix
我们安装完Phoenix之后应该如何来使用它呢?我们先来看一下官方的示例。
批处理方式
首先我们新建一个名为us_population.sql的文件:
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
然后新建一个csv类型的数据文件us_population.csv:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
然后我们再添加一下我们查询所需要的sql语句,新建一个us_population_queries.sql文件,我们进行了查询,聚合等常见是SQL操作:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
最后我们通过./psql.py来测试一下Phoenix:
# 为你zookeeper的地址,我这是添加的是127.0.0.1:2181
./psql.py us_population.sql us_population.csv us_population_queries.sql
大家可以看到相关的执行结果:
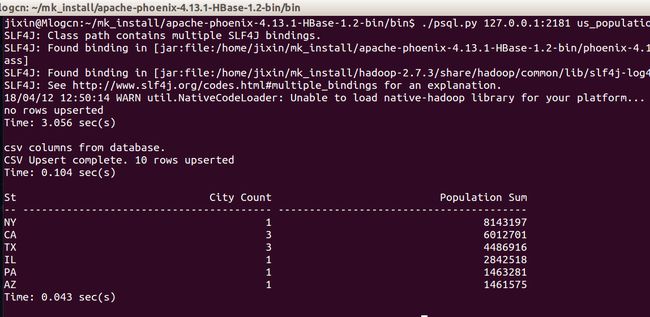
我的天啊!这么神奇吗?我写了一条sql,还有聚合操作在HBase上居然执行成功了?
命令行方式
我们先来看一下我们平常是如何使用HBase的。我们想通过命令行的方式使用HBase的话,首先要调用它的shell。
cd HBASE_HOME/bin
./hbase shell
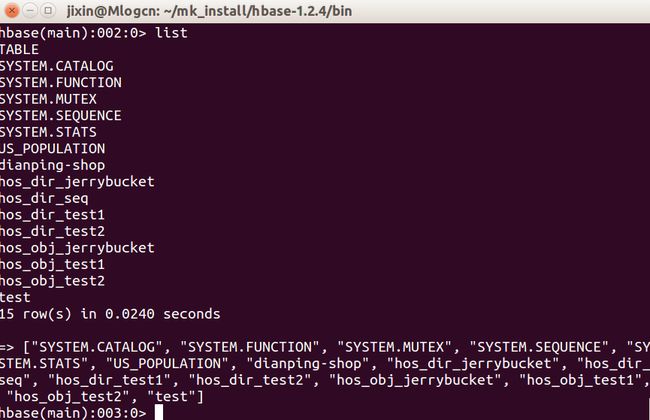
我们可以输入help来查看相关的命令介绍。常用命令会在文末给出。首先我们执行list查看hbase中所有的表。然后获取刚刚我们创建的表US_POPULATION的数据。
list
scan 'US_POPULATION'
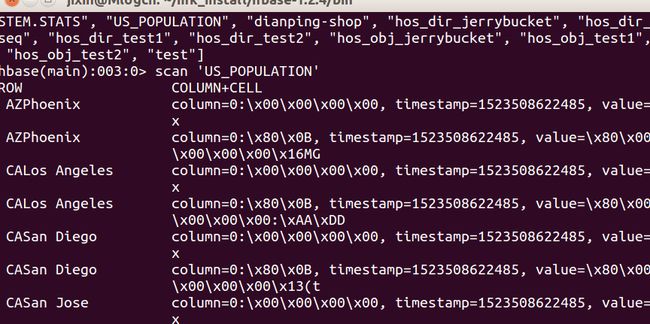
如果我们对HBase不熟悉的话直接操作HBase的shell还是有一定的难度的,我们这里只是展示了最简单的命令,还有查询,过滤等等,当你用到的时候你会感觉很崩溃。那么我们怎么使用SQL去检索我们需要的数据呢?
这里我们就用到了Phoenix的命令行方式,我们调用Phoenix安装目录bin文件夹下的sqlline.py
./sqlline.py
Phoenix也有一些特殊的命令,这部分命令需要前面加上感叹号!来执行,我们会在文末介绍。我们同样的来查看一下我们的表,然后查询一下数据。
!tables # 查看所有的表
select * from US_POPULATION; # 检索数据
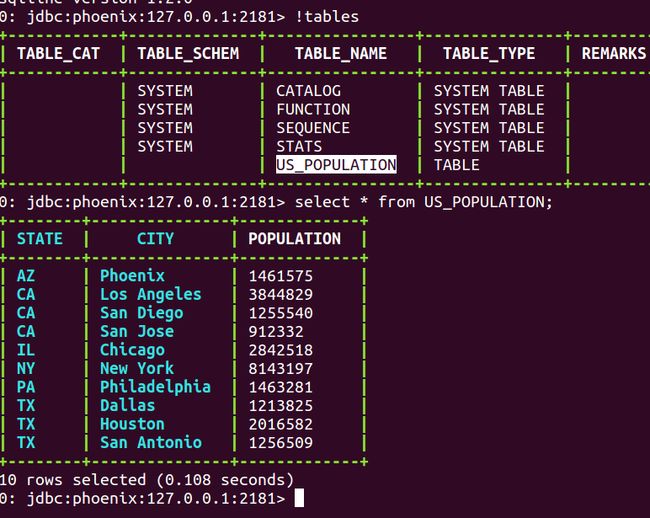
看到SQL是不是倍感亲切,在这里,你可以使用sql对HBase里面的数据进行一系列的操作,常用的检索,过滤,聚合等等都可以支持。想不想立即部署一个Phoenix来试一下呢?
关于HBase和Phoenix更多信息大家可以观看我的实战课程《HBase+SpringBoot实战分布式文件存储》,里面有HBase的详细介绍和Phoenix的使用方式,包括命令行和Java JDBC调用,还有将Phoenix和Mybatis结合起来应用的实例。
附录:
HBase基础命令:
# HBase shell中的帮助命令非常强大,使用help获得全部命令的列表,使用help ‘command_name’获得某一个命令的详细信息
help 'status'
# 查询服务器状态
status
# 查看所有表
list
# 创建一个表
create 'FileTable','fileInfo','saveInfo'
# 获得表的描述
describe 'FileTable'
# 添加一个列族
alter 'FileTable', 'cf'
# 删除一个列族
alter 'FileTable', {NAME => 'cf', METHOD => 'delete'}
# 插入数据
put 'FileTable', 'rowkey1','fileInfo:name','file1.txt'
put 'FileTable', 'rowkey1','fileInfo:type','txt'
put 'FileTable', 'rowkey1','fileInfo:size','1024'
put 'FileTable', 'rowkey1','saveInfo:path','/home'
put 'FileTable', 'rowkey1','saveInfo:creator','tom'
put 'FileTable', 'rowkey2','fileInfo:name','file2.jpg'
put 'FileTable', 'rowkey2','fileInfo:type','jpg'
put 'FileTable', 'rowkey2','fileInfo:size','2048'
put 'FileTable', 'rowkey2','saveInfo:path','/home/pic'
put 'FileTable', 'rowkey2','saveInfo:creator','jerry'
# 查询表中有多少行
count 'FileTable'
# 获取一个rowkey的所有数据
get 'FileTable', 'rowkey1'
# 获得一个id,一个列簇(一个列)中的所有数据
get 'FileTable', 'rowkey1', 'fileInfo'
# 查询整表数据
scan 'FileTable'
# 扫描整个列簇
scan 'FileTable', {COLUMN=>'fileInfo'}
# 指定扫描其中的某个列
scan 'FileTable', {COLUMNS=> 'fileInfo:name'}
# 除了列(COLUMNS)修饰词外,HBase还支持Limit(限制查询结果行数),STARTROW(ROWKEY起始行。会先根据这个key定位到region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和FILTER(按条件过滤行)等。比如我们从RowKey1这个rowkey开始,找下一个行的最新版本
scan 'FileTable', { STARTROW => 'rowkey1', LIMIT=>1, VERSIONS=>1}
# Filter是一个非常强大的修饰词,可以设定一系列条件来进行过滤。比如我们要限制名称为file1.txt
scan 'FileTable', FILTER=>"ValueFilter(=,'name:file1.txt’)"
# FILTER中支持多个过滤条件通过括号、AND和OR的条件组合
scan 'FileTable', FILTER=>"ColumnPrefixFilter('typ') AND ValueFilter ValueFilter(=,'substring:10')"
# 通过delete命令,我们可以删除某个字段,接下来的get就无结果
delete 'FileTable','rowkey1','fileInfo:size'
get 'FileTable','rowkey1','fileInfo:size'
# 删除整行的值
deleteall 'FileTable','rowkey1'
get 'FileTable',’rowkey1'
# 通过enable和disable来启用/禁用这个表,相应的可以通过is_enabled和is_disabled来检查表是否被禁用
is_enabled 'FileTable'
is_disabled 'FileTable'
# 使用exists来检查表是否存在
exists 'FileTable'
# 删除表需要先将表disable
disable 'FileTable'
drop 'FileTable'
Phoenix基础命令:
!help # 帮助,不知道怎么办就执行help就对了
!list # 列出正常的链接
!tables # 列出所有的表
!dbinfo # 列出数据库的信息
!describe # 列出表的描述
!quit # 退出命令行
Phoenix我们就简单介绍到这里了,这个真的是一个非常厉害的项目。大家对大数据有兴趣的话就关注一下吧。
希望对大家有所帮助~~~