kmer计算简介
kmer计算类似字符串的移动窗口取值一样,主要在map端进行切分,在reduce进行整合相加即可
实现方法
1.用hadoop实现
2.用sparkJAVA实现
3.用scala实现
- hadoop实现
//KmerCountMapper.java
public class KmerCountMapper extends Mapper {
private final static IntWritable ONE =new IntWritable(1);
private int k ;
private final Text kmerkey = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
this.k = conf.getInt("k.mer",3);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String sequence = value.toString();
for (int i = 0; i < sequence.length()-k+1; i++) {
//在getKmer中进行subString()
String kmer=KmerUtil.getKmer(sequence,i,k);
kmerkey.set(kmer);
context.write(kmerkey,ONE);
}
}
}
//KmerCountReduce.java
public class KmerCountReduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum=0;
for(IntWritable value:values){
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
//KmerCountDriver驱动端类
public class KmerCountDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, KmerCountDriver.class.getSimpleName());
job.setJarByClass(KmerCountDriver.class);
job.setJobName("KmerCountDriver");
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(KmerCountMapper.class);
job.setReducerClass(KmerCountReduce.class);
Path inputDirectory = new Path(args[0]);
Path outputDirectory = new Path(args[1]);
FileInputFormat.setInputPaths(job,inputDirectory);
FileOutputFormat.setOutputPath(job,outputDirectory);
job.getConfiguration().setInt("k.mer",Integer.parseInt(args[2]));
boolean status = job.waitForCompletion(true);
return status?0:1;
}
public static void main(String[] args) throws Exception {
if (args.length!=3){
throw new IllegalArgumentException("args is error format");
}
int returnStatus = ToolRunner.run(new KmerCountDriver(),args);
System.exit(returnStatus);
}
- 在hadoop上的运行脚本
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export APP_JAR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/shell/jar/bigdata-1.0-SNAPSHOT.jar
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
export INPUT=/chap17/input
export OUTPUT=/chap17/output
$HADOOP_HOME/bin/hadoop jar $APP_JAR hadoop.chaper17.KmerCountDriver $INPUT $OUTPUT 3
-
输出结果
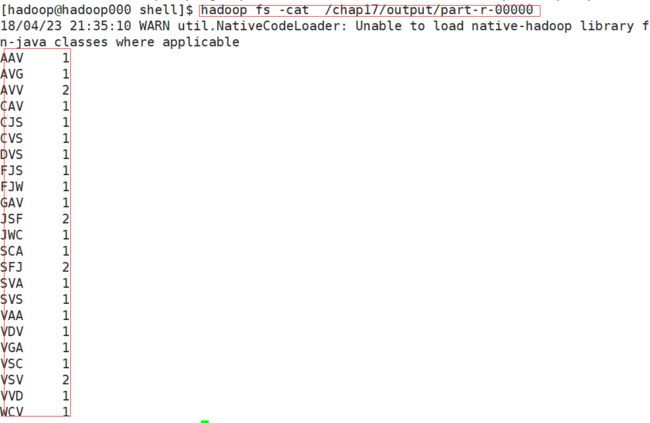 image.png
image.png
- 在sparkJava上实现的代码
public class chaper17 {
public static void main(String[] args) {
if(args.length <3){
System.err.print("Usage:args error");
System.exit(1);
}
final String fastqFilename =args[0];
final int K= Integer.parseInt(args[1]);
final int N = Integer.parseInt(args[2]);
SparkConf conf = new SparkConf().setAppName("chaper17");
JavaSparkContext sc = new JavaSparkContext(conf);
final Broadcast broadcastK = sc.broadcast(K);
final Broadcast broadcastN = sc.broadcast(N);
//rdd的分区数 = max(本地file的分片数, sc.defaultMinPartitions)
JavaRDD records = sc.textFile(fastqFilename,1);
//对RDD中的元素进行过滤操作
JavaRDD filteredRDD = records.filter(new Function() {
@Override
public Boolean call(String record) throws Exception {
String firstChar = record.substring(0, 1);
if (firstChar.equals("@") || firstChar.equals("+") || firstChar.equals(";") ||
firstChar.equals("!") || firstChar.equals("~")) {
return false;
} else {
return true;
}
}
});
JavaPairRDD kmers = filteredRDD.flatMapToPair(new PairFlatMapFunction() {
@Override
public Iterator> call(String str) throws Exception {
int k = broadcastK.getValue();
List> list = new ArrayList<>();
for (int i = 0; i < str.length() - k + 1; i++) {
String kmer = str.substring(i, i + k);
list.add(new Tuple2(kmer, 1));
}
return list.iterator();
}
});
JavaPairRDD kmersGrouped = kmers.reduceByKey(new Function2() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
JavaRDD> partitions = kmersGrouped.mapPartitions(new FlatMapFunction>, SortedMap>() {
@Override
public Iterator> call(Iterator> iter) throws Exception {
int n = broadcastN.getValue();
SortedMap topN = new TreeMap<>();
//对于iter的要先判断迭代关系
while (iter.hasNext()) {
Tuple2 tuple = iter.next();
String kmer = tuple._1;
int frequeny = tuple._2;
topN.put(frequeny,kmer);
if (topN.size() > n) {
topN.remove(topN.firstKey());
}
}
return Collections.singletonList(topN).iterator();
}
});
SortedMap finaltopN = new TreeMap<>();
List> allTopN = partitions.collect();
for (SortedMap localTopN:allTopN){
for (Map.Entry entry:localTopN.entrySet()){
finaltopN.put(entry.getKey(),entry.getValue());
if(finaltopN.size()>10){
finaltopN.remove(finaltopN.firstKey());
}
}
}
List frequencies = new ArrayList<>(finaltopN.keySet());
List> list =new ArrayList<>();
for(int i=frequencies.size()-1;i>=0;i--){
list.add(new Tuple2(frequencies.get(i),finaltopN.get(frequencies.get(i))));
}
JavaPairRDD result = sc.parallelizePairs(list);
result.saveAsTextFile("hdfs://10.23.12.84:8020/chaper17/");
}
}
- 运行的脚本
export SPARK_HOME=/home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0
export INPUT=chaper17.txt
export K=4
export N=5
prog=spark.chaper17
$SPARK_HOME/bin/spark-submit --class $prog --num-executors 3 --executor-memory 100m --executor-cores 3 bigdata-1.0-SNAPSHOT.jar $INPUT $K $N
运行结果

image.png
scala实现的(读取本地文件在IDEA中运行)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("chaper17").setMaster("local[2]")
val sc = new SparkContext(conf)
val k =3;
val n =5;
val records = sc.textFile("chaper17.txt")
val filteredRDD = records.filter(line=>{
!(line.startsWith("@") || line.startsWith("+") ||line.startsWith(";") ||line.startsWith("!")) || line.startsWith("~")
});
val kmers = filteredRDD.flatMap(_.sliding(k,1)).map(k =>(k,1))
val kmersGroup = kmers.reduceByKey(_+_);
//对每一个分区进行排序
val pratitions = kmersGroup.mapPartitions(_.toList.sortBy(_._2).takeRight(n).toIterator)
//对全部分区进行排序
val allTopN = pratitions.sortBy(_._2,false,1).take(n)
allTopN.foreach(println)
sc.stop()
}
}
-
运行结果
 image.png
image.png