1.MR V1 有哪些不足?
1)可扩展性差(对于变化的应付能力)
a) JobTracker内存中保存用户作业的信息
b) JobTracker使用的是粗粒度的锁
2)可靠性和可用性 差
a) JobTracker失效会影响集群中所有的运行作业,用户需手动重新提交和恢复工作流
3)对不同编程模型的支持 差
HadoopV1以MapReduce为中心的设计虽然能支持广泛的用例,但是并不适合所有大型计算,如storm,spark
2.描述Yarn执行一个任务的过程?
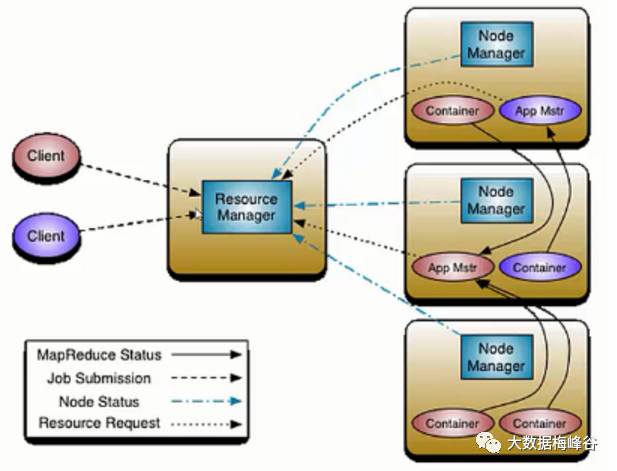
1)客户端client向ResouceManager提交Application,ResouceManager接受Application
并根据集群资源状况选取一个node来启动Application的任务调度器driver(ApplicationMaster)
2)ResouceManager找到那个node,命令其该node上的nodeManager来启动一个新的
JVM进程运行程序的driver(ApplicationMaster)部分,driver(ApplicationMaster)启动时会首先向ResourceManager注册,说明由自己来负责当前程序的运行
3)driver(ApplicationMaster)开始下载相关jar包等各种资源,基于下载的jar等信息决定向ResourceManager申请具体的资源内容。
4)ResouceManager接受到driver(ApplicationMaster)提出的申请后,会最大化的满足
资源分配请求,并发送资源的元数据信息给driver(ApplicationMaster);
5)driver(ApplicationMaster)收到发过来的资源元数据信息后会根据元数据信息发指令给具体
机器上的NodeManager,让其启动具体的container。
6)NodeManager收到driver发来的指令,启动container,container启动后必须向driver(ApplicationMaster)注册。
7)driver(ApplicationMaster)收到container的注册,开始进行任务的调度和计算,直到
任务完成。
补充:如果ResourceManager第一次没有能够满足driver(ApplicationMaster)的资源请求
,后续发现有空闲的资源,会主动向driver(ApplicationMaster)发送可用资源的元数据信息
以提供更多的资源用于当前程序的运行。
3.Yarn中的container是由谁负责销毁的,在Hadoop Mapreduce中container可以复用么?
答:ApplicationMaster负责销毁,在Hadoop Mapreduce不可以复用,在spark on yarn程序container可以复用
4.提交任务时,如何指定Spark Application的运行模式?
1)cluster模式:./spark-submit --class xx.xx.xx --master yarn --deploy-mode cluster xx.jar
- client模式:./spark-submit --class xx.xx.xx --master yarn --deploy-mode client xx.jar
5. 不启动Spark集群Master和work服务,可不可以运行Spark程序?
答:可以,只要资源管理器第三方管理就可以,如由yarn管理,spark集群不启动也可以使用spark;spark集群启动的是work和master,这个其实就是资源管理框架,yarn中的resourceManager相当于master,NodeManager相当于worker,做计算是Executor,和spark集群的work和manager可以没关系,归根接底还是JVM的运行,只要所在的JVM上安装了spark就可以。
6.Spark中的4040端口由什么功能?
答:收集Spark作业运行的信息
Hadoop:
50070:HDFS WEB UI端口
8088 : Yarn 的WEB UI 接口
Hbase:
60010:Hbase的master的WEB UI端口
60030:Hbase的regionServer的WEB UI 管理端口
Hive:
9083 : metastore服务默认监听端口
10000:Hive 的JDBC端口
Spark:
7077 : spark 的master与worker进行通讯的端口 standalone集群提交Application的端口
8080 : master的WEB UI端口 资源调度
8081 : worker的WEB UI 端口 资源调度
4040 : Driver的WEB UI 端口 任务调度
18080:Spark History Server的WEB UI 端口
7.spark on yarn Cluster 模式下,ApplicationMaster和driver是在同一个进程么?
答:是,driver 位于ApplicationMaster进程中。该进程负责申请资源,还负责监控程序、资源的动态情况。
8.如何使用命令查看application运行的日志信息
答:yarn logs -applicationId
9.Spark on Yarn 模式有哪些优点?
1)与其他计算框架共享集群资源(eg.Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce分到的内存资源会很少,效率低下);资源按需分配,进而提高集群资源利用等。
2)相较于Spark自带的Standalone模式,Yarn的资源分配更加细致
3)Application部署简化,例如Spark,Storm等多种框架的应用由客户端提交后,由Yarn负责资源的管理和调度,利用Container作为资源隔离的单位,以它为单位去使用内存,cpu等。
4)Yarn通过队列的方式,管理同时运行在Yarn集群中的多个服务,可根据不同类型的应用程序负载情况,调整对应的资源使用量,实现资源弹性管理。
10.谈谈你对container的理解?
1)Container作为资源分配和调度的基本单位,其中封装了的资源如内存,CPU,磁盘,网络带宽等。 目前yarn仅仅封装内存和CPU
2)Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
- Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令.
11.运行在yarn中Application有几种类型的container?
1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
12.Spark on Yarn架构是怎么样的?(要会画哦,这个图)
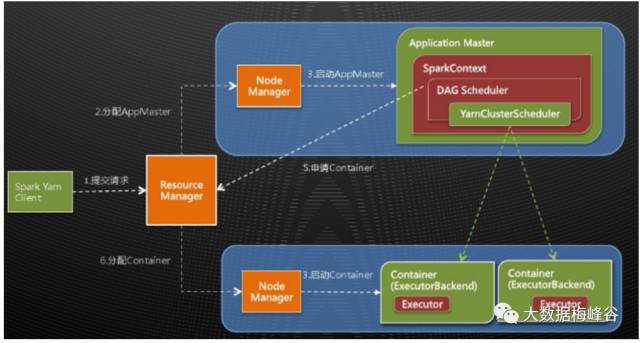
Yarn提到的App Master可以理解为Spark中Standalone模式中的driver。Container中运行着Executor,在Executor中以多线程并行的方式运行Task。运行过程和第二题相似。
13.Executor启动时,资源通过哪几个参数指定?
1)num-executors是executor的数量
2)executor-memory 是每个executor使用的内存
3)executor-cores 是每个executor分配的CPU
14.为什么会产生yarn,解决了什么问题,有什么优势?
1)为什么产生yarn,针对MRV1的各种缺陷提出来的资源管理框架
2)解决了什么问题,有什么优势,参考这篇博文:http://www.aboutyun.com/forum.php?mod=viewthread&tid=6785
15.Mapreduce的执行过程?
阶段1:input/map/partition/sort/spill
阶段2:mapper端merge
阶段3:reducer端merge/reduce/output
详细过程参考这个http://www.cnblogs.com/hipercomer/p/4516581.html
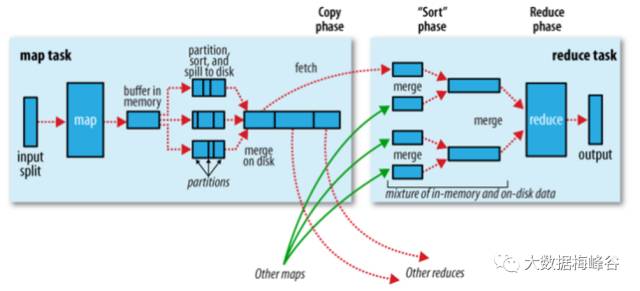
16.一个task的map数量由谁来决定?
每个输入分片(input split)针对一个map任务。
FileInputFormat 按照文件分割split,如果输入的目录中有100个小文件,则划分后的split个数至少为100个。
如果一个文件有 200 M,一个 input split 的 size 是 64M,那么就会物理切分成 4 个 split。
所以 map 数量 由两方面决定:
-
很多小于 input split size 的文件 被计算成一个 input split。
如果有一堆 小文件,就会产生 一堆 map task,会产生以下影响:- 消耗NameNode大量的内存
- 延长MapReduce作业的总运行时间
Hadoop 提供了 CombineFileInputFormat 来解决这种情况:来把小文件进行合并成一个大文件,可以通过自定义 或者 使用 Hadoop提供的类 的方式来实现:
- 自定义一个类,继承 CombineFileInputFormat,并实现 createRecordReader 方法(还需要自定义一个类继承自 RecordReader... )
- 使用内置实现的两个类,选择一个:CombineTextInputFormat 、CombineSequenceFileInputFormat
使用方法:
job.setInputFormatClass(CombineTextInputFormat.class); -
大于 input split size 的文件,由 input spit size 决定 input split 的个数。
所以 针对一个大文件:split size 影响 map 的数量。下面看下 split size 由什么决定:InputSplitSize = Math.max(minSize, Math.min(maxSize, blockSize) minSize = mapred.min.split.size(可在 mapred-site.xml 设置,默认为1B) maxSize = mapred.max.split.size(可在 mapred-site.xml 设置,默认为 Long.MAX_VALUE)由上面的公式看出,可通过设置 minSize、maxSize 来决定 InputSplitSize 的大小。
一个task 的 reduce 数量,由 partition 决定。
17.reduce后输出的数据量有多大?(重点!!!)
并不是想知道确切的数据量有多大这个,而是想问你,MR的执行机制,开发完程序,有没有认真评估程序运行效率
1)用于处理redcue任务的资源情况,如果是MRV1的话,分了多少资源给map,多少个reduce
如果是MRV2的话,可以提一下,集群有分了多少内存、CPU给yarn做计算 。
2)结合实际应用场景回答,输入数据有多大,大约多少条记录,做了哪些逻辑操作,输出的时候有多少条记录,执行了多久,reduce执行时候的数据有没有倾斜等
3)再提一下,针对mapReduce做了哪几点优化,速度提升了多久,列举1,2个优化点就可以
18.你的项目提交到job的时候数据量有多大?(重点!!!)
答:1)回答出数据是什么格式,有没有采用什么压缩,采用了压缩的话,压缩比大概是多少;2)文件大概多大:大概起了多少个map,起了多少个reduce,map阶段读取了多少数据,reduce阶段读取了多少数据,程序大约执行了多久,3)集群什么规模,集群有多少节点,多少内存,多少CPU核数等。把这些点回答进去,而不是给个数字了事。
19.你们提交的job任务大概有多少个?这些job执行完大概用多少时间?
还是考察你开发完程序有没有认真观察过程序的运行,有没有评估程序运行的效率
20.你们业务数据量多大?有多少行数据?
这个也是看你们有没有实际的经验,对于没有实战的同学,请把回答的侧重点放在MR的运行机制上面,
MR运行效率方面,以及如何优化MR程序(看别人的优化demo,然后在虚拟机上拿demo做一下测试)。
22.如何杀死一个正在运行的job
杀死一个job
MRV1:Hadoop job kill jobid
YARN: yarn application -kill applicationId
23.列出你所知道的调度器,说明其工作原理
a) Fifo schedular 默认的调度器 先进先出
b) Capacity schedular 计算能力调度器 选择占用内存小 优先级高的
c) Fair schedular 公平调度器 所有job 占用相同资源
24.YarnClient模式下,执行Spark SQL报这个错,Exception in thread "Thread-2" java.lang.OutOfMemoryError: PermGen space,但是在Yarn Cluster模式下正常运行,可能是什么原因?
1)原因查询过程中调用的是Hive的获取元数据信息、SQL解析,并且使用Cglib等进行序列化反序列化,中间可能产生较多的class文件,导致JVM中的持久代使用较多
Cluster模式的持久代默认大小是64M,Client模式的持久代默认大小是32M,而Driver端进行SQL处理时,其持久代的使用可能会达到90M,导致OOM溢出,任务失败。
yarn-cluster模式下出现,yarn-client模式运行时倒是正常的,原来在$SPARK_HOME/bin/spark-class文件中已经设置了持久代大小:
JAVA_OPTS="-XX:MaxPermSize=256m $OUR_JAVA_OPTS"
2)解决方法:在Spark的conf目录中的spark-defaults.conf里,增加对Driver的JVM配置,因为Driver才负责SQL的解析和元数据获取。配置如下:
spark.driver.extraJavaOptions -XX:PermSize=128M -XX:MaxPermSize=256M
25.spark.driver.extraJavaOptions这个参数是什么意思,你们生产环境配了多少?
传递给executors的JVM选项字符串。例如GC设置或者其它日志设置。注意,在这个选项中设置Spark属性或者堆大小是不合法的。Spark属性需要用SparkConf对象或者spark-submit脚本用到的spark-defaults.conf文件设置。堆内存可以通过spark.executor.memory设置
26.导致Executor产生FULL gc 的原因,可能导致什么问题?
答:可能导致Executor僵死问题,海量数据的shuffle和数据倾斜等都可能导致full gc。以shuffle为例,伴随着大量的Shuffle写操作,JVM的新生代不断GC,Eden Space写满了就往Survivor Space写,同时超过一定大小的数据会直接写到老生代,当新生代写满了之后,也会把老的数据搞到老生代,如果老生代空间不足了,就触发FULL GC,还是空间不够,那就OOM错误了,此时线程被Blocked,导致整个Executor处理数据的进程被卡住
28.Spark执行任务时出现java.lang.OutOfMemoryError: GC overhead limit exceeded和java.lang.OutOfMemoryError: java heap space原因和解决方法?
答:原因:加载了太多资源到内存,本地的性能也不好,gc时间消耗的较多
解决方法:
1)增加参数,-XX:-UseGCOverheadLimit,关闭这个特性,同时增加heap大小,-Xmx1024m
2)下面这个两个参数调大点
export SPARK_EXECUTOR_MEMORY=6000M
export SPARK_DRIVER_MEMORY=7000M
可以参考这个:http://www.cnblogs.com/hucn/p/3572384.html