Java中字符串的操作可谓是最常见的操作了,String这个类它封装了有关字符串操作的大部分方法,从构建一个字符串对象到对字符串的各种操作都封装在该类中,本篇我们通过阅读String类的源码来深入理解下这些字符串操作背后的原理。主要内容如下:
- 繁杂的构造器
- 属性状态的常用函数
- 获取内部数值的常用函数
- 比较大小的相关函数
- 局部操作等常用函数
一、繁杂的构造器
在学会操作字符串之前,我们应先了解下构造一个字符串对象的方式有几种。先看第一种构造器:
private final char value[];
public String() {
this.value = "".value;
}
String源码中第一个私有域就是value这个字符数组,该数组被声明为final表示一旦初始化就不能被改变。也就是说一个字符串对象实际上是由一个字符数组组成的,并且该数组一旦被初始化则不能更改。这也很好的解释了String对象的一个特性:不可变性。一经赋值则不能改变。而我们第一种构造器就很简单,该构造器会将当前的string对象赋值为空(非null)。
接下来的几种构造器都很简单,实际上都是操作了value这个数组,但都不是直接操作,因为它不可更改,所以一般都是复制到局部来实现的各种操作。
//1
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//2
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
//3
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
无论是第一种的传入一个String类型,还是第二种的直接传入char数组的方式,都是转换为为当前将要创建的对象中value数组属性赋值。至于第三种方法,对传入的char数组有要求,它要求从该数组索引位置为offset开始的后count个字符组成新的数组作为参数传入。该方法首先做了几个极端的判断并增设了对应的异常抛出,核心方法是Arrays.copyOfRange这个方法,它才是真正实现字符数组拷贝的方法。
该方法传入三个参数,形参value,起始位置索引,终止位置索引。在该方法中主要做了两件事情,第一,通过起始位置和终止位置得到新数组的长度,第二,调用本地函数完成数组拷贝。
System.arraycopy(original, from, copy, 0,Math.min(original.length - from, newLength));
虽然该方法是本地方法,但是我们大致可以猜出他是如何实现的,无非是通过while或者for循环遍历前者赋值后者。我们看个例子:
public static void main(String[] args){
char[] chs = new char[]{'w','a','l','k','e','r'};
String s = new String(chs,0,3);
System.out.println(s);
}
输出结果:wal
可以看见这是一种[ a,b)形式,也就是说索引包括起始位置,但不包括终止位置,所以上例中只截取了索引为0,1,2并没有包括3,这种形式的截取方式在String的其他函数中也是常见的。
以上介绍的构建String对象的方式中,基本都是属于操作它内部的字符数组来实现的,下面的几种构造器则是通过操作字节数组来实现对字符串对象的构建,当然这些操作会涉及到编码的问题。下面我们看第一个有关字节数组的构造器:
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
该方法首先保证charsetName不为null,然后调用checkBounds方法判断offset、length是否小于0,以及offset+length是否大于bytes.length。然后调用一个核心的方法用于将字节数组按照指定的编码方式解析成char数组,我们可以看看这个方法:
static char[] decode(String charsetName, byte[] ba, int off, int len)
throws UnsupportedEncodingException
{
StringDecoder sd = deref(decoder);
String csn = (charsetName == null) ? "ISO-8859-1" : charsetName;
if ((sd == null) || !(csn.equals(sd.requestedCharsetName())
|| csn.equals(sd.charsetName()))) {
sd = null;
try {
Charset cs = lookupCharset(csn);
if (cs != null)
sd = new StringDecoder(cs, csn);
} catch (IllegalCharsetNameException x) {}
if (sd == null)
throw new UnsupportedEncodingException(csn);
set(decoder, sd);
}
return sd.decode(ba, off, len);
}
首先通过deref方法获取对本地解码器类的一个引用,接着使用三目表达式获取指定的编码标准,如果未指定编码标准则默认为 ISO-8859-1,然后紧接着的判断主要是:如果未能从本地线程相关类中获取到StringDecoder,或者与指定的编码标准不符,则手动创建一个StringDecoder实例对象。最后调用一个decode方法完成译码的工作。相比于该方法,我们更常用以下这个方法来将一个字节数组转换成char数组。
public String(byte bytes[], String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
只指定一个字节数组和一个编码标准即可,当然内部调用的还是我们上述的那个构造器。当然也可以不指定任何编码标准,那么则会使用默认的编码标准:UTF-8
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
当然还可以更简洁:
public String(byte bytes[]) {
this(bytes, 0, bytes.length);
}
但是一般用于转换字节数组成字符串的构造器还是使用由字节数组和编码标准组成的两个参数的构造器。
以上为String类中大部分构造器的源代码,有些源码和底层操作系统等方面知识相关联,理解不深,见谅。下面我们看看有关String类的其他一些有关操作。
二、属性状态的常用函数
该分类的几个函数还是相对而言较为简单的,主要有以下几个函数:
//返回字符串的长度
public int length() {
return value.length;
}
//判断字符串是否为空
public boolean isEmpty() {
return value.length == 0;
}
//获取字符串中指定位置的单个字符
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
有关字符串属性的函数大致就这么些,相对而言比较简单,下面看看获取内部数值的常用函数。
三、获取内部数值的常用函数
此分类下的函数主要有两大类,一个是返回的字符数组,一个是返回的字节数组。我们首先看返回字符数组的方法。
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
if (srcBegin < 0) {
throw new StringIndexOutOfBoundsException(srcBegin);
}
if (srcEnd > value.length) {
throw new StringIndexOutOfBoundsException(srcEnd);
}
if (srcBegin > srcEnd) {
throw new StringIndexOutOfBoundsException(srcEnd - srcBegin);
}
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
}
该函数用于将当前String对象中value字符数组的起始索引位置srcBegin到终止索引位置srcEnd拷贝到目标数组dst中,其中dst数组的起始位置为dstBegin索引处。看个例子:
public static void main(String[] args){
String str = "hello-walker";
char[] chs = new char[6];
str.getChars(0,5,chs,1);
for(int a=0;a结果如下:
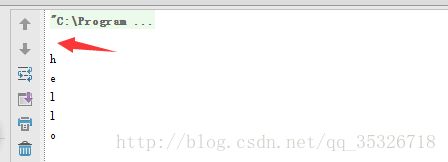
我们指定从str 的[0,5)共五个字符组成一个数组,从chs数组索引为1开始,一个个复制到chs里。有关获取获取字符数组的函数就这么一个,下面我们看看获取字节数组的函数。
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
}
这个函数的核心方法,StringCoding.encode和上述的StringCoding.decode很相似,只不过一个提供编码标准是为了解码成字符串对象,而另一个则是提供编码标准为了将字符串编码成字节数组。有关getBytes还有一些重载,但这些重载基本每个都会调用我们上述列出的这个方法,只是他们省略了一些参数(使用他们的默认值)。
四、判等函数
在我们日常的项目中可能经常会遇到equls这个函数,那么这个函数是否又是和符号 == 具有相同的功能呢?下面我们看看判等函数:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
我们看到该方法中,第一个判断就使用了符号 == ,实际上等于符号判断的是:两个对象是否指向同一内存空间地址(当然如果他们是指向同一内存的,他们内部封装的数值自然也是相等的)。 从上述代码中我们可以看出,这个equals方法,首先判断两个对象是否指向同一内存位置,如果是则返回true,如果不是才判断他们内部封装的数组是否是相等的。
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)
&& (anotherString.value.length == value.length)
&& regionMatches(true, 0, anotherString, 0, value.length);
}
该方法是忽略大小写的判等方法,核心方法是regionMatches:
public boolean regionMatches(boolean ignoreCase, int toffset,
String other, int ooffset, int len) {
char ta[] = value;
int to = toffset;
char pa[] = other.value;
int po = ooffset;
if ((ooffset < 0) || (toffset < 0)
|| (toffset > (long)value.length - len)
|| (ooffset > (long)other.value.length - len)) {
return false;
}
while (len-- > 0) {
char c1 = ta[to++];
char c2 = pa[po++];
if (c1 == c2) {
continue;
}
if (ignoreCase) {
char u1 = Character.toUpperCase(c1);
char u2 = Character.toUpperCase(c2);
if (u1 == u2) {
continue;
}
if (Character.toLowerCase(u1) == Character.toLowerCase(u2)) {
continue;
}
}
return false;
}
return true;
}
首先是检错判断,简单判断下传入的参数是否小于0等,然后通过不断读取两个字符数组的字符比较是否相等,如果相等则直接跳过余下代码进入下次循环,否则分别将这两个字符转换为小写和大写两种形式进行比较,如果相等,依然返回true。equals方法只能判断两者是否相等,但是对于谁大谁小则无能为力。 下面我们看看compare相关方法,它可以表两者大小。
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
该方法将根据字典顺序,判断出两者大小,代码比较简单,不再赘述。忽略大小写的按字典顺序排类似,主要涉及以下方法:
public int compareToIgnoreCase(String str) {
return CASE_INSENSITIVE_ORDER.compare(this, str);
}
这里的compare方法是CASE_INSENSITIVE_ORDER类的一个内部类。
为了不让文章篇幅过长,本篇暂时结束,下篇将介绍最常见的一些有关字符串操作的函数源码,总结的不好,望海涵!