本文结构:
- CNN
- 建立模型
- code
昨天只是用了简单的 softmax 做数字识别,准确率为 92%,这个太低了,今天用 CNN 来提高一下准确率。
关于 CNN,可以看这篇:
图解何为CNN
简单看一个典型的 Deep CNN 由若干组 Convolution-ReLU-Pooling 层组成。

这三层可以提取出有用的 pattern,但它们并不知道这些 pattern 是什么。
所以接着是 Fully Connected 层,它可以对数据进行分类。
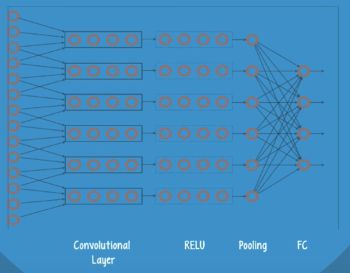

在 CNN 中有几个重要的概念:
- stride
- padding
- pooling
stride,就是每跨多少步抽取信息。每一块抽取一部分信息,长宽就缩减,但是厚度增加。抽取的各个小块儿,再把它们合并起来,就变成一个压缩后的立方体。
padding,抽取的方式有两种,一种是抽取后的长和宽缩减,另一种是抽取后的长和宽和原来的一样。
pooling,就是当跨步比较大的时候,它会漏掉一些重要的信息,为了解决这样的问题,就加上一层叫pooling,事先把这些必要的信息存储起来,然后再变成压缩后的层:
即 Pooling 层是用来降维的。
经过 convolution 和 ReLU 的作用后,会有越来越复杂的形式,所以Pooling 层负责提取出最重要的 pattern,进而提高时间空间的效率。
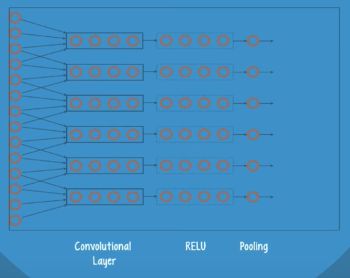
patch,就是小方块的长宽的像素,in size 是image的厚度为1,out size是输出的厚度为32:

模型
主要就是建立 2 组 convolution-pooling 层,全连接层,加 dropout 减小过拟合,得到预测值 y_conv:
- 每一层建立 weight 和 bias,
- 和上一层的输出值经过 conv2d 作用后,应用 ReLu 激活函数,
- 再做 pooling 后得到的输出值传递给下一层
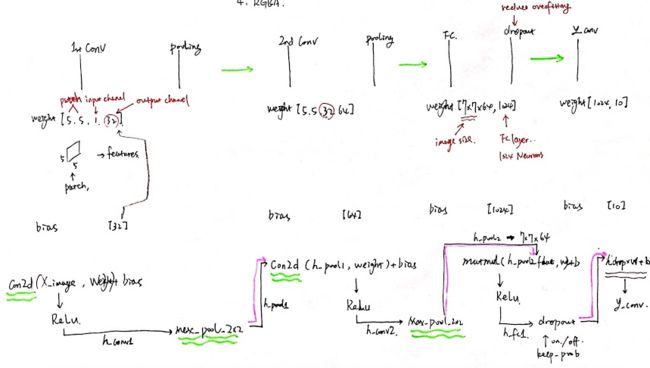
code 和注释:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
# 产生随机变量,符合 normal 分布
# 传递 shape 就可以返回weight和bias的变量
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 定义2维的 convolutional 图层
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
# strides 就是跨多大步抽取信息
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 定义 pooling 图层
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
# 用pooling对付跨步大丢失信息问题
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784]) # 784=28x28
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 28, 28, 1]) # 最后一个1表示数据是黑白的
# print(x_image.shape) # [n_samples, 28,28,1]
## 1. conv1 layer ##
# 把x_image的厚度1加厚变成了32
W_conv1 = weight_variable([5, 5, 1, 32]) # patch 5x5, in size 1, out size 32
b_conv1 = bias_variable([32])
# 构建第一个convolutional层,外面再加一个非线性化的处理relu
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28x28x32
# 经过pooling后,长宽缩小为14x14
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32
## 2. conv2 layer ##
# 把厚度32加厚变成了64
W_conv2 = weight_variable([5,5, 32, 64]) # patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
# 构建第二个convolutional层
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14x14x64
# 经过pooling后,长宽缩小为7x7
h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64
## 3. func1 layer ##
# 飞的更高变成1024
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64]
# 把pooling后的结果变平
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## 4. func2 layer ##
# 最后一层,输入1024,输出size 10,用 softmax 计算概率进行分类的处理
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
# important step
sess.run(tf.initialize_all_variables())
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images, mnist.test.labels))
学习资料:
https://www.tensorflow.org/get_started/mnist/pros
推荐阅读 历史技术博文链接汇总
http://www.jianshu.com/p/28f02bb59fe5
也许可以找到你想要的