MySQL的查询,优化,事务,锁
几类数据是不适合在数据库中存放的
1.二进制多媒体数据
数据库空间资源消耗严重
存储很消耗数据库主机的CPU资源
2.流水队列数据
数据库为了保证事务的安全性以及可恢复性,需要记录所有变更的日志信息。
流水队列数据的用途决定了存放这种数据的表中的数据会被不断的INSERT,UPDATE, DELETE,而每一个操作都要生成与之对应的日志信息。
可以使用第三方队列软件实现对Queue数据的处理能力,性能将会提升。
3.超大文本数据
5.0.3之前,VARCHAR类型数据最长能够存放255个字节,如果需要存储更长的文本数据到一个字段,必须使用TEXT类型(最大存放64KB),甚至是LONGTEXT类型(最大4GB)。
5.0.3开始,VARCHAR类型的最大程度调整到了64KB,当实际数据小于255Byte的时候,实际存储空间和实际数据长度一样,但是一旦超过了255Byte之后,占用的存储空间是实际数据长度的2倍。
使用Cache的时候大概考虑两个方面
数据的变更频率
数据的访问概率
比如:
1.系统各种配置及规则数据
变动频率非常低,访问概率很高
2.活跃用户的基本信息数据
很少有系统的活跃用户能够达到其用户总量的级别
也很少有用户会频繁修改自己的基本信息
但是,用户的基本信息在应用系统中访问的概率频繁
3.准实时数据
基于时间断统计数据不会实时更新,很少需要增量更新
关于优化
书中举了个栗子:
实现每个用户查看各自相册(假设每个列表显示10张照片)
能够在相片名称后面显示该相片的留言数量。
方法1:
SELECT id, subject, url FROM photo WHERE user_id = ? LIMIT 10
通过第一步结果集中的10个相片id循环运行10次:
SELECT COUNT(*) FROM photo_comment WHERE photo_id = ?
方法2:
第一步一样,查询出10个
SELECT photo_id, COUNT(*) FROM photo_comment WHERE photo_id IN (?) GROUP BY photo_id
其比较通过以下几个条件
解析等的SQL语句数目:
每次提交SQL不管是相同还是不同,都需要进行完全解析,主要的消耗资源是数据库主机的CPU。
网络资源消耗:
网络资源交互,执行了11条SQL语句,所以会产生11次网络交互。结合上一部分知道,通过线程连接模块联系到数据库主机上。
数据库IO操作
IO操作在数据库系统中是非常昂贵的资源,尤其是当功能的PV较大的时候。
结果集处理次数和结果集大小
应用数据处理的数据拼接
上述2个方案,第二种方案的SQL效率要比第一种方案要好。
关于Cache的使用
1.Cache系统的不合理利用会导致Cache命中低下,导致数据库访问量的增加
2.对可扩展性的过度追求,对象拆的过于离散造成大量的JOIN语句,而MySQL的主要优势在于处理简单逻辑查询
3.对数据库的过度依赖
将大量更适合存放于文件系统中的数据存入数据库中,造成了数据库资源的浪费,影响总体性能
4.过渡理想化系统的用户体验
大量非核心业务消耗过多的资源
数据库中的事务和锁:
MySQL使用了是3种锁类型(级别)的锁定机制:
行级锁定:
锁定对象的粒度极小
由于锁定粒度小,发生资源争用的概率也是最小
能带来大的并发处理能力,提高一些高并发应用系统的性能
弊端
由于粒度小,获取锁和释放锁要做的事情也就更多,带来的消耗也就更大。
行级锁也最容易产生死锁。
InnoDB和NDB Cluster存储引擎
表级锁定:
最大粒度的锁定机制
实现简单,带来的系统负面影响最小,获取锁和释放锁的速度很快。
可以很好的避免死锁问题
弊端
出现锁定资源争用概率比较高
并发程度不好
主要是一些非事务性的存储引擎:MyISAM,Memory,CSV
页级锁定:
锁定粒度介于行级锁定和表级锁定
资源开销和并发处理能力也介于二者之间
主要是
随着锁定资源粒度的减小,锁定相同数据量数据所消耗的内存数量会越多,实现算法也会越复杂。遇到锁等待的可能性也就越低,并发的程度越高。
关于表级锁定
分为两种类型:一种是读锁定,一种是写锁定。
主要通过四个队列来维护来那种锁定:
//当前只有读写锁的所有线程相关信息都可以在这两个中找到
Current read -lock queue
Current write-lock queue
//正在等待的锁定资源信息存放在下面两个中
Pending read-lock queue
Pending write-lock queue
分别为当前正在锁定中的读和写的锁定信息,等待读和写的锁定信息。
队列中的信息按照获取锁的时间依次存放。
MySQl内部定义实现了11中锁定类型,有系统中一个枚举变量thr_lock_type定义:
IGNORE发生锁请求的时候内部交互使用,锁定结构和队列中并不会有任何信息存储
UNLOCK释放锁定请求的锁类型
READ读锁定
WRITE写锁定
READ_WITH_SHARED_LOCKS在innodb中使用,select ... lock in share mode
READ_HIGH_PRIORITY高优先级锁定
READ_NO_INSERT不允许Concurent Insert的锁定
Concurent Insert允许一边读,一边插入
WRITE_ALLOW_WRITE当存储引擎自行处理锁定的时候,MySQL可以允许其他线程获取读或者写锁定。
WRITE_ALLOW_READ对表做DDL的时候,MySQL允许其他线程获取读锁定。重建表之后再RENAME而实现该功能,所以整个过程任然可以提供读服务。
WRITE_CONCURRENT_INSERT正在进行Concurrent_insert时候使用的锁定方式,除了READ_NO_INSERT之外其他任何读锁定都不会被阻塞。
WRITE_DELAYED在使用INSERT_DELAYED时候的锁定类型。
INSERT_DELAYED,当一个客户端使用INSERT_DELAYED的时候,会立刻从服务器获得一个确定。并且被排入队列,当表没有被其他线程使用的时候,此行被插入。
WRITE_LOW_PRIORITY显示声明的低级别锁定方式。
WRITE_ONLY锁定异常中断后系统进行CLOSE TABLE操作。
读锁定:
申请获取读锁定资源的时候需要满足两个条件:主要检查请求资源的写锁定和是否有等待
1.请求资源当前没有被写锁定
2.写锁定等待队列中没有更高优先级的写锁定等待
如果满足两个条件,请求会被立即通过。相关信息存入Current read-lock quenu 中,如果没有一个条件满足,被迫进入等待队列Pending read-lock queue中等待释放。
写锁定:
检查顺序:
Current write-lock queue //如果没有,进Pending
Pending write-lock queue //如果没有,进Current read-lock queue,如果锁定存在,进Pending等待
Current read-lock queue
特殊情况:
请求锁的类型为WRITE_DELAYED
请求锁的类型为WRITE_CONCURRENT_INSERT或者是TL_WRITE_ALLOW_WRITE,同时Current read lock是READ_NO_INSERT (READ_NO_INSERT在这种情况下会被阻塞)
这两种情况下,写锁定直接进Current write-lock queue
读写请求队列中的写锁请求的优先级规则:
除了READ_HIGH_PRIORITY的读锁定之外,Pending write-lock queue中的WRITE写锁定能够阻塞所有其他读锁定。
READ_HIGH_PRORITY读锁定能够阻塞所有的Pending write-lock queue中的写锁定。
除了WRITE写锁定之外,Pending write-lock queue中其他的任何写锁定都比读锁定的优先级的。
写锁定出现在Current write-lock queue之后,会阻塞除了以下情况的所有锁定请求:
某些引擎下,可以允许WRITE_CONCURRENT_INSERT 写锁定请求
写锁定为WRITE_ALLOW_WRITE,允许除了WRITE_ONLY之外所有读和写的所有请求
WRITE_ALLOW_READ的时候,允许READ_NO_INSERT之外的所有读锁定请求
WRITE_DELAYED的时候,允许除了READ_NO_INSERT之外所有的读锁定请求。
WRITE_CONCURRENT_INSERT的时候,允许除了READ_NO_INSERT以外的所有读锁定请求。
行级锁定并不是MySQL自己实现的锁定方式,而是有其他存储引擎自己实现的。
InnoDB
innoDB和Oracle的数据库有不少的相似的地方。
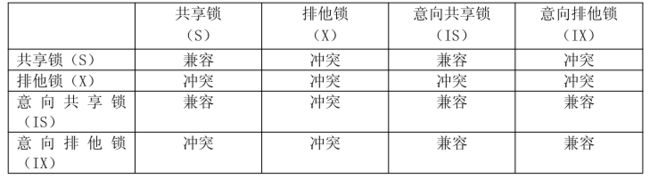
InnoDB的行级锁分为两类,共享锁 排它锁
锁定机制中为了让行级别锁定和表级别锁定共存,使用了意向锁,有了意向共享锁和意向排它锁
意向锁的作用是放一个事务在需要获取资源锁定的时候,如果遇到所需资源被排它锁占用之后,可以在锁定行的表之上添加一个合适的意向锁。
意向共享锁可以有多个,意向排它锁只可以有一个。
对比Oracle
Oracle 的锁定数据是通过锁定某行所在记录的物理Block上的事务槽上加表级锁定信息。
InnoDB通过数据的第一个索引键之前和最后一个索引键之后的空余空间上表级锁定信息。
Innodb锁定的实现成为间隙锁。Query执行范围查找的话,会锁定范围内所有的索引键值,即是键值并不存在。而这些不存在的键值会导致无法插入。
InnoDB 各事务隔离级别下锁定:
Read Uncommited
Read commited
Repeatable Read
Serializable
InnoDB 发生死锁后,会判断发生死锁的事务各自更改数据量判断事务的大小,回滚记录最少的!
如果涉及到多个存储引擎的话,Innodb没办法检测死锁,这种情况下只能使用超时限制来解决死锁。
下一篇将Query的查询优化!