
1.k近邻法(k-nearest neighbor,k-NN)
-
k近邻算法是一个基本分类和回归方法,k-NN的输入时实例的特征向量,对应于特征空间的点,输出是实力的类别,可以取多类。k-NN不具有显式的学习过程,k-NN实际上利用训练数据集对特征向量空间进行划分,并且作为其分类的“模型”。

-
k-NN简单直观:给定一个训练集,对新的输入实力,在训练数据集中找到与该实例最近邻的k个实例,这k个实例的多数所属于的类别就作为新实例的类。

输入:训练数据集T=(x1,y1),(x2,y2),...(xN,yN)
输出:实例x所属的类y
算法步骤:
(1)根据给定的距离度量,在训练集T中找出与x最近邻的k个点,涵盖这k个点的x的邻域记作Nk(x)
(2)在Nk(x)中根据分类决策规则,如多数表决决定x的类别y。当k==1的时候,称为最近邻算法,对于输入的实例点,x,最近邻法将训练数据集中与x最近的点的所属类别作为x的类。
2.k近邻模型
- k-NN使用的模型实际上对应于听特征空间的划分,模型由三个基本要素:距离度量,k值的选择,分类决策规则。k近邻模型的核心就是使用一种距离度量,获得距离目标点最近的k个点,根据分类决策规则,决定目标点的分类。
2.1距离度量
- 特征空间中,两个实例点的距离是两个实例点的相似程度的反映。k-NN模型的特征空间一般是n维实数向量空间,使用的距离是欧氏距离,但也可以是其他距离,比如更一般的Lp距离(Lp distance)或者Minkowski距离。
-
一个点和一个点之间的距离,无论是什么计算方式,基本上离不开Lp距离。欧式距离,则是L2范式,也就是p=2的情况,而另一个很熟悉的距离曼哈顿距离,则是L1范式。Lp距离的定义如下:

- 当然,如果p→∞的时候,就叫做切比雪夫距离了。
除了这个闵可夫斯基距离集合外,还有另外的距离评估体系,例如马氏距离、巴氏距离、汉明距离,这些都是和概率论中的统计学度量标准相关。而像夹角余弦、杰卡德相似系数、皮尔逊系数等都是和相似度有关的。 - 因此,简单说来,各种“距离”的应用场景简单概括为,空间:欧氏距离,路径:曼哈顿距离,国际象棋国王:切比雪夫距离,以上三种的统一形式:闵可夫斯基距离,加权:标准化欧氏距离,排除量纲和依存:马氏距离,向量差距:夹角余弦,编码差别:汉明距离,集合近似度:杰卡德类似系数与距离,相关:相关系数与相关距离。
-
这其实只是个度量标准而已,应当根据数据特征选择相应的度量标准。
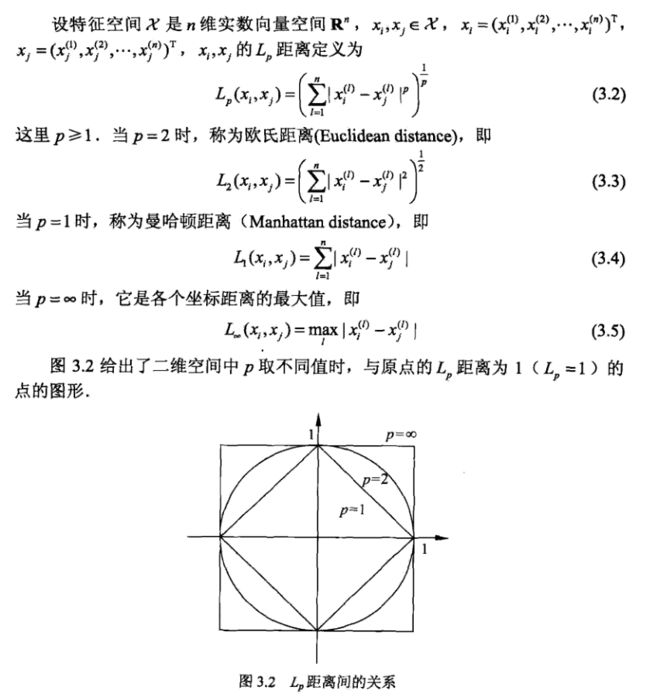
- 由不同的距离度量所确定的邻近点是不同的。
2.2 k值的选择
近似误差、估计误差(知乎解释)
- 选取比较小的k值(较复杂的模型),近似误差(approximation error)会减小,而估计误差(estimation error)会增大,如果选择的k值较小,就相当于用较小的的邻域中的训练实例进行预测。此时预测的结果会对近邻的实例点非常敏感,因为影响分类的都是比较近的样本,但一旦出现噪点,预测就会出错。
选取比较大的k值(较简单的模型),相反,减小噪点的影响,但是较远或不相似的样本也会对结果有影响,就相当于在较大的邻域中训练实例进行预测。此时,与输入实例较远的训练实例也会对预测起作用,使预测发生错误。极限情况下k=N,考虑所有样本,极简模型 。 - 在应用中,k值一般选取一个比较小的数值,通常采用交叉验证法来选取最优的k值。
2.3分类决策规则
- 大多情况是多数表决,即由输入实例的k个近邻中的多数类决定x的类别。也可以采用别的分类决策规则。
01损失函数(CSDN)

3.k近邻算法的实现
- 实现k-NN算法,主要考虑的问题是如何对训练集进行快速k近邻搜索。
- 简单实现方式:线性搜索,对于数据量很大时,此方法是不可行的。所以考虑更好的方法
- 采用特殊结构来存储训练集,以减小计算距离的次数,比如kd树方法。
3.1简单实现
- 文件数据
hei,wei,tag
1.5,40,thin
1.5,50,fat
1.5,60,fat
1.6,40,thin
1.6,50,thin
1.6,60,fat
1.6,70,fat
1.7,50,thin
1.7,60,thin
1.7,70,fat
1.7,80,fat
1.8,60,thin
1.8,70,thin
1.8,80,fat
1.8,90,fat
1.9,80,thin
1.9,90,fat
- knn.py
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 8 17:21:14 2017
@author: jasonhaven
"""
import os
import numpy as np
import pandas as pd
import operator
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
def read_from_csv(file):
'''
file:文件绝对地址
功能:读入csv文件并解析出数据集和标签集
'''
pwd=os.getcwd()
os.chdir(os.path.dirname(file))
df=pd.read_csv('data.csv')
os.chdir(pwd)
datas=df.iloc[:,:2].astype(np.float).values
labels = df.iloc[0:,-1:].astype(np.str).values#加载类别标签部分
return datas,labels
def classify(instance,datas,labels,k):
'''
instance:新的实例特征向量
datas:训练数据集
labels:标签集
k:选择相邻的k个实例
'''
num=datas.shape[0]
#tile(A, reps)返回一个shape=reps的矩阵,矩阵的每个元素是A
diffMat = np.tile(instance, (num, 1)) - datas
#diffMat就是输入样本与每个训练样本的差值
square_diffMat = diffMat**2
#然后对其每个x和y的差值进行平方运算。
square_distances=square_diffMat.sum(axis=1)
#开平方根求出距离
distances=square_distances**0.5
#argsort函数返回的是关键字(数组值)从小到大的索引值
sorted_distances = distances.argsort()
class_count = {}
# 投票过程,就是统计前k个最近的样本所属类别包含的样本个数
for i in range(k):
# sortedDistIndicies[i]是第i个最相近的样本下标
voteIlabel = str(labels[sorted_distances[i]])
# 然后将票数增1
class_count[voteIlabel] = class_count.get(voteIlabel, 0) + 1
# 把分类结果进行排序,然后返回得票数最多的分类结果
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
def draw(datas,labels):
plt.figure('KNN')
plt.title('KNN')
plt.xlabel('height')
plt.ylabel('weight')
green_patch=mpatches.Patch(color='green', label='thin')
red_patch=mpatches.Patch(color='red', label='fat')
handles=[red_patch,green_patch]
plt.legend(handles=handles)
for i,x in enumerate(datas):
if labels[i]=='thin':
plt.scatter(x[0],x[1],s=100,marker='.',c='g')
else:
plt.scatter(x[0],x[1],s=100,marker='x',c='r')
plt.show()
if __name__=='__main__':
#获取数据集
file='./data.csv'#data.csv : 身高,体重,标签
datas,labels=read_from_csv(file)
labels=list(labels)
#新实例
instance=[1.7,60]
k=2
#分类
label=classify(instance,datas,labels,k)
draw(datas,labels)
print("knn classify : %s's label is %s"%(str(instance),label))
3.2运行结果

- 后续进行优化处理
作者:Jasonhaven.D
链接:http://www.jianshu.com/u/ed031e432b82
來源:
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。