一、防止路径穿越
在挖掘ruckus服务器的漏洞过程中,首先就是想要登陆进去。所以要找一个路径穿越的漏洞,想到了可以用../../../或者是URL编码后的%2e%2e%2f%2e%2e%2f%2e%2e%2f,进而读取密码文件,但是实践证明不行。比如supportinfo.txt是/www下的一个文件,用来存储路由器的log。
如果存在路径穿越,则GET /images/../../../../../../../../../../../supportinfo.txt应该读取不到文件,但最后还是能读到supportinfo.txt。说明将../以某种方式限制在了/www目录。
ruckus使用的是GoAhead2.1.8,让我们看看其源码做了哪些处理吧。
在这之前可以看看历史漏洞:
https://www.exploit-db.com/exploits/21707
https://www.exploit-db.com/exploits/20607
int websDefaultHandler(webs_t wp, char_t *urlPrefix, char_t *webDir, int arg,
char_t *url, char_t *path, char_t *query)
{
websStatType sbuf;
char_t *lpath, *tmp, *date;
int bytes, flags, nchars;
flags = websGetRequestFlags(wp);
// 此处处理传入路径 websValidateUrl,对其中的../和其他一些情况作了处理
if (websValidateUrl(wp, path) < 0)
{
/*
* preventing a cross-site scripting exploit -- you may restore the
* following line of code to revert to the original behavior...
*/
/*websError(wp, 500, T("Invalid URL %s"), url);*/
websError(wp, 500, T("Invalid URL"));
return 1;
}
lpath = websGetRequestLpath(wp);
nchars = gstrlen(lpath) - 1;
if (lpath[nchars] == '/' || lpath[nchars] == '\\') {
lpath[nchars] = '\0';
}
//。。。。
}
int websValidateUrl(webs_t wp, char_t *path)
{
/*
Thanks to Dhanwa T ([email protected]) for this fix -- previously,
if an URL was requested having more than (the hardcoded) 64 parts,
the webServer would experience a hard crash as it attempted to
write past the end of the array 'parts'.
*/
#define kMaxUrlParts 64 // 此处是防止溢出,当./././././层级太多时,这个用来矫正URL的函数反而会出现溢出,为什么和层级有关请看下面。https://www.exploit-db.com/exploits/21707
char_t *parts[kMaxUrlParts]; /* Array of ptr's to URL parts *///用来存储路径的每一层的字符串。
char_t *token, *dir, *lpath;
int i, len, npart;
a_assert(websValid(wp));
a_assert(path);
dir = websGetRequestDir(wp);
if (dir == NULL || *dir == '\0') {
return -1;
}
/*
* Copy the string so we don't destroy the original
*/
path = bstrdup(B_L, path);
websDecodeUrl(path, path, gstrlen(path));
//初始化 层数以及第一层的指针
len = npart = 0;
parts[0] = NULL;
/*
* 22 Jul 02 -- there were reports that a directory traversal exploit was
* possible in the WebServer running under Windows if directory paths
* outside the server's specified root web were given by URL-encoding the
* backslash character, like:
*
* GoAhead is vulnerable to a directory traversal bug. A request such as
*
* GoAhead-server/../../../../../../../ results in an error message
* 'Cannot open URL'.
* However, by encoding the '/' character, it is possible to break out of
* the
* web root and read arbitrary files from the server.
* Hence a request like:
*
* GoAhead-server/..%5C..%5C..%5C..%5C..%5C..%5C/winnt/win.ini returns the
* contents of the win.ini file.
* (Note that the description uses forward slashes (0x2F), but the example
* uses backslashes (0x5C). In my tests, forward slashes are correctly
* trapped, but backslashes are not. The code below substitutes forward
* slashes for backslashes before attempting to validate that there are no
* unauthorized paths being accessed.
*/
token = gstrchr(path, '\\');
while (token != NULL)
{
*token = '/';
token = gstrchr(token, '\\');//把\替换成/,在windows平台会出现这个问题,参考链接https://www.exploit-db.com/exploits/20607
}
token = gstrtok(path, T("/"));
/*
* Look at each directory segment and process "." and ".." segments
* Don't allow the browser to pop outside the root web.
*/
// 下面这个循环是处理的核心,函数把url按/解析成一层一层的,存储每一层名称的是char_t *parts[kMaxUrlParts];
//如果是../就把当前层数index往上移动,路径中永远不会包含../,也就解决了路径穿越的问题
while (token != NULL)
{
if (npart >= kMaxUrlParts)// 判断是否达到了最大层,防止溢出
{
/*
* malformed URL -- too many parts for us to process.
*/
bfree(B_L, path);
return -1;
}
if (gstrcmp(token, T("..")) == 0) // 判断该层是不是..,如果是就把定位层数的npart--
{
if (npart > 0)
{
npart--;
}
}
else if (gstrcmp(token, T(".")) != 0) //如果不是.,就层数+1,将该层存储
{
parts[npart] = token;
len += gstrlen(token) + 1;
npart++;//
}
token = gstrtok(NULL, T("/"));
}
#ifdef WIN32
if (isBadWindowsPath(parts, npart))
{
bfree(B_L, path);
return -1;
}
#endif
/*
* Create local path for document. Need extra space all "/" and null.
*/
if (npart || (gstrcmp(path, T("/")) == 0) || (path[0] == '\0'))
{
lpath = balloc(B_L, (gstrlen(dir) + 1 + len + 1) * sizeof(char_t));
gstrcpy(lpath, dir);
for (i = 0; i < npart; i++)
{
gstrcat(lpath, T("/"));
gstrcat(lpath, parts[i]);
}
websSetRequestLpath(wp, lpath);
bfree(B_L, path);
bfree(B_L, lpath);
}
else
{
bfree(B_L, path);
return -1;
}
return 0;
}
在多次尝试过后,没法读取在/www外的文件。
虽然如此但还是发现了信息泄露的漏洞,ruckus路由器请求路径以/images/开头可以任意读取/www中的文件,其中supportinfo.txt包含了各种调试信息,(但supportinfo.txt必须在登陆调用相关功能后生成,如果目标曾经使用了这个功能就可以读取到相关内容),可造成信息泄露,比如ps信息,版本信息等。
关于路径穿越比较经典的例子有tp-link的:
https://sec-consult.com/fxdata/seccons/prod/temedia/advisories_txt/20150410-0_TP-Link_Unauthenticated_local_file_disclosure_vulnerability_v10.txt
可以直接读取到密码。
二、溢出漏洞
其中GoAhead历史漏洞就有:
https://www.exploit-db.com/exploits/21707
以redirect为例,当你访问目标机器当前不允许访问的页面时会把你重定向到登陆页面。但是其中重定向host是由你发的包的host头决定的,如果你发的越长,返回的也就越长,如果没有准备足够的空间就会造成溢出.
这么说比较模糊,可以看d-link的溢出漏洞,CVE-2018-11013,相关文章:
https://0x3f97.github.io/exploit/2018/05/13/D-Link-DIR-816-A2-CN-router-stack-based-buffer-overflow/
GoAhead
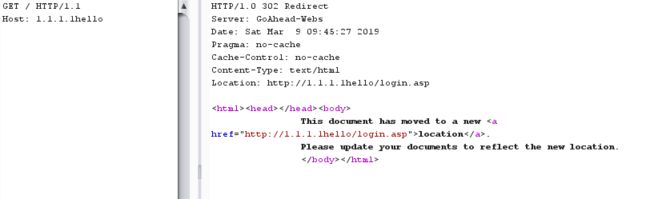
这里从代码分析。
static int websHomePageHandler(webs_t wp, char_t *urlPrefix, char_t *webDir,
int arg, char_t *url, char_t *path, char_t *query)
{
/*
* If the empty or "/" URL is invoked, redirect default URLs to the home page
*/
if (*url == '\0' || gstrcmp(url, T("/")) == 0) {
websRedirect(wp, T("home.asp"));
return 1;
}
return 0;
}
void websRedirect(webs_t wp, char_t *url)
{
char_t *msgbuf, *urlbuf, *redirectFmt;
a_assert(websValid(wp));
a_assert(url);
websStats.redirects++;
msgbuf = urlbuf = NULL;
/*
* Some browsers require a http://host qualified URL for redirection
*/
if (gstrstr(url, T("http://")) == NULL) {
if (*url == '/') {
url++;
}
redirectFmt = T("http://%s/%s");
#ifdef WEBS_SSL_SUPPORT
if (wp->flags & WEBS_SECURE) {
redirectFmt = T("https://%s/%s");
}
#endif
fmtAlloc(&urlbuf, WEBS_MAX_URL + 80, redirectFmt,
websGetVar(wp, T("HTTP_HOST"), websHostUrl), url);
url = urlbuf;
}
/*
* Add human readable message for completeness. Should not be required.
*/
fmtAlloc(&msgbuf, WEBS_MAX_URL + 80,
T("\r\n\
This document has moved to a new location.\r\n\
Please update your documents to reflect the new location.\r\n\
\r\n"
), url);
websResponse(wp, 302, msgbuf, url);
bfreeSafe(B_L, msgbuf);
bfreeSafe(B_L, urlbuf);
}
其中WEBS_MAX_URL,#define WEBS_MAX_URL 4096/ Maximum URL size for sanity /,尝试过超过4096,burpsuit显示done,但是没有响应包,不会崩溃。
用burpsuit测了好多其他的变量,都不能达到效果。



三、web服务对URL的“处理”
在最开始接触路由器安全的时候对URL各种请求路径还是很疑惑的,下面就结合ruckus webs二进制文件和源码分析。
IDA反汇编main函数片段,开头有一大段这些mips汇编,是不是不知道该如何分析呢:
w $a1, (dword_10000098 - 0x10000000)($v0)
jalr $t9 ; websOpenListen
nop
lw $gp, 0xB0+var_98($sp)
li $v0, 1
la $t9, websUrlHandlerDefine
la $a3, websSecurityHandler
addiu $a0, $s0, (asc_44F540+4 - 0x450000) # ""
move $a1, $zero
move $a2, $zero
jalr $t9 ; websUrlHandlerDefine
sw $v0, 0xB0+var_A0($sp)
lw $gp, 0xB0+var_98($sp)
move $a1, $zero
la $a0, _rsm_net_IF_ToBridge
la $t9, websUrlHandlerDefine
la $a3, websFormHandler
addiu $a0, (aForms - 0x440000) # "/forms"
move $a2, $zero
jalr $t9 ; websUrlHandlerDefine
sw $zero, 0xB0+var_A0($sp)
lw $gp, 0xB0+var_98($sp)
move $a1, $zero
la $a0, _rsm_net_IF_ToBridge
la $t9, websUrlHandlerDefine
la $a3, websCgiHandler
addiu $a0, (aCgiBin - 0x440000) # "/cgi-bin"
move $a2, $zero
jalr $t9 ; websUrlHandlerDefine
sw $zero, 0xB0+var_A0($sp)
lw $gp, 0xB0+var_98($sp)
move $a1, $zero
la $a0, _rsm_net_IF_ToBridge
la $t9, websUrlHandlerDefine
la $a3, supportInfoURLHandler
addiu $a0, (aSupportinfoTxt - 0x440000) # "/supportinfo.txt"
move $a2, $zero
jalr $t9 ; websUrlHandlerDefine
sw $zero, 0xB0+var_A0($sp)
lw $gp, 0xB0+var_98($sp)
好在我们可以看源码。
看initWebs():
int main(int argc, char** argv)
{
/*
* Initialize the memory allocator. Allow use of malloc and start
* with a 60K heap. For each page request approx 8KB is allocated.
* 60KB allows for several concurrent page requests. If more space
* is required, malloc will be used for the overflow.
*/
bopen(NULL, (60 * 1024), B_USE_MALLOC);
signal(SIGPIPE, SIG_IGN);
/*
* Initialize the web server
*/
if (initWebs() < 0) {// 这个是我们要关注的
return -1;
}
#ifdef WEBS_SSL_SUPPORT
websSSLOpen();
#endif
/*
* Basic event loop. SocketReady returns true when a socket is ready for
* service. SocketSelect will block until an event occurs. SocketProcess
* will actually do the servicing.
*/
while (!finished) {
if (socketReady(-1) || socketSelect(-1, 1000)) {
socketProcess(-1);
}
websCgiCleanup();
emfSchedProcess();
}
#ifdef WEBS_SSL_SUPPORT
websSSLClose();
#endif
#ifdef USER_MANAGEMENT_SUPPORT
umClose();
#endif
/*
* Close the socket module, report memory leaks and close the memory allocator
*/
websCloseServer();
socketClose();
#ifdef B_STATS
memLeaks();
#endif
bclose();
return 0;
}
static int initWebs()
{
struct hostent *hp;
struct in_addr intaddr;
char host[128], dir[128], webdir[128];
char *cp;
char_t wbuf[128];
/*
* Initialize the socket subsystem
*/
socketOpen();
#ifdef USER_MANAGEMENT_SUPPORT
/*
* Initialize the User Management database
*/
umOpen();
umRestore(T("umconfig.txt"));
#endif
/*
* Define the local Ip address, host name, default home page and the
* root web directory.
*/
if (gethostname(host, sizeof(host)) < 0) {
error(E_L, E_LOG, T("Can't get hostname"));
return -1;
}
if ((hp = gethostbyname(host)) == NULL) {
error(E_L, E_LOG, T("Can't get host address"));
return -1;
}
memcpy((char *) &intaddr, (char *) hp->h_addr_list[0],
(size_t) hp->h_length);
/*
* Set ../web as the root web. Modify this to suit your needs
*/
getcwd(dir, sizeof(dir));
if ((cp = strrchr(dir, '/'))) {
*cp = '\0';
}
sprintf(webdir, "%s/%s", dir, rootWeb);
/*
* Configure the web server options before opening the web server
*/
websSetDefaultDir(webdir);
cp = inet_ntoa(intaddr);
ascToUni(wbuf, cp, min(strlen(cp) + 1, sizeof(wbuf)));
websSetIpaddr(wbuf);
ascToUni(wbuf, host, min(strlen(host) + 1, sizeof(wbuf)));
websSetHost(wbuf);
/*
* Configure the web server options before opening the web server
*/
websSetDefaultPage(T("default.asp"));
websSetPassword(password);
/*
* Open the web server on the given port. If that port is taken, try
* the next sequential port for up to "retries" attempts.
*/
websOpenServer(port, retries);
/*
* First create the URL handlers. Note: handlers are called in sorted order
* with the longest path handler examined first. Here we define the security
* handler, forms handler and the default web page handler.
*/
websUrlHandlerDefine(T(""), NULL, 0, websSecurityHandler,
WEBS_HANDLER_FIRST);
websUrlHandlerDefine(T("/goform"), NULL, 0, websFormHandler, 0);//自定义的路径,可执行特定功能
websUrlHandlerDefine(T("/cgi-bin"), NULL, 0, websCgiHandler, 0);//执行cgi程序或脚本
websUrlHandlerDefine(T(""), NULL, 0, websDefaultHandler,
WEBS_HANDLER_LAST); //普通地请求web文件
/*
* Now define two test procedures. Replace these with your application
* relevant ASP script procedures and form functions.
*/
websAspDefine(T("aspTest"), aspTest);
websFormDefine(T("formTest"), formTest);
/*
* Create the Form handlers for the User Management pages
*/
#ifdef USER_MANAGEMENT_SUPPORT
formDefineUserMgmt();
#endif
/*
* Create a handler for the default home page
*/
websUrlHandlerDefine(T("/"), NULL, 0, websHomePageHandler, 0);
return 0;
}
解析URL路径第一层,如果是goform就用websFormHandler处理,如果是cgi-bin就用websCgiHandler处理,如果是其他,就是websDefaultHandler处理。
对于cgi,编译好源码,把直接把busybox放到/cgi-bin,然后就“命令注入”了一把。
在实际应用中,如果提取解开了固件,对于cgi程序(也有lua php等),都可以找找命令注入。
可以看到下面的源码,其实最后是起了一个程序。
/* 函数websCgiHandler中最后运行的
* Now launch the process. If not successful, do the cleanup of resources.
* If successful, the cleanup will be done after the process completes.
*/
if ((pHandle = websLaunchCgiProc(cgiPath, argp, envp, stdIn, stdOut))
== -1) {
websError(wp, 200, T("failed to spawn CGI task"));
for (ep = envp; *ep != NULL; ep++) {
bfreeSafe(B_L, *ep);
}
bfreeSafe(B_L, cgiPath);
bfreeSafe(B_L, argp);
bfreeSafe(B_L, envp);
bfreeSafe(B_L, stdOut);
} else {
/*
int websLaunchCgiProc(char_t *cgiPath, char_t **argp, char_t **envp,
char_t *stdIn, char_t *stdOut)
{
PROCESS_INFORMATION procinfo; /* Information about created proc */
DWORD dwCreateFlags;
char *fulldir;
BOOL bReturn;
int i, nLen;
/*
* Replace directory delimiters with Windows-friendly delimiters
*/
nLen = gstrlen(cgiPath);
for (i = 0; i < nLen; i++) {
if (cgiPath[i] == '/') {
cgiPath[i] = '\\';
}
}
fulldir = NULL;
dwCreateFlags = CREATE_NEW_CONSOLE;
/*
* CreateProcess returns errors sometimes, even when the process was
* started correctly. The cause is not evident. For now: we detect
* an error by checking the value of procinfo.hProcess after the call.
*/
procinfo.hThread = NULL;
bReturn = CreateProcess(//看到这里就明白了
cgiPath, /* Name of executable module */
NULL, /* Command line string */
NULL, /* Process security attributes */
NULL, /* Thread security attributes */
0, /* Handle inheritance flag */
dwCreateFlags, /* Creation flags */
NULL, /* New environment block */
NULL, /* Current directory name */
NULL, /* STARTUPINFO */
&procinfo); /* PROCESS_INFORMATION */
if (bReturn == 0) {
DWORD dw;
dw = GetLastError();
return -1;
} else {
CloseHandle(procinfo.hThread);
}
return (int) procinfo.dwProcessId;
}
除了cgi,还有一些其他的自定义的路径,都可以尝试去挖掘漏洞,如之前dlink /hnap就爆出漏洞。
https://fortiguard.com/encyclopedia/ips/40772
从这里,可以明白两点,一是可以从固件解开得出的webs程序中找到有哪些路径可以访问(找未授权访问),二是这些路径对应的函数(用来分析漏洞,完成利用)。
以上是我在挖掘ruckus漏洞时总结的一些东西,和大家分享下,大家最好结合源码自己分析,如果你也对路由器漏洞挖掘感兴趣。
原文作者:爱中华UpTTT
原文链接:https://bbs.pediy.com/thread-249922.htm
转载请注明:转自看雪学院
更多阅读:
HTTP/3 的前世今生
如何使用FastHook免root Hook微信
SandHook 第四弹,Android Q 支持 & Inline 的特别处理
炒冷饭之穿山甲的传说1