·慢查询分析:通过慢查询分析,找到有问题的命令进行优化。
·Redis Shell:功能强大的Redis Shell会有意想不到的实用功能。
·Pipeline:通过Pipeline(管道或者流水线)机制有效提高客户端性能。
·事务与Lua:制作自己的专属原子命令。
·Bitmaps:通过在字符串数据结构上使用位操作,有效节省内存,为开发提供新的思路。
·HyperLogLog:一种基于概率的新算法,难以想象地节省内存空间。
·发布订阅:基于发布订阅模式的消息通信机制。
·GEO:Redis3.2提供了基于地理位置信息的功能。
慢查询分析
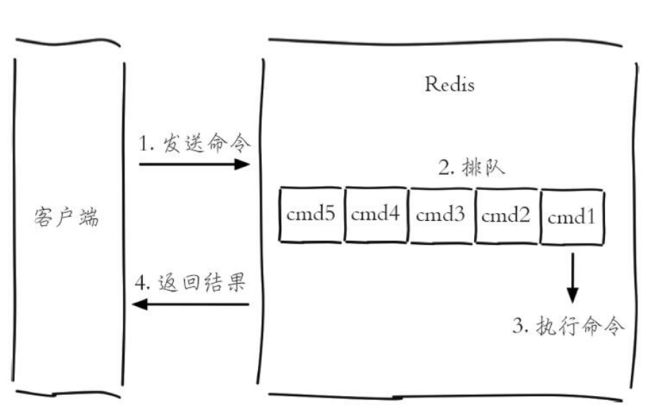 一条客户端命令的生命周期
一条客户端命令的生命周期
慢查询只统计步骤3的时间,所以没有慢查询并不代表客户端没有超时问题.
slowlog-log-slower-than 预设阀值,它的单位是微秒(1秒=1000毫秒=1000000微秒),默认值是10000
slowlog-max-len Redis使用了一个列表来存储慢查询日志,slowlog-max-len就是列表的最大长度。遵循FIFO规则
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite
## config rewrite命令重写配置文件
slowlog get [n]
## 获取慢查询日志
slowlog len
## 获取慢查询日志列表当前的长度
slowlog reset
## 慢查询日志重置,列表清理操作
慢查询日志的标识id、发生时间戳、命令耗时、执行命令和参数四个组成部分.
 慢查询日志数据结构
慢查询日志数据结构
slowlog-max-len配置建议记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上。
slowlog-log-slower-than 对于高OPS(每秒的操作数)场景的Redis建议设置为1毫秒。
防止慢查询数据丢失可以定期执行slow get命令将慢查询日志持久化到其他存储中(MySQL).
redis-cli详解
-r(repeat)选项代表将命令执行多次,例如redis-cli -r 3 ping,下面操作将会执行三次ping.
-i(interval)选项代表每隔几秒执行一次命令,但是-i选项必须和-r选项一起使用,redis-cli -r 5 -i 1 ping
redis-cli -r 100 -i 1 info | grep used_memory_human 每隔1秒输出内存的使用量,一共输出100次.
-x选项代表从标准输入(stdin)读取数据作为redis-cli的最后一个参数 $ echo "world" | redis-cli -x set hello
--slave选项是把当前客户端模拟成当前Redis节点的从节点
--rdb选项会请求Redis实例生成并发送RDB持久化文件
--pipe选项用于将命令封装成Redis通信协议定义的数据格式,批量发送给Redis执行
--bigkeys选项使用scan命令对Redis的键进行采样,从中找到内存占用比较大的键值
--eval选项用于执行指定Lua脚本
--latency 可以测试客户端到目标Redis的网络延迟 redis-cli -h {machineB} --latency
--latency-history 以分时段的形式了解延迟信息
--latency-dist 会使用统计图表的形式从控制台输出延迟统计信息。
--stat选项可以实时获取Redis的重要统计信息
--no-raw选项是要求命令的返回结果必须是原始的格式,--raw恰恰相反,返回格式化后的结果。
redis-server详解
redis-server --test-memory 1024可以用来检测当前操作系统能否稳定地分配指定容量(1G)的内存给Redis
redis-benchmark详解
-c(clients)选项代表客户端的并发数量(默认是50)。
-n(num)选项代表客户端请求总量(默认是100000)。
-q选项仅仅显示redis-benchmark的requests per second信息
redis-benchmark -c 100 -n 20000 -q
在一个空的Redis上执行了redis-benchmark会发现只有3个(counter:rand_int,mylist,key:rand_int),-r 可以向Redis插入更多随机的键。
-P选项代表每个请求pipeline的数据量(默认为1)。
-k选项代表客户端是否使用keepalive,1为使用,0为不使用,默认值为1。
-t选项可以对指定命令进行基准测试。
--csv选项会将结果按照csv格式输出,便于后续处理,如导出到Excel等。
Pipeline概念
Pipeline(流水线)机制能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端
redis-cli的--pipe选项实际上就是使用Pipeline机制
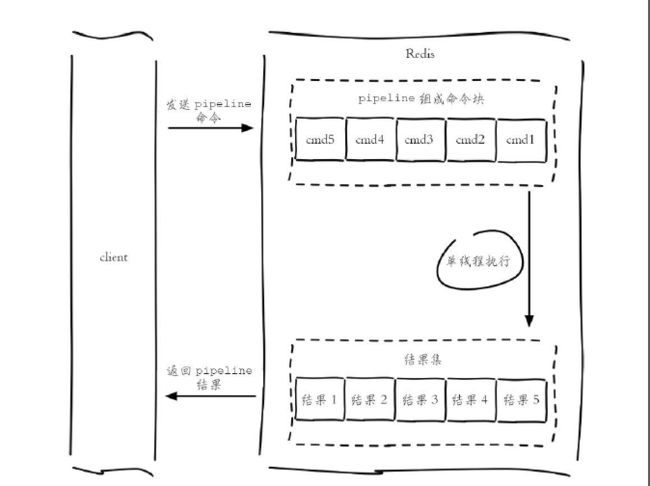 使用Pipeline执行n条命令模型
使用Pipeline执行n条命令模型
- 原生批量命令与Pipeline对比
原生批量命令是原子的,Pipeline是非原子的。
原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。
事务与Lua
为了保证多条命令组合的原子性,Redis提供了简单的事务功能以及集成Lua脚本来解决这个问题。
Redis提供了简单的事务功能,将一组需要一起执行的命令放到multi和exec两个命令之间。multi命令代表事务开始,exec命令代表事务结束,它们之间的命令是原子顺序执行的
如果要停止事务的执行,可以使用discard命令代替exec命令即可。watch命令,简单实现乐观锁的事务.
- 在Redis中使用Lua
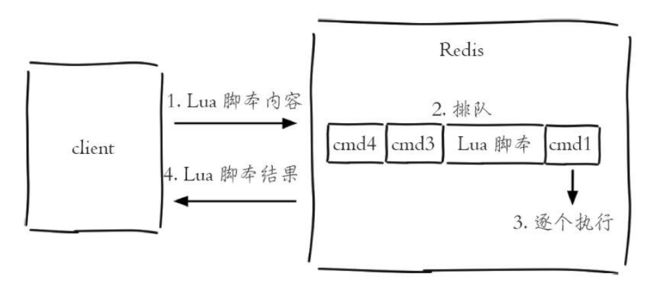 eval命令执行Lua脚本过程
eval命令执行Lua脚本过程
- Lua的Redis API
redis.call("set", "hello", "world")
redis.call("get", "hello")
相当于127.0.0.1:6379> eval 'return redis.call("get", KEYS[1])' 1 hello
- 案例
好处:
·Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
·Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在Redis内存中,实现复用的效果。
·Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
1)将列表中所有元素取出,赋值给mylist:
local mylist = redis.call("lrange", KEYS[1], 0, -1)
2)定义局部变量count=0,这个count就是最后incr的总次数:
local count = 0
3)遍历mylist中所有元素,每次做完count自增,最后返回count:
for index,key in ipairs(mylist)
do
redis.call("incr",key)
count = count + 1
end
return count
将上述脚本写入lrange_and_mincr.lua文件中,并执行如下操作,执行后所有的值+1.
redis-cli --eval lrange_and_mincr.lua hot:user:list
Redis如何管理Lua脚本
将Lua脚本加载到Redis内存中
script load script
用于判断sha1是否已经加载到Redis内存中
scripts exists sha1 [sha1 …]
用于清除Redis内存已经加载的所有Lua脚本
script flush
用于杀掉正在执行的Lua脚本,如果当前Lua脚本正在执行写操作,那么script kill将不会生效。
script kill
Bitmaps
设置值(注意,在第一次初始化Bitmaps时,假如偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成Redis的阻塞。)
setbit key offset value
##127.0.0.1:6379> setbit unique:users:2016-04-05 0 1 代表该用户这一天访问了,Bitmaps的位置为0
获取值
gitbit key offset
获取Bitmaps指定范围值为1的个数
bitcount [start][end]
bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中。
bitop op destkey key[key....]
计算Bitmaps中第一个值为targetBit的偏移量
bitpos key targetBit [start] [end]
HyperLogLog
HyperLogLog并不是一种新的数据结构(实际类型为字符串类型),而是一种基数算法,通过HyperLogLog可以利用极小的内存空间完成独立总数的统计,数据集可以是IP、Email、ID等.
添加
pfadd key element [element …]
计算独立用户数
pfcount key [key …]
 百万数据集合类型和HyperLogLog占用空间对比
百万数据集合类型和HyperLogLog占用空间对比
可以看到,HyperLogLog内存占用量小得惊人,但是用如此小空间来估算如此巨大的数据,必然不是100%的正确,其中一定存在误差率。Redis官方给出的数字是0.81%的失误率。
合并
pfmerge destkey sourcekey [sourcekey ...]
HyperLogLog内存占用量非常小,但是存在错误率,开发者在进行数据结构选型时只需要确认如下两条即可:
1.只为了计算独立总数,不需要获取单条数据。
2.可以容忍一定误差率,毕竟HyperLogLog在内存的占用量上有很大的优势。
发布订阅(一般用MQ)
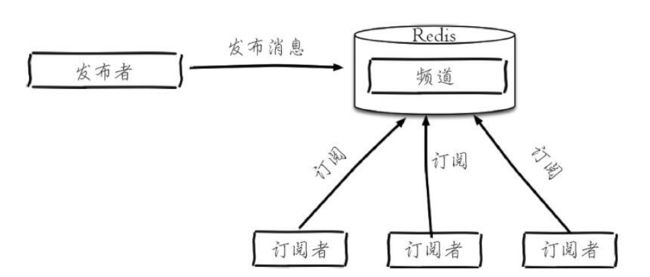 Redis发布订阅模型
Redis发布订阅模型
GEO
Redis3.2版本提供了GEO(地理信息定位)功能,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能.
增加/更新地理位置信息
geoadd key longitude latitude member [longitude latitude member ...]
#127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
获取地理位置信息
geopos key member [member ...]
获取两个地理位置的距离,其中unit代表返回结果的单位
geodist key member1 member2 [unit]