JStorm:1、概念与编程模型
JStorm:2、任务调度
转载自个人博客
示例功能说明:统计单词出现的次数,spout将持续输入的一句句话作为输入流,bolt将一句话分割成单词,最后统计每个单词出现的次数。
示例介绍
如下图所示,单词计数topology由一个spout和下游三个bolt组成。

SentenceSpout:向后端发射一个单值tuple组成的数据流,键名“sentence”,tuple如下:
{“sentence”:“my name is zhangsan”}
SplitSentenceBolt:订阅SentenceSpout发射的数据流,将“sentence”中的语句分割为一个个单词,向后端发射“word”组成的tuple如下:
{“word”:“my”}
{“word”:“name”}
{“word”:“is”}
{“word”:“zhangsan”}
WordCountBolt:订阅SplitSentenceBolt发射的数据流,保存每个特定单词出现的次数,每当bolt收到一个tuple,将对应单词的计数加一,并想后发射该单词当前的计数。
{“word”:“my”,“count”:“5”}
ReportBolt:订阅WordCountBolt的输出流,维护一份所有单词对应的计数表,结束时将所有值打印。
代码实现
添加Pom.xml依赖
com.alibaba.jstorm
jstorm-core
2.2.1
SentenceSpout:继承BaseRichSpout类,在nextTuple方法中生成并向后发射数据流,declareOutputFields方法定义了向后发射数据流tuple的字段名为:sentence。
SplitSentenceBolt:继承BaseRichBolt类,在execute方法中将接收到的tuple分割为单词,并向后传输tuple,declareOutputFields定义了tuple字段为word。
WordCountBolt:继承BaseRichBolt,在execute方法中统计单词出现的次数,本地使用HashMap保存所有单词出现的次数。接收到tuple后更新该单词出现的次数并向后传输tuple,declareOutputFields定义了tuple为"word", "count"。
ReportBolt:继承BaseRichBolt类,在execute方法中汇总所有单词出现的次数。本地使用HashMap保存所有单词出现的次数。当任务结束时,Cleanup方法打印统计结果。
WordCountTopology:创建topology,定义了Spout以及Bolt之间数据流传输的规则,以及并发数(前后并发为2、2、4、1)。进程(worker)、线程(Executor)与Task之间的关系如下图:
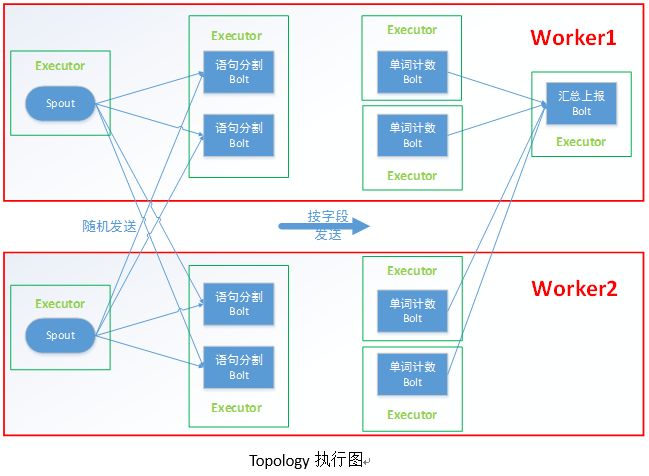
核心代码参考如下,注意其中的shuffleGrouping设定向后传输数据流为随机,fieldsGrouping按照字段值向后传输数据流,能保证同一个单词由同一个WordCountBolt统计,而globalGrouping保证汇总的bolt是单例。
WordCountTopology.java
//WordCountTopology代码
import storm.blueprints.word.v1.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import static storm.blueprints.utils.Utils.*;
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws Exception {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2)
.setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt, 4)
.fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt)
.globalGrouping(COUNT_BOLT_ID);
Config config = new Config();
config.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
waitForSeconds(10);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}
SentenceSpout.java
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.blueprints.utils.Utils;
import java.util.Map;
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = {
"my dog has fleas",
"i like cold beverages",
"the dog ate my homework",
"don't have a cow man",
"i don't think i like fleas"
};
private int index = 0;
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
public void open(Map config, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
this.collector.emit(new Values(sentences[index]));
index++;
if (index >= sentences.length) {
index = 0;
}
Utils.waitForMillis(1000);
}
}
SplitSentenceBolt.java
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.Map;
public class SplitSentenceBolt extends BaseRichBolt{
private OutputCollector collector;
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words){
this.collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCountBolt.java
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
public class WordCountBolt extends BaseRichBolt{
private OutputCollector collector;
private HashMap counts = null;
public void prepare(Map config, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap();
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count++;
this.counts.put(word, count);
this.collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
ReportBolt.java
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class ReportBolt extends BaseRichBolt {
private HashMap counts = null;
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.counts = new HashMap();
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = tuple.getLongByField("count");
this.counts.put(word, count);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// this bolt does not emit anything
}
@Override
public void cleanup() {
System.out.println("--- FINAL COUNTS ---");
List keys = new ArrayList();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for (String key : keys) {
System.out.println(key + " : " + this.counts.get(key));
}
System.out.println("--------------");
}
}
Utils.java
public class Utils {
public static void waitForSeconds(int seconds) {
try {
Thread.sleep(seconds * 1000);
} catch (InterruptedException e) {
}
}
public static void waitForMillis(long milliseconds) {
try {
Thread.sleep(milliseconds);
} catch (InterruptedException e) {
}
}
}
转载请标明出处