创建本地Hadoop集群
Hadoop需要的环境支持
操作系统:Linux
JDK支持:最新版JDK:Linux环境下JDK安装和配置
三种运行模式
- 单机模式:安装简单,几乎不用作任何配置,但仅限于调试用途。
- 伪分布模式:在单节点上同时启动namenode、datanode、jobtracker、tasktracker、secondary namenode等五个进程,模拟分布式运行的各个节点。
- 完全分布式模式:正常的Hadoop集群,由多个各司其职的节点构成。
这里我们介绍伪分布模式的安装和配置。
Hadoop的安装和配置
1、下载安装
(1)进入Hadoop官网http://hadoop.apache.org/,进入页面后向下拉动,找到如下图所示链接,点击进入
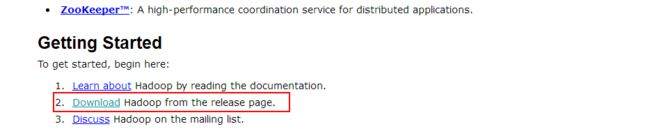
(2)然后,我们将进入会看到Hadoop的各种版本的列表,你可以选择你想要的版本,进行下载,点击对应版本后面的“binary”进入下载页面。
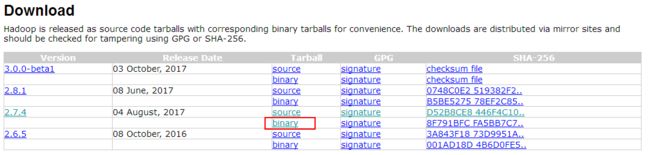
(3)然后,单击第一个链接,即可下载:

(4)将我们下载的hadoop-2.7.4.tar.gz文件放到/opt/hadoop目录下,然后使用超级用户权限执行解压命令
tar -zxvf hadoop-2.7.4.tar.gz
(5)解压之后,我们执行“ls”命令,可以看到在/opt/hadoop目录下多了一个hadoop-2.7.4目录,进入此目录,我们可以看到:

2、修改配置文件
此时,我们需要配置的文件主要是“etc”目录下,进入etc/hadoop目录,我们需要修改的文件主要包括:
core-site.xml ## Hadoop核心配置文件。
hdfs-site.xml ## 配置HDFS系统,HDFS后台程序设置的配置:namenode、secondary namenode、datanode
mapred-site.xml ## MapReduce后台程序设置的配置:jobtracker和tasktracker。
hadoop-env.sh ## 环境配置文件,在运行Hadoop的脚本中使用的环境变量。
(1)执行“vim hadoop-env.sh ”,开始编辑hadoop-env.sh ,修改JAVA_HOME的值:
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_151

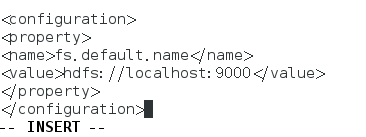
(2)执行“vim core-site.xml ”,开始编辑core-site.xml:
fs.default.name
hdfs://localhost:9000 # NameNode的ip地址和端口
(3)执行“vim hdfs-site.xml ”,开始编辑hdfs-site.xml :
dfs.data.dir
/opt/hadoop/hadoop-2.7.4/data
dfs.replication
1

说明:
hdfs-site.xml是HDFS的配置文件,这里配置了2个参数
- dfs.data.dir:本地磁盘目录,HDFS数据库存储数据块的地方。可以是逗号分隔的目录列表,典型的,每个目录在不同的磁盘。这些目录被轮流使用,一个块存储在这个目录,下一个快存储在下一个目录,,一次循环。每个块在同一个机器上仅存储一份。不存在目录被忽略。必须常见文件夹,否则被视为不存在。
- dfs.replication:数据库副本数。
(4)执行“mapred-site.xml ”,开始编辑mapred-site.xml :
mapred.job.tracker
localhost:9001 # 作业跟踪器的ip和端口

3、设置环境变量
使用root用户编辑/etc/profile文件,添加环境变量。

使环境变量生效
source /ect/profile
4、配置SSH免密登录
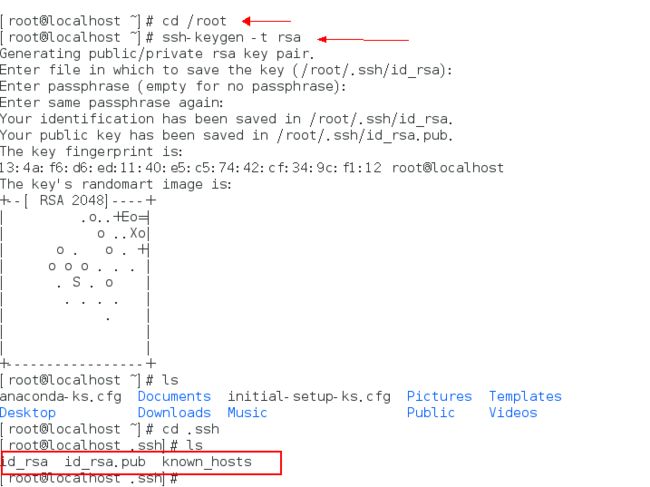
配置SSH,生成秘钥,使用SSH可以免密码连接到localhost。
切换目录到 /root 下,执行 ** ssh-keygen -t rsa **,命令,为当前root用户来创建一对秘钥(公钥和私钥)。
id_rsa 为私钥,id_rsa.pub 为公钥
将公钥拷贝到 /root/.ssh/authorized_keys 目录下,用户远程登录时,即可免密码登录。
# cd authorized_keys
5、格式化分布式文件系统
格式化名称节点,在名称节点上建立一系列的结构用来存放HDFS的元数据,执行命令:
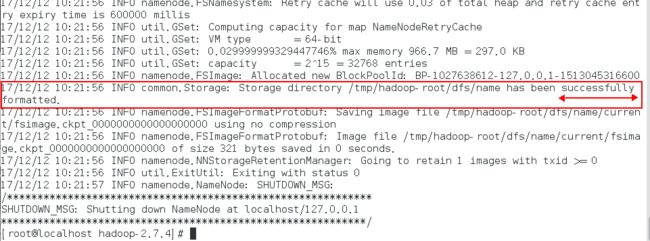
[root@localhost hadoop-2.7.4]# bin/hadoop namenode -format
执行完成后,看到如下语句,则说明格式化成功 。
6、启动守护进程
[root@localhost hadoop-2.7.4]# sbin/start-all.sh
输出结果如下:
[root@localhost hadoop-2.7.4]# sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-namenode-localhost.out
localhost: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is 8e:46:af:27:57:3e:fc:b6:c8:b3:a7:0e:1f:02:d2:5a.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-secondarynamenode-localhost.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-localhost.out
查看任务是否启动成功:
[root@localhost hadoop-2.7.4]# /usr/java/jdk1.8.0_151/bin/jps
18033 DataNode
18433 NodeManager
18775 Jps
17912 NameNode
18188 SecondaryNameNode
18333 ResourceManager