接上一篇文章,我们来到第二关首页,网址:http://www.heibanke.com/lesson/crawler_ex01/
页面长这样

image.png
看起来像是要破解账号密码,没有头绪,F12看看html结构
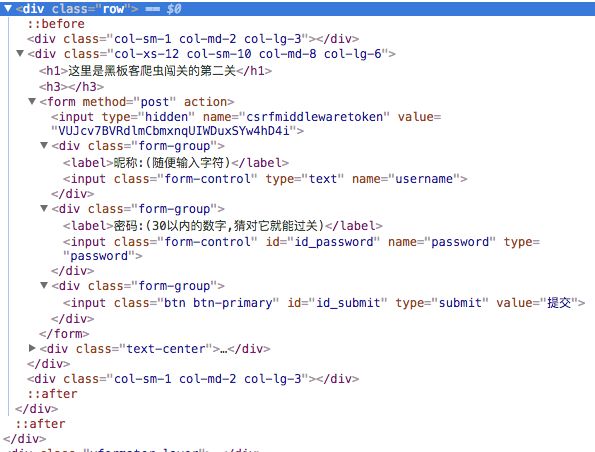
image.png
可以看到,主要内容就是一个form表单,点击Sources看看源代码,关键代码就是这个表单
可以看到,action="",说明这个表单是本页面处理,但是又找不到提交按钮对应的点击事件,随便填个数据点击提交按钮看看http请求,可以看到表单以post的方式提交到了本页面,参数如下图所示
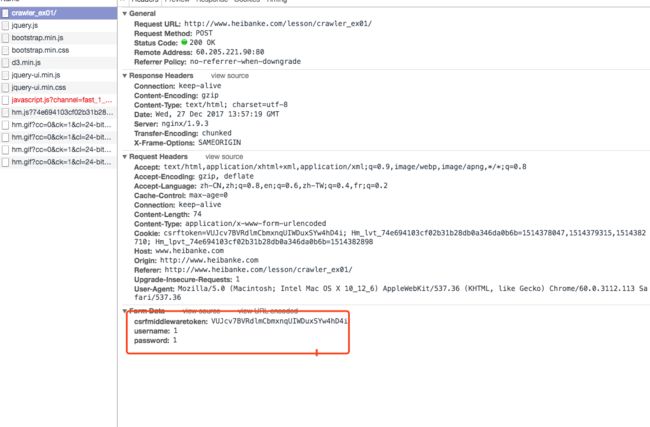
点击提交按钮的post请求
界面提示密码错误

image.png
看到这里就很明显了,这是一个接口,地址是 http://www.heibanke.com/lesson/crawler_ex01/,参数有三个,csrfmiddlewaretoken username password,通过页面提示和form表单代码可以得知:
csrfmiddlewaretoken:写死的,值为VUJcv7BVRdlmCbmxnqUIWDuxSYw4hD4i,
username:用户名,随便编一个即可
password:关键参数,本关目的就是让你猜测password的值
清楚了这些就好办了,循环请求接口,每次让password增大1,直到正确为止,代码:
from urllib import request
from urllib import parse
from bs4 import BeautifulSoup
def get_page(url, params):
print('get url %s' % url)
data = parse.urlencode(params).encode('utf-8')
req = request.Request(url, data)
page = request.urlopen(req).read()
page = page.decode('utf-8')
return page
count = 0
url = "http://www.heibanke.com/lesson/crawler_ex01/"
token = 'VUJcv7BVRdlmCbmxnqUIWDuxSYw4hD4i'
username = 'pkxutao'
password = -1
# 构造post参数
data = {
'csrfmiddlewaretoken': token,
'username': 'pkxutao',
'password': password
}
result = '您输入的密码错误, 请重新输入'
while result == '您输入的密码错误, 请重新输入':
count += 1
password += 1
data['password'] = password
print('第%d次尝试,参数:%d' % (count, password))
result = get_page(url, data)
soup = BeautifulSoup(result, "html.parser")
# 解析h3元素
h3 = soup.find_all("h3")[0]
result = soup.find_all("h3")[0].text
print('成功,username:%s, password:%d' % (username, password))
结果

部分结果截图
在页面验证,用户名随便输一个,密码输入16,结果如图

image.png
搞定收工