Build project from Tesseract Source Code for Visual Studio 2012
上一节讲到,如果直接编译libtesseract304工程,会有报错。说找不到某个头文件。看来,Tesseract还依赖于第三方的库。当然,这么没来由的瞎猜也不是个事儿。还不如再上官网找找线索。
果然,有一个页面就专门讲如何安装来着。如果你打算用Linux系统来编译(比如说Ubuntu),那么你就需要安装一些其它的库:
sudo apt-get install autoconf automake libtool
sudo apt-get install pkg-config
sudo apt-get install libpng12-dev
sudo apt-get install libjpeg62-dev
sudo apt-get install libtiff4-dev
sudo apt-get install zlib1g-dev
如果你还想要训练,那就还得再多装一点:
sudo apt-get install libicu-dev
sudo apt-get install libpango1.0-dev
sudo apt-get install libcairo2-dev
你还需要安装Leptonia……这里就不详细说了,因为我的目标是要安装Windows的版本,所选择的编译器是Visual Studio 2012。
可怕的事情发生了,官网上居然只支持VS2015!
然而,机智如我怎么可能为此而安装Visual Studio 2015。毕竟公司给配的电脑的运行速度正处在令我满意的边界值。我怕再装一个编译器会大大有损我司在我心目中的形象。不过现在是搞清楚了,我们需要安装的东西,就是Leptonica。那我去找个针对Visual Studio 2012的Leptonica不就完了吗?
还真让我给找着了!【GitHub Repo】
果断下载。
先来找找上一篇中找不到的allheaders.h吧。
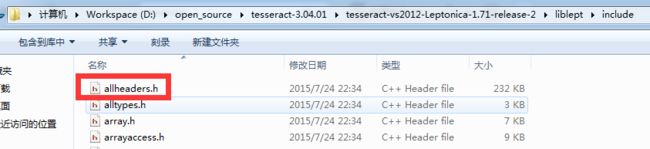
原来就躲在liblept的头文件中呢。顿时有了信心。
打开tesseract.sln
解决方案中包含的项目如下:
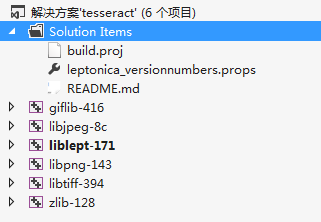
发现项目的属性中,平台工具集为v120。v120表示的是Visual Studio 2013。(GitHub的作者一开始的目标是VS2012来着,后来不知为什么转而支持VS2013去了。)
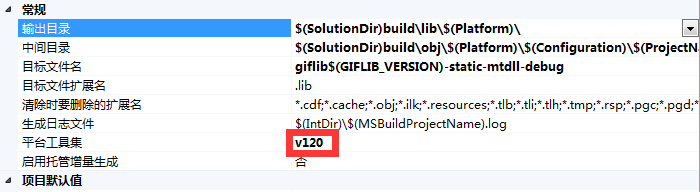
因此,我们需要将 所有项目的平台工具集属性都改成v110。 (Debug|Release)都要改哦!
另外,Visual Studio 2012 的ToolsVersion为4.0。所以也需要手动修改一下所有项目中*.vcxproj中的ToolsVersion:

再着就开始生成吧:
- 生成zlib-128,成功。
- 生成libtiff-394,有警告,成功。
- 生成libpng-143,成功。
- 生成libjpeg-8c,成功。
- 生成giflib-416,有警告,成功。
- 生成liblept-171,失败……
额,失败了……主要原因是在函数中间定义变量,而未在函数一开始定义变量。VC2012不支持这么写。比如说,这样一个函数:
void
lept_direxists(const char *dir,
l_int32 *pexists)
{
char *realdir;
if (!pexists) return;
*pexists = 0;
if (!dir) return;
if ((realdir = genPathname(dir, NULL)) == NULL)
return;
#ifndef _WIN32
{
struct stat s;
l_int32 err = stat(realdir, &s);
if (err != -1 && S_ISDIR(s.st_mode))
*pexists = 1;
}
#else /* _WIN32 */
l_uint32 attributes; //line 21
attributes = GetFileAttributes(realdir);
if (attributes != INVALID_FILE_ATTRIBUTES &&
(attributes & FILE_ATTRIBUTE_DIRECTORY)) {
*pexists = 1;
}
#endif /* _WIN32 */
FREE(realdir);
return;
}
21行的声明没有放在开头写,所以需要修改成:
void
lept_direxists(const char *dir,
l_int32 *pexists)
{
char *realdir;
l_uint32 attributes; //原来的第21行
if (!pexists) return;
*pexists = 0;
if (!dir) return;
if ((realdir = genPathname(dir, NULL)) == NULL)
return;
#ifndef _WIN32
{
struct stat s;
l_int32 err = stat(realdir, &s);
if (err != -1 && S_ISDIR(s.st_mode))
*pexists = 1;
}
#else /* _WIN32 */
attributes = GetFileAttributes(realdir);
if (attributes != INVALID_FILE_ATTRIBUTES &&
(attributes & FILE_ATTRIBUTE_DIRECTORY)) {
*pexists = 1;
}
#endif /* _WIN32 */
FREE(realdir);
return;
}
全都是这样的问题。修改之后,成功生成。 将Release与Debug全都生成完后,在build/lib/Win32目录下,就会产生那么几个重要的文件。
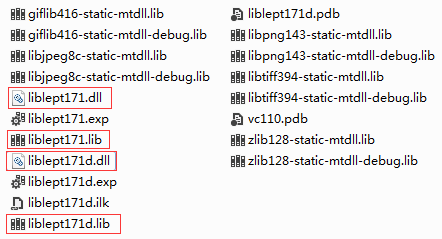
接下来,我们再回过头来看一下
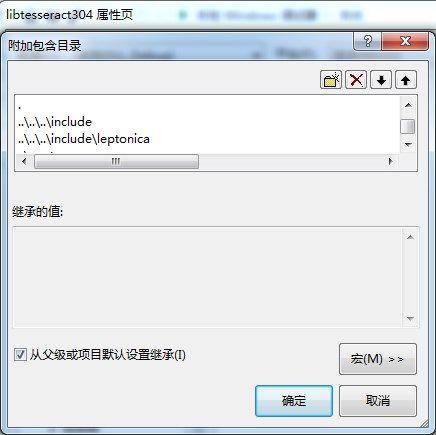
libtesseract304的属性页。其添加的库目录为
..\..\..\lib,
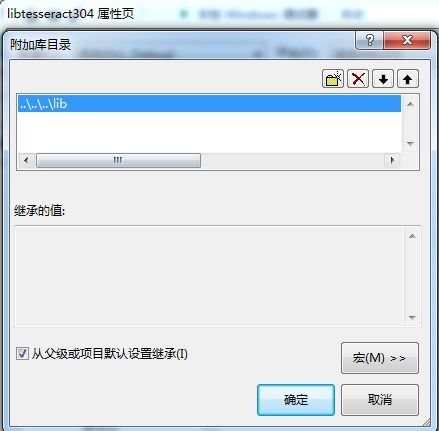
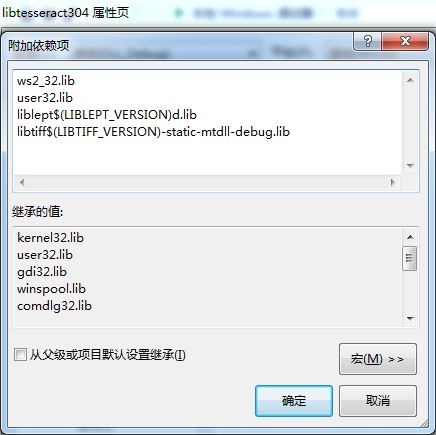
需要添加的库为liblept和libtiff。
include的目录为
..\..\..\include和
..\..\..\include\leptonica
因此接下来要做的事显得顺理成章,在tesseract的同一级目录中新建 lib文件夹。放入这么些个文件。
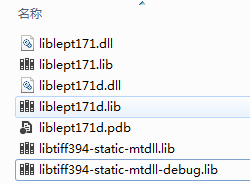
在tesseract的同一级建立 include文件夹,在include文件夹中建立 leptonica文件夹。将liblept中的头文件全部拷入其中。
再次生成,结果还是错误。不过,这次的错误不一样了:

对应的错误代码在这儿:
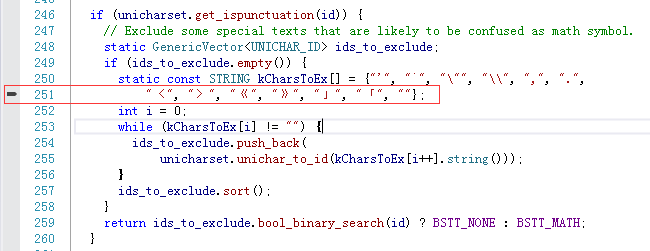
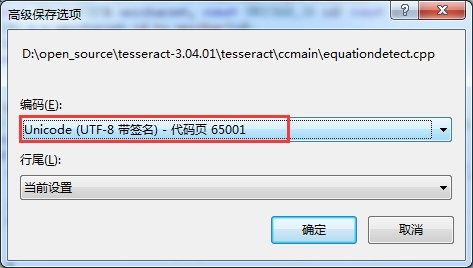
显然是编码方式出了问题。解决方法:
文件->高级保存选项:
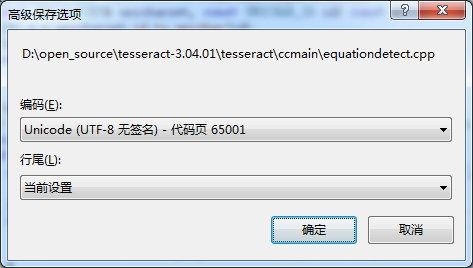
修改为:
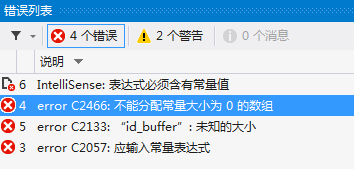
再次生成,继续报错:
对应到的代码段为:
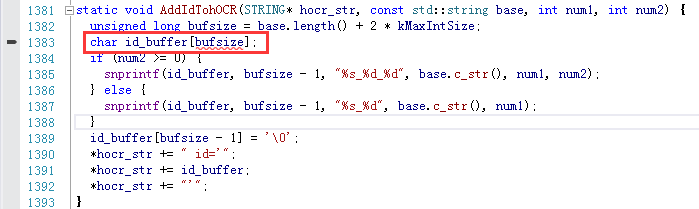
显然又是编译器不支持C99导致的错~Visual C 2012,你敢不敢支持一下C99!
无奈,那就修改一下吧,好在不是什么大问题。
修改为:
static void AddIdTohOCR(STRING* hocr_str, const std::string base, int num1, int num2) {
unsigned long bufsize = base.length() + 2 * kMaxIntSize;
char* id_buffer = (char*)malloc(bufsize*sizeof(char));
if (num2 >= 0) {
snprintf(id_buffer, bufsize - 1, "%s_%d_%d", base.c_str(), num1, num2);
} else {
snprintf(id_buffer, bufsize - 1, "%s_%d", base.c_str(), num1);
}
id_buffer[bufsize - 1] = '\0';
*hocr_str += " id='";
*hocr_str += id_buffer;
*hocr_str += "'";
free(id_buffer);
}
生成,终于成功啦!在vs2010的DLL_Debug目录下生成了libtesseract304d.dll和libtesseract304d.lib文件。
乘胜追击,Release再来一下吧。OK,也是相当成功。在DLL_Release目录下生成了三个文件。

接下来,生成另外一个工程,
tesseract。Debug与Release都很容易就生成了。
好不容易生成好,赶紧拿个例子尝试一下~
Tesseract是一个命令行程序,所以打开cmd命令行工具才是使用Tesseract的正确姿势。
tesseract的命令行语法如下:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
使用tesseract来进行OCR识别的最基本的用法如下:
tesseract myscan.png out
这会在myscan.png这张图像上进行OCR,然后把结果输出到out.txt中。
或者我们可以规定文字的语言,比如用德语来进行OCR。
tesseract myscan.png out -l deu
甚至可以用多种语言来进行识别,比如用德文加英文:
tesseract myscan.png out -l eng+deu
我已经迫不及待了,赶紧来PS一张图尝试一下吧~

原谅我作为程序员的职业病~接下来是见证奇迹的时刻:

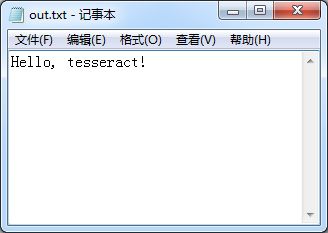
好了,这一篇就写到这里吧。接下来会写些什么,我其实也不知道。敬请期待吧~