参考
知乎 张涛的 算术编码(转载加笔记)
【H.264/AVC视频编解码技术详解】十八:算术编码的基本原理与实现
按:最近复习了下算术编码,算术编码的核心思想是为整个输入序列(而不是单个字符)分配码字,因而平均每字符可以分配长度小于1的码字。找到一篇比较适合新手学习的文章,加入些自己的理解,算是个读书心得吧。
一、Huffman 编码的缺点
1.最小码字长度为1
Huffman 编码使用整数个二进制位对符号进行编码,这种方法在许多情况下无法得到最优的压缩效果。假设某个字符的出现概率为 80%,该字符事实上只需要 -log2(0.8) = 0.322 位编码,但 Huffman 编码一定会为其分配一位 0 或一位 1 的编码。可以想象,整个信息的 80% 在压缩后都几乎相当于理想长度的 3 倍左右,压缩效果可想而知。
2.Huffman 编码需要预先扫描所有符号,得到总体的概率分布并存储更新,额外增加了复杂度。
难道真的能只输出 0.322 个 0 或 0.322 个 1 吗?是用剪刀把计算机存储器中的二进制位剪开吗?计算机真有这样的特异功能吗?慢着慢着,我们不要被表面现象所迷惑,其实,在这一问题上,我们只要换一换脑筋,从另一个角度……哎呀,还是想不通,怎么能是半个呢?好了,不用费心了,数学家们也不过是在十几年前才想到了算术编码这种神奇的方法,还是让我们虚心地研究一下他们究竟是从哪个角度找到突破口的吧。
二、算术编码例子 输出:一个小数
更神奇的事情发生了,算术编码对整条信息(无论信息有多么长),其输出仅仅是一个数,而且是一个介于 0 和 1 之间的二进制小数。例如算术编码对某条信息的输出为 1010001111,那么它表示小数 0.1010001111,也即十进制数 0.64。
咦?怎么一会儿是表示半个二进制位,一会儿又是输出一个小数,算术编码怎么这么古怪呀?不要着急,我们借助下面一个简单的例子来阐释算术编码的基本原理。为了表示上的清晰,我们暂时使用十进制表示算法中出现的小数,这丝毫不会影响算法的可行性。
1.压缩
考虑某条信息中可能出现的字符仅有 a b c 三种,我们要压缩保存的信息为 bccb。
在没有开始压缩进程之前,假设我们对 a b c 三者在信息中的出现概率一无所知(我们采用的是自适应模型),没办法,我们暂时认为三者的出现概率相等,也就是都为 1/3,我们将 0 - 1 区间按照概率的比例分配给三个字符,即 a 从 0.0000 到 0.3333,b 从 0.3333 到 0.6667,c 从 0.6667 到 1.0000。用图形表示就是:
+-- 1.0000 | Pc = 1/3 | | +-- 0.6667 | Pb = 1/3 | | +-- 0.3333 | Pa = 1/3 | | +-- 0.0000
现在我们拿到第一个字符 b,让我们把目光投向 b 对应的区间 0.3333 - 0.6667。这时由于多了字符 b,三个字符的概率分布变成:Pa = 1/4,Pb = 2/4,Pc = 1/4。好,让我们按照新的概率分布比例划分 0.3333 - 0.6667 这一区间,划分的结果可以用图形表示为:
+-- 0.6667 Pc = 1/4 | +-- 0.5834 | | Pb = 2/4 | | | +-- 0.4167 Pa = 1/4 | +-- 0.3333
接着我们拿到字符 c,我们现在要关注上一步中得到的 c 的区间 0.5834 - 0.6667。新添了 c 以后,三个字符的概率分布变成 Pa = 1/5,Pb = 2/5,Pc = 2/5。我们用这个概率分布划分区间 0.5834 - 0.6667:
+-- 0.6667 | Pc = 2/5 | | +-- 0.6334 | Pb = 2/5 | | +-- 0.6001 Pa = 1/5 | +-- 0.5834
现在输入下一个字符 c,三个字符的概率分布为:Pa = 1/6,Pb = 2/6,Pc = 3/6。我们来划分 c 的区间 0.6334 - 0.6667:
+-- 0.6667 | | Pc = 3/6 | | | +-- 0.6501 | Pb = 2/6 | | +-- 0.6390 Pa = 1/6 | +-- 0.6334
输入最后一个字符 b,因为是最后一个字符,不用再做进一步的划分了,上一步中得到的 b 的区间为 0.6390 - 0.6501,好,让我们在这个区间内随便选择一个容易变成二进制的数,例如 0.64,将它变成二进制 0.1010001111,去掉前面没有太多意义的 0 和小数点,我们可以输出 1010001111,这就是信息被压缩后的结果,我们完成了一次最简单的算术压缩过程。
2.解压
怎么样,不算很难吧?可如何解压缩呢?那就更简单了。解压缩之前我们仍然假定三个字符的概率相等,并得出上面的第一幅分布图。解压缩时我们面对的是二进制流 1010001111,我们先在前面加上 0 和小数点把它变成小数 0.1010001111,也就是十进制 0.64。这时我们发现 0.64 在分布图中落入字符 b 的区间内,我们立即输出字符 b,并得出三个字符新的概率分布。类似压缩时采用的方法,我们按照新的概率分布划分字符 b 的区间。在新的划分中,我们发现 0.64 落入了字符 c 的区间,我们可以输出字符 c。同理,我们可以继续输出所有的字符,完成全部解压缩过程(注意,为了叙述方便,我们暂时回避了如何判断解压缩结束的问题,实际应用中,可以通过加休止符的方式解决)。
现在把教程抛开,仔细回想一下,直到理解了算术压缩基本原理,并产生许多新的问题为止。
3.真的能接近极限吗?
现在你一定明白了一些东西,也一定有了不少新问题,没有关系,让我们一个一个解决。
首先,我们曾反复强调,算术压缩可以表示小数个二进制位,并由此可以接近无损压缩的熵极限,怎么从上面的描述中没有看出来呢?
算术编码实际上采用了化零为整的思想来表示小数个二进制位,我们确实无法精确表示单个小数位字符,但我们可以将许多字符集中起来表示,仅仅允许在最后一位有些许的误差。
结合上面的简单例子考虑,我们每输入一个符号,都对概率的分布表做一下调整,并将要输出的小数限定在某个越来越小的区间范围内。对输出区间的限定是问题的关键所在,例如,我们输入第一个字符 b 时,输出区间被限定在 0.3333 - 0.6667 之间,我们无法决定输出值得第一位是 3、4、5 还是 6,也就是说,b 的编码长度小于一个十进制位(注意我们用十进制讲解,和二进制不完全相同),那么我们暂时不决定输出信息的任何位,继续输入下面的字符。直到输入了第三个字符 c 以后,我们的输出区间被限定在 0.6334 - 0.6667 之间,我们终于知道输出小数的第一位(十进制)是 6,但仍然无法知道第二位是多少,也即前三个字符的编码长度在 1 和 2 之间。等到我们输入了所有字符之后,我们的输出区间为 0.6390 - 0.6501,我们始终没有得到关于第二位的确切信息,现在我们明白,输出所有的 4 个字符,我们只需要 1 点几个十进制位,我们唯一的选择是输出 2 个十进制位 0.64。这样,我们在误差不超过 1 个十进制位的情况下相当精确地输出了所有信息,很好地接近了熵值(需要注明的是,为了更好地和下面的课程接轨,上面的例子采用的是 0 阶自适应模型,其结果和真正的熵值还有一定的差距)。
4.小数有多长?
你一定已经想到,如果信息内容特别丰富,我们要输出的小数将会很长很长,我们该如何在内存中表示如此长的小数呢?
其实,没有任何必要在内存中存储要输出的整个小数。我们从上面的例子可以知道,在编码的进行中,我们会不断地得到有关要输出小数的各种信息。具体地讲,当我们将区间限定在 0.6390 - 0.6501 之间时,我们已经知道要输出的小数第一位(十进制)一定是 6,那么我们完全可以将 6 从内存中拿掉,接着在区间 0.390 - 0.501 之间继续我们的压缩进程。内存中始终不会有非常长的小数存在。使用二进制时也是一样的,我们会随着压缩的进行不断决定下一个要输出的二进制位是 0 还是 1,然后输出该位并减小内存中小数的长度。
5.静态模型如何实现?
我们知道上面的简单例子采用的是自适应模型,那么如何实现静态模型呢?其实很简单。对信息 bccb 我们统计出其中只有两个字符,概率分布为 Pb = 0.5,Pc = 0.5。我们在压缩过程中不必再更新此概率分布,每次对区间的划分都依照此分布即可,对上例也就是每次都平分区间。这样,我们的压缩过程可以简单表示为:
输出区间的下限 输出区间的上限 --------------------------------------------------
压缩前 0.0 1.0 输入 b 0.0 0.5 输入 c 0.25 0.5 输入 c 0.375 0.5 输入 b 0.375 0.4375
我们看出,最后的输出区间在 0.375 - 0.4375 之间,甚至连一个十进制位都没有确定,也就是说,整个信息根本用不了一个十进制位。如果我们改用二进制来表示上述过程的话,我们会发现我们可以非常接近该信息的熵值(有的读者可能已经算出来了,该信息的熵值为 4 个二进制位)。
6.为什么用自适应模型?
既然我们使用静态模型可以很好地接近熵值,为什么还要采用自适应模型呢?
要知道,静态模型无法适应信息的多样性,例如,我们上面得出的概率分布没法在所有待压缩信息上使用,为了能正确解压缩,我们必须再消耗一定的空间保存静态模型统计出的概率分布,保存模型所用的空间将使我们重新远离熵值。其次,静态模型需要在压缩前对信息内字符的分布进行统计,这一统计过程将消耗大量的时间,使得本来就比较慢的算术编码压缩更加缓慢。
另外还有最重要的一点,对较长的信息,静态模型统计出的符号概率是该符号在整个信息中的出现概率,而自适应模型可以统计出某个符号在某一局部的出现概率或某个符号相对于某一上下文的出现概率,换句话说,自适应模型得到的概率分布将有利于对信息的压缩(可以说结合上下文的自适应模型的信息熵建立在更高的概率层次上,其总熵值更小),好的基于上下文的自适应模型得到的压缩结果将远远超过静态模型。
例如一段码流,某符号在前面出现概率较大而后面概率小,甚至忽大忽小,采用自适应模型就可以更好的适应这样的变动,压缩效率会比静态模型更高。主流视频编码标准如H.264/H.265都使用自适应模型。
7.自适应模型的阶
我们通常用“阶”(order)这一术语区分不同的自适应模型。本章开头的例子中采用的是 0 阶自适应模型,也就是说,该例子中统计的是符号在已输入信息中的出现概率,没有考虑任何上下文信息。
如果我们将模型变成统计符号在某个特定符号后的出现概率,那么,模型就成为了 1 阶上下文自适应模型。举例来说,我们要对一篇英文文本进行编码,我们已经编码了 10000 个英文字符,刚刚编码的字符是 t,下一个要编码的字符是 h。我们在前面的编码过程中已经统计出前 10000 个字符中出现了 113 次字母 t,其中有 47 个 t 后面跟着字母 h。我们得出字符 h 在字符 t 后的出现频率是 47/113,我们使用这一频率对字符 h 进行编码,需要 -log2(47/113) = 1.266 位。
对比 0 阶自适应模型,如果前 10000 个字符中 h 的出现次数为 82 次,则字符 h 的概率是 82/10000,我们用此概率对 h 进行编码,需要 -log2(82/10000) = 6.930 位。考虑上下文因素的优势显而易见。
我们还可以进一步扩大这一优势,例如要编码字符 h 的前两个字符是 gt,而在已经编码的文本中 gt 后面出现 h 的概率是 80%,那么我们只需要 0.322 位就可以编码输出字符 h。此时,我们使用的模型叫做 2 阶上下文自适应模型。
最理想的情况是采用 3 阶自适应模型。此时,如果结合算术编码,对信息的压缩效果将达到惊人的程度。采用更高阶的模型需要消耗的系统空间和时间至少在目前还无法让人接受,使用算术压缩的应用程序大多数采用 2 阶或 3 阶的自适应模型。
8.转义码的作用
使用自适应模型的算术编码算法必须考虑如何为从未出现过的上下文编码。例如,在 1 阶上下文模型中,需要统计出现概率的上下文可能有 256 * 256 = 65536 种,因为 0 - 255 的所有字符都有可能出现在 0 - 255 个字符中任何一个之后。当我们面对一个从未出现过的上下文时(比如刚编码过字符 b,要编码字符 d,而在此之前,d 从未出现在 b 的后面),该怎样确定字符的概率呢?
比较简单的办法是在压缩开始之前,为所有可能的上下文分配计数为 1 的出现次数,如果在压缩中碰到从未出现的 bd 组合,我们认为 d 出现在 b 之后的次数为 1,并可由此得到概率进行正确的编码。使用这种方法的问题是,在压缩开始之前,在某上下文中的字符已经具有了一个比较小的频率。例如对 1 阶上下文模型,压缩前,任意字符的频率都被人为地设定为 1/65536,按照这个频率,压缩开始时每个字符要用 16 位编码,只有随着压缩的进行,出现较频繁的字符在频率分布图上占据了较大的空间后,压缩效果才会逐渐好起来。对于 2 阶或 3 阶上下文模型,情况就更糟糕,我们要为几乎从不出现的大多数上下文浪费大量的空间。
我们通过引入“转义码”来解决这一问题。“转义码”是混在压缩数据流中的特殊的记号,用于通知解压缩程序下一个上下文在此之前从未出现过,需要使用低阶的上下文进行编码。
举例来讲,在 3 阶上下文模型中,我们刚编码过 ght,下一个要编码的字符是 a,而在此之前,ght 后面从未出现过字符 a,这时,压缩程序输出转义码,然后检查 2 阶的上下文表,看在此之前 ht 后面出现 a 的次数;如果 ht 后面曾经出现过 a,那么就使用 2 阶上下文表中的概率为 a 编码,否则再输出转义码,检查 1 阶上下文表;如果仍未能查到,则输出转义码,转入最低的 0 阶上下文表,看以前是否出现过字符 a;如果以前根本没有出现过 a,那么我们转到一个特殊的“转义”上下文表,该表内包含 0 - 255 所有符号,每个符号的计数都为 1,并且永远不会被更新,任何在高阶上下文中没有出现的符号都可以退到这里按照 1/256 的频率进行编码。
“转义码”的引入使我们摆脱了从未出现过的上下文的困扰,可以使模型根据输入数据的变化快速调整到最佳位置,并迅速减少对高概率符号编码所需要的位数。
9.存储空间问题
在算术编码高阶上下文模型的实现中,对内存的需求量是一个十分棘手的问题。因为我们必须保持对已出现的上下文的计数,而高阶上下文模型中可能出现的上下文种类又是如此之多,数据结构的设计将直接影响到算法实现的成功与否。
在 1 阶上下文模型中,使用数组来进行出现次数的统计是可行的,但对于 2 阶或 3 阶上下文模型,数组大小将依照指数规律增长,现有计算机的内存满足不了我们的要求。
比较聪明的办法是采用树结构存储所有出现过的上下文。利用高阶上下文总是建立在低阶上下文的基础上这一规律,我们将 0 阶上下文表存储在数组中,每个数组元素包含了指向相应的 1 阶上下文表的指针,1 阶上下文表中又包含了指向 2 阶上下文表的指针……由此构成整个上下文树。树中只有出现过的上下文才拥有已分配的节点,没有出现过的上下文不必占用内存空间。在每个上下文表中,也无需保存所有 256 个字符的计数,只有在该上下文后面出现过的字符才拥有计数值。由此,我们可以最大限度地减少空间消耗。
10.关于CABAC(原创)
CABAC被视频标准H.264/H.265所采用,对量化后的系数进一步的压缩,测试表明压缩后可以节省10-15%的码率。CABAC可以分为二值化、上下文建模和二进制算术编码三个步骤。
其中上下文建模相当于把整段码流进行了再次的细分,把相同条件下的字符bin(比如块大小/亮度色度/语法元素/扫描方式/周围情况等)归属于某个context,形成一个比较独立的子队列而进行编码,其更新只与当前的状态和当前字符是否MPS有关(换句话说,只和历史该子队列编码字符和当前字符有关),而与别的子队列/字符是无关的。当然输出码字往往是根据规则而“混”在一起的。
对于某个子队列,context的状态会随着当前编码符号进行更新,以更贴近目前的实际概率。同时比较其范围,移出上下限相同的位的比特进入码流,再编码下一个符号。一般而言,若当前编码符号为LPS,由于其概率小于0.5,根据自信息计算有1-5比特要移出;而如果是MPS符号,其自信息是不到1比特的,这时候结合之前编码情况决定是否移出比特。目前在码率估计方面,就可以利用查表来估计每个符号对应的码字长度,从而省去二进制算术编码环节。
CABAC虽然性能很好,但也存在以下几点不足:
复杂度过高,不易并行处理。存在块级依赖(左/上角的块没有码率估计/熵编码,后继块就无法得到更新后的状态,从而无法开始码率估计/熵编码)、Bin级依赖(同一个子队列的bin存在前后依赖性,后继的bin要等前面bin编完后才能得到更新后的上下文状态)以及编码的几个环节依赖,这些依赖性会影响编码器的并行实现。
计算精度问题。为简化计算,CABAC采用128个状态来近似,根据原来状态和当前符号性质查表得到下个状态。这个过程中会有一些精度的损失。另外,如果当一连串的MPS到来,状态到达62后就不会继续改变,只会“原地踏步”。换句话说,当概率到达0.01975时就不会随着符号继续变小,这样会影响压缩效率。
Context的设计问题。部分context利用频率很低,在测试中平均一帧都用不到几次,而有的context使用频率很高,需要进一步的优化。
PS:当年学视频编码的CABAC,还真的有点晕头转向的。理解是个循序渐进的过程,水到渠成吧~~
三、更多关于CABAC
参考
【H.264/AVC视频编解码技术详解】十九、熵编码(5):CABAC语法元素的二值化
【H.264/AVC视频编解码技术详解】二十一、熵编码(6):CABAC的上下文环境
CABAC编码解析
CABAC熵编码
H.264协议CABAC熵编码学习(一)
H.264协议CABAC熵编码学习(二)
H.264协议CABAC熵编码学习(三)
H.264协议CABAC熵编码学习(四)
H.264协议CABAC熵编码学习(五)
四、CAVLC
参考
【H.264/AVC视频编解码技术详解】十三、熵编码算法(3):CAVLC原理
【H.264/AVC视频编解码技术详解】十三、熵编码算法(4):H.264使用CAVLC解析宏块的残差数据
1.引言
在我们已经实现的H.264码流结构(如NAL Unit、Slice Header等)的解析中,大多使用定长编码或者指数哥伦布编码实现。而例如预测残差等占据码流大量体积的数据则必须使用压缩率更高的算法,如CAVLC和CABAC等。前者是我们将在本文中讨论的内容,后者将在后续内容中详述。
2.CAVLC的基本原理
我们知道,CAVLC的全称叫做“上下文自适应的变长编码Context-based Adaptive Variable Length Coding”。所谓“上下文自适应”,说明了CAVLC算法不是像指数哥伦布编码那样采用固定的码流-码字映射的编码,而是一种动态编码的算法,因而压缩比远远超过固定变长编码UVLC等算法。
在H.264标准中,CAVLC主要用于预测残差的编码。在本系列第二篇博文中我们给出了H.264的编码流图,其中可知,熵编码的输入为帧内/帧间预测残差经过变换-量化后的系数矩阵。以4×4大小的系数矩阵为例,经过变换-量化后,矩阵通常呈现以下特性:
- 经过变换量化后的矩阵通常具有稀疏的特性,即矩阵中大多数的数据已0为主。CAVLC可以通过游程编码高效压缩连续的0系数串;
- 经过zig-zag扫描的系数矩阵的最高频非0系数通常是值为±1的数据串。CAVLC可以通过传递连续的+1或-1的长度来高效编码高频分量;
- 非零系数的幅值通常在靠近DC(即直流分量)部分较大,而在高频部分较小;
- 矩阵内非0系数的个数同相邻块相关;
鉴于上述的特性3和4,针对待编码的系数在系数矩阵中不同的位置,以及相邻块的有关信息,在编码时采用不同的码表进行编码。CAVLC的这种特性,体现了命名中的“上下文自适应”的方法。
- CAVLC的编码流程
在CAVLC中,熵编码不是像哈夫曼编码等算法一样针对某一个码元进行编码,而是针对一个系数矩阵进行。假设我们希望对一个如下变换系数块进行CAVLC编码:
{
3, 2, -1, 0,
1, 0, 1, 0,
-1, 0, 0, 0,
0, 0, 0, 0,
}
对于一个4×4大小的变换系数矩阵进行CAVLC编码,首先需要对其进行扫描,将二维矩阵转化为一维数组。如前一节所讲,扫描按照zig-zag顺序进行,即按照如下顺序:
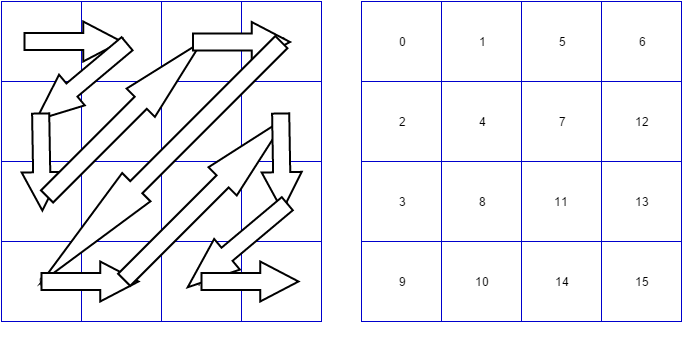
因此,扫描之后变换系数将进行重新排列,得到的结果为:
[3, 2, 1, -1, 0, -1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
在编码过程中需要注意以下重要的语法元素:
- 非零系数的个数(TotalCoeffs):取值范围为[0, 16],即当前系数矩阵中包括多少个非0值的元素;
- 拖尾系数的个数(TrailingOnes):取值范围为[0, 3],表示最高频的几个值为±1的系数的个数。拖尾系数最多不超过3个,若超出则只有最后3个被认为是拖尾系数,其他被作为普通的非0系数;
- 拖尾系数的符号:以1 bit表示,0表示+,1表示-;
- 当前块值(numberCurrent):用于选择编码码表,由上方和左侧的相邻块的非零系数个数计算得到。设当前块值为nC,上方相邻块非零系数个数为nA,左侧相邻块非零系数个数为nB,计算公式为nC = round((nA + nB)/2);对于色度的直流系数,nC = -1;
- 普通非0系数的幅值(level):幅值的编码分为prefix和suffix两个部分进行编码。编码过程按照反序编码,即从最高频率非零系数开始。
- 最后一个非0系数之前的0的个数(TotalZeros);
- 每个非0系数之前0的个数(RunBefore):按照反序编码,即从最高频非零系数开始;对于最后一个非零系数(即最低频的非零系数)前的0的个数,以及没有剩余的0系数需要编码时,不需要再继续进行编码。
在上述各类型数据中,编码非零系数的level相对最为复杂。其主要过程为:
- 确定suffixLength的值:
- suffixLength初始化:通常情况下初始化为0;当TotalCoeffs大于10且TrailingOnes小于3时,初始化为1;
- 若已经编码好的非零系数大于阈值,则suffixLength加1;该阈值定义为3 << ( suffixLength − 1 );编码第一个level后,suffixLength应加1;
-
将有符号的Level值转换为无符号的levelCode:
- 若level > 0,levelCode = (level << 1) - 2;
- 若level < 0,levelCode = -(level << 1) - 1;
编码level_prefix:level_prefix的计算方法为:level_prefix = levelCode/(1 << suffixLength);level_prefix到码流的对应关系由9-6表示;
-
确定后缀的长度:后缀的长度levelSuffixSize通常情况下等于suffixLength,例外情况有:
- level_prefix = 14时,suffixLength = 0, levelSuffixSize = 4;
- level_prefix = 15时,levelSuffixSize = 12;
计算level_suffix的值:level_suffix = levelCode%(1 << suffixLength);
按照levelSuffixSize的长度编码level_suffix;
在上述的系数矩阵中,非零系数个数TotalCoeffs=6,拖尾系数个数TrailingOnes=3,最后一个非零系数之前0的个数TotalZeros=2;假设nC=0。
在H.264标准协议文档的表9-5中查得,coeff_token的值为0x00000100;
编码拖尾系数的符号,从高频到低频,拖尾系数符号为+、-、-,因此符号的码流为011;
-
编码非零系数的幅值,三个普通非零系数分别为1、2、3;
- 编码1:suffixLength初始化为0;levelCode=0;level_prefix=0,查表得对应的码流为1;suffixLength=0,因此不对后缀编码;
- 编码2:suffixLength自增1等于1;levelCode=2;level_prefix=1,查表可知对应的码流为01;suffixLength=1,level_suffix=0,因此后缀码流为0;
- 编码3:suffixLength不满足自增条件,依然为1;levelCode=4;level_prefix=2,查表可知对应的码流为001;suffixLength=1,level_suffix=0,因此后缀码流为0;
- 综上所述,非零系数的幅值部分的码流为10100010;
编码最后非零系数之前0的个数TotalZeros: TotalCoeffs=6,TotalZeros=2时,在表9-7中可知码流为111;
-
编码每个非零系数前0的个数:从高频到低频,每个非零系数前0的总个数(zerosLeft)分别为2、1、0、0、0、0,每个非0系数前连续0的个数(run_before)分别为1、1、0、0、0、0。根据标准文档表9-10可得:
- run_before=1,zerosLeft=2,对应码流为01;
- run_before=1,zerosLeft=1,对应码流为0;
- 所有的0系数都已经编码完成,无需再继续进行编码;
综上所述,整个4×4系数矩阵经过CAVLC编码之后,输出码流为:0000010001110100010111010。
五、CAVLC CABAC对比
H.264 是由国际电信联盟(ITU)和国际标准化组织(ISO)共同制定的新一代视频编码标准。 它有两个熵编码方案:一个是从可变长编码发展而来的上下文自适应可变长编码 (CAVLC);另一个是从算术编码发展而来的基于上下文的自适应二进制算术编码(CABAC)。
CAVLC 是从概率统计分布模型得出的, 应用单一的码表,没有考虑编码符号间的相关性, 不允许根据实际符号的统计特性进行调整。 而实际符号的统计特性会随着空间、时间、视频源、编码条件的变化而发生变化,CAVLC 用于高比特率视频流信息时性能不理想。
CABAC 充分利用视频流的上下文信息,对不同的视频流能够自适应,克服了可变长编码的缺点,且算术编码在实际应用中的计算精度和计算复杂度,提高了编码效率。 基于以上的优点,CABAC 被 H.264 标 准 采 纳, 成 为 H.264 中两个熵编码方案之一。
CABAC 是一种高效的熵编码,它充分利用了视频流的统计和相关特性, 并且从试验结果可以看出,CABAC 编码效率高于CAVLC。 CAVLC 虽然利用了上下文信息,但是由于变长编码的固有缺点,限制了压缩率的进一步提升。 CABAC 的速度虽然不如 CAVLC,但是在芯片技术飞速发展的今天,降低码率比提高速度显得非常重要。 CABAC 作为 H.264 标准的熵编码方案,它对 H.264 的低码率做了很大贡献,这对于发展 H.264 在 3G 无线通信方面的应用非常重要。
H.265/HEVC(High Efficiency Video coding)是目前正在制定中的下一代视频编码标准。它同样是由ITU和MPEG联合制定。与H. 264视频标准相比,它在保证相同图像质量的前提下,可以将视频的码率降低50%。为了达到这一目的,它的计算复杂度也将上升3-4倍。 HEVC有望成为当前H. 264视频编码标准的继承者,在下一个5到10年的时间取代H. 264成为新的主流视频标准。为了提高编码效率,HEVC中的熵编码将只采用高效率的CABAC,不再使用CAVLC。