爬取淘宝美食前100页的title,image,location等并存到mongodb上
selenium python 官网:http://selenium-python.readthedocs.io/
http://selenium-python-zh.readthedocs.io/en/latest/
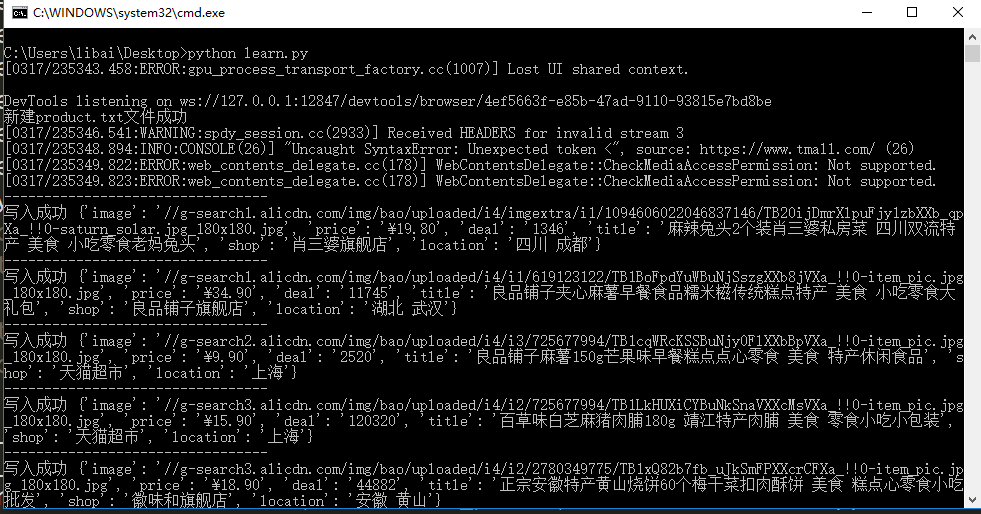
程序在 windows10 下执行
首先安装各种模块和库:
- 安装Selenium,pip install selenium
它是自动化测试工具。支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,安装一个Seleium驱动,我安装的是谷歌 webdriver.Chrome(),这是驱动地址:https://npm.taobao.org/mirrors/chromedriver/2.34/(国内的源)
有界面的自动化浏览器只适合测试,总不能爬取的时候一直开着一个浏览器吧,PhantomJS 是无界面的浏览器, 用 Google 浏览器测试完后就换成这个,
下载地址:http://phantomjs.org/
运行时出现 warnings.warn('Selenium support for PhantomJS has been deprecated, please us , 搜了一下是说 Selenium 以后不再支持 PhantomJS , 百度上说旧版的 PhantomJS 可以使用,试了还是不行,就直接换成了 Google 的 chromedriver.exe
- 下载地址是 https://npm.taobao.org/mirrors/chromedriver/
下载后的 chromedriver.exe 文件要在程序中导入所在的路径,见 browser
我用的 Google Chrome 是 32位的 66.0 ,下载的 chromedriver.exe 是 2.37 的,运行成功。
将下载的 chromedriver.exe 文件拖动到python安装目录下,使得 python 可以找得到这个文件就可以了。
安装 Pyquery, pip install pyquery
pyquery 类似 jquery 的用法,有许多的方法和函数,可以精确定位网页中的元素,属于解析 html 网页的库。安装 pymongo, pip install pymongo
python 调用 mongodb,需要 pymongo 驱动
由于在电脑上安装完 mongoDB 一直连接不上,总是 failed ,所幸就在虚拟机上安装 mongoDB ,在虚拟机上又跑不动那么多程序,只能把数据存到 text 文档,学习一下使用 mongoDB 。
- 安装 mongoDB 网址:http://blog.csdn.net/polo_longsan/article/details/52430539
程序开始
import json
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
#import pymongo
#引入头文件,注释掉的是引入 mongodb,因为电脑连接不上mongodb,就不用了
#client = pymongo.MongoClient(MONGO_URL)
#db = client[MONGO_DB]
函数 search 前的是设置 browser, search 抓取首页和发送淘宝搜索关键词
chrome_options = Options()
#设置为 headless 模式,注释掉就会弹出Google浏览器窗口显示
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(executable_path=(r'C:\Users\libai\AppData\Local\Google\Chrome\Application\chromedriver.exe'), chrome_options=chrome_options)
#browser 中的地址是所下载的 chromdriver.exe 所放的位置,我把它放到了 chrome 安装目录下
wait = WebDriverWait(browser, 10)
def search():
try:
browser.get('https://www.taobao.com/')
#用的是 CSS 选择器
inputs = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")))
inputs.send_keys("美食")
submit.click()
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total")))
result = int(re.compile("(\d\d\d)").search(total.text).group(1))
get_products()
return result
except TimeoutException:
search()
#一旦超时,就重新调用 search
在抓取完页面后, 跳下一页,直接在 inputs 中输入跳转的页面,点击确定就行了
def next_page(page_number):
try:
inputs = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
inputs.clear()
inputs.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"), str(page_number)))
get_products()
except TimeoutException:
next_page(page_number)
获取页面详细信息,使用 pyquery 提取页面中的元素
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item")))
#等待页面加载完成
html = browser.page_source
doc = pq(html)
#.items() 函数属性是提取多个
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image' : item.find('.pic .pic-link .img').attr("src"),
'price' : item.find('.row .price').text().replace('\n', '') ,
'deal' : item.find('.row .deal-cnt').text()[:-3],
'title' : item.find('.title').text().replace('\n', ' '),
'shop' : item.find('.shop').text(),
'location' : item.find('.location').text()
}
print('---------------------------------')
save_to_text(product)
存储到 text 文件中,不加 encoding="UTF-8" ,会报编码错误, json 格式更加便利于存取
def save_to_text(product):
try:
with open("product.txt", "a", encoding="UTF-8") as f:
f.write(json.dumps(product) + '\n')
print("写入成功", product)
except:
print("写入失败", product)
主程序
def main():
with open('product.txt', "w", encoding="UTF-8") as f:
print("新建product.txt文件成功")
total = search()
print("一共有 " + str(total) + " 页")
for i in range(2, total):
print("跳转到第 %d 页" %i)
next_page(i)
browser.close()
if __name__ == "__main__":
main()
从 text 文件中读取,再写入到 mongoDB 数据库中
import json
import pymongo
MONGO_URL = "localhost"
MONGO_DB = "taobao"
MONGO_TABLE = 'product'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def openandsave(filename):
file = open(filename)
while 1:
lines = file.readlines(100000)
if not lines:
break
for line in lines:
print(json.loads(line))
save_to_mongodb(json.loads(line))
print('-----------------')
file.close()
def save_to_mongodb(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到MONGODB成功', result)
except:
print('存储到MONGODB失败', result)
def main():
filename = "product.txt"
openandsave(filename)
if __name__ == '__main__':
main()
看起来不是很对,有些细节的地方没有调整好
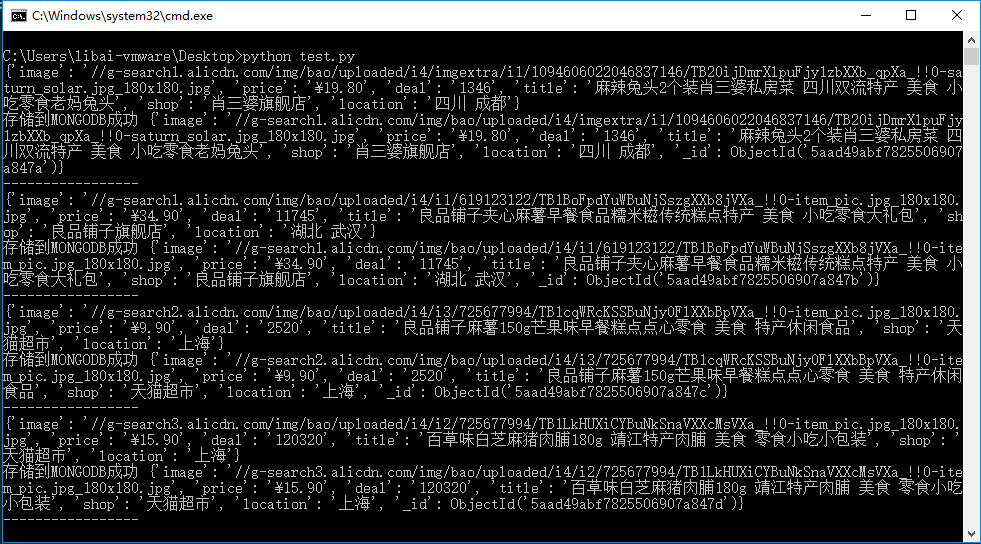
数据库图片
