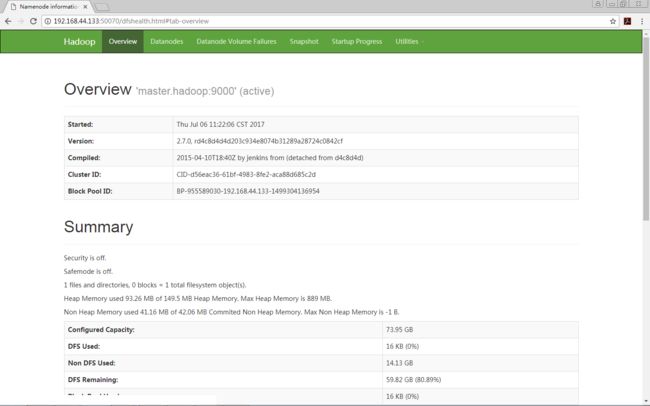
环境:
主机配置:win7旗舰版64位,i5处理器,8G内存,500G固态 + 1T机械
虚拟机软件:VMwareworkstation_full_12.1.0.2487.1453173744
CentOS镜像:CentOS-7-x86_64-Everything-1611
SSH工具:SecureCRT-v8.0.4
jdk:jdk-8u131-linux-x64
hadoop:hadoop-2.7.0.tar
效果图:
1.虚拟机设置
注意内存分配,由于系统只有8G内存,而需要配置一主两从,所以我将每个虚拟机的内存设置为2G.

centos7.3初始化时并没有ifconfig指令,需要使用下面两个指令进行安装
yum search ifconfg
yum install net-tools.x86_64
2. jdk安装
a) 在/usr下创建java文件夹并进入该文件夹
mkdir /usr/java
cd /usr/java
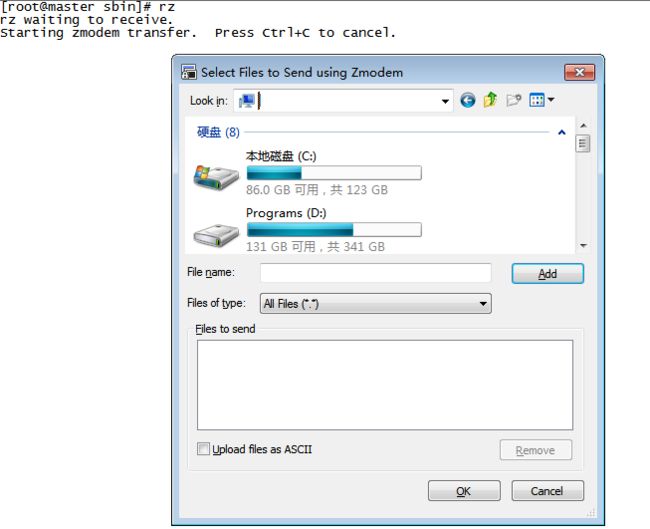
b) 在SecureCRT中使用rz命令将真机中的jdk包传到虚拟机
c) 解压
tar zxvf jdk-8u45-linux-x64.tar.gz
// 解压后可以删除掉gz文件
rm jdk-8u131-linux-x64.gz
d) 配置jdk环境变量
vi /etc/profile
// 将以下数据复制到文件底部
export JAVA_HOME=/usr/java/jdk1.8.0_131
export JRE_HOME=/usr/java/jdk1.8.0_131/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
e) 使配置生效
source /etc/profile
f) 验证安装成功

3. hadoop安装
a) 创建文件夹
mkdir -p /export/server
b) 同jdk中将安装包上传
c) 解压
tar zxvf hadoop-2.7.0.tar.gz
mv hadoop-2.7.0 hadoop
// 删除hadoop-2.7.0.tar.gz文件
rm –rf hadoop-2.7.0.tar.gz
d) 创建tmp文件夹
cd /export/server/hadoop
mkdir tmp
e) 配置环境变量
vi /etc/profile
// 将以下数据加入到文件末尾
export HADOOP_INSTALL=/export/server/hadoop
export PATH=${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin${PATH}
export HADOOP_MAPRED_HOME=${HADOOP_INSTALL}
export HADOOP_COMMON_HOME=${HADOOP_INSTALL}
export HADOOP_HDFS_HOME=${HADOOP_INSTALL}
export YARN_HOME=${HADOOP_INSTALLL}
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_INSTALL}/lib/natvie
export HADOOP_OPTS="-Djava.library.path=${HADOOP_INSTALL}/lib:${HADOOP_INSTALL}/lib/native"
f) 重启”/etc/profile”使环境变量生效
source /etc/profile
g)配置hadoop
g1) 设置hadoop-env.sh和yarn-env.sh中的java环境变量
cd /export/server/hadoop/etc/hadoop/
vi hadoop-env.sh
// 修改JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
g2) 配置core-site.xml文件
hadoop.tmp.dir
/export/server/hadoop/tmp
A base for other temporary directories.
fs.default.name
hdfs://Master.Hadoop:9000
g3) 配置hdfs-site.xml文件
dfs.namenode.name.dir
file:///export/server/hadoop/dfs/name
dfs.datanode.data.dir
file:///export/server/hadoop/dfs/data
dfs.replication
1
dfs.nameservices
hadoop-cluster1
dfs.namenode.secondary.http-address
Master.Hadoop:50090
dfs.webhdfs.enabled
true
g4) 配置mapred-site.xml文件
mapreduce.framework.name
yarn
true
mapreduce.jobtracker.http.address
Master.Hadoop:50030
mapreduce.jobhistory.address
Master.Hadoop:10020
mapreduce.jobhistory.webapp.address
Master.Hadoop:19888
mapred.job.tracker
http://Master.Hadoop:9001
g5) 配置yarn-site.xml文件
yarn.resourcemanager.hostname
Master.Hadoop
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
Master.Hadoop:8032
yarn.resourcemanager.scheduler.address
Master.Hadoop:8030
yarn.resourcemanager.resource-tracker.address
Master.Hadoop:8031
yarn.resourcemanager.admin.address
Master.Hadoop:8033
yarn.resourcemanager.webapp.address
Master.Hadoop:8088
4. 主机名配置
前面三步基本已经安装好一个我们需要的模板系统,接下来就可以进行复制粘贴直接得到另外两个系统了。并对三个虚拟机的主机名作下更改。
hostnamectl set-hostname master.hadoop
配置好后就需要对三者中的hosts文件进行配置:
vi /etc/hosts
// 将以下数据复制进入各个主机中
192.168.44.133 master.hadoop
192.168.44.134 slave1.hadoop
192.168.44.135 slave2.hadoop
使用以下指令对master主机中进行测试,可使用类似指令在slave主机测试
ping slave1.hadoop
ping slave2.hadoop
5. 配置Master无密码登录所有Salve
5.1 Master中的配置
a) 输入以下指令生成ssh
ssh-keygen
// 会生成两个文件,放到默认的/root/.ssh/文件夹中
b) 把id_rsa.pub追加到授权的key里面去
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
c) 修改文件”authorized_keys”权限
chmod 600 ~/.ssh/authorized_keys
d) 设置SSH配置
vi /etc/ssh/sshd_config
// 以下三项修改成以下配置
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
e) 重启ssh服务
service sshd restart
f) 把公钥复制所有的Slave机器上
scp ~/.ssh/id_rsa.pub [email protected]:~/
scp ~/.ssh/id_rsa.pub [email protected]:~/
5.2 所有Slave中的配置
a) 在slave主机上创建.ssh文件夹
mkdir ~/.ssh
// 修改权限
chmod 700 ~/.ssh
b) 追加到授权文件”authorized_keys”
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
// 修改权限
chmod 600 ~/.ssh/authorized_keys
c) 删除无用.pub文件
rm –r ~/id_rsa.pub
d) 在master主机下进行测试
ssh 192.168.1.125
ssh 192.168.1.124
// 如果能够分别无密码登陆slave1, slave2主机,则成功配置
6. 配置Hadoop的集群
a) 修改Master主机上的slaves文件
cd /usr/hadoop/etc/hadoop
vi slaves
// 将文件内容修改为
slave1.hadoop
slave2.hadoop
b) 格式化HDFS文件系统
// 在Master主机上输入以下指令
hadoop namenode -format
c) 启动hadoop
// 关闭机器防火墙
service iptables stop
cd /usr/hadoop/sbin
./start-all.sh
// 更推荐的运行方式:
cd /usr/hadoop/sbin
./start-dfs.sh
./start-yarn.sh
效果如下:

d) 验证hadoop
// 1. 直接在Master或Slave输入指令:
jps
Master:(端口号只供参考)

Slave:(端口号只供参考)
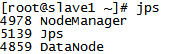
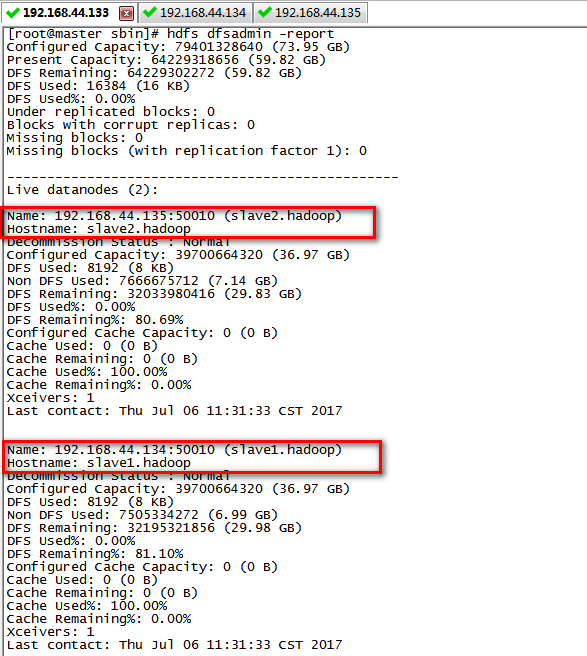
// 2. 输入以下指令,效果图参考开篇贴出的
hdfs dfsadmin -report
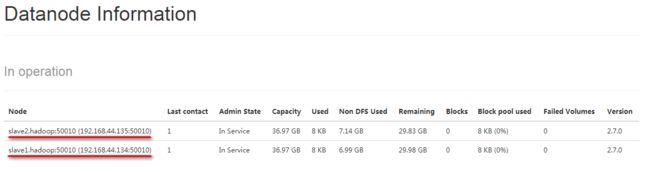
e) 进入hadoop管理首页
// CentOS7中iptables这个服务的配置文件没有了,采用了新的firewalld
// 输入以下指令后,可以在真机浏览器上访问hadoop网页
systemctl stop firewalld
// 在真机浏览器中输入以下网页即可进入
http://192.168.44.133:50070/dfshealth.html#tab-overview