1.摘要
本文主要描述了如何用Python对数据集进行评估,整理,清洗。
完成这一过程后,再通过Tableau对问题“Prosper违约客户具有哪些特点”进行探索,分析和可视化。
最后,用随机森林算法对2009年7月后数据进行建模分析,并对仍在进行中的贷款进行违约与否的预测。
2.项目背景介绍
Prosper是美国第一家P2P借贷平台。此数据集来源于Udacity上的Prosper 2005~2014年的贷款数据。本文希望能通过对已完成贷款的分析,判断出什么类型的客户更容易违约,并预测还未完成的贷款是否会违约。
3.数据变量
原始数据集共包含81个变量,113937条数据,下面对部分重要变量进行说明,其他变量含义可参考变量词典。

4.数据处理
首先加载库和数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#导入数据
df = pd.read_csv('prosperLoanData.csv')
df.head()
然后用df.describe(),df.info()观察数据。
4.1 删除无关变量
此次主要分析1.什么类型的借款人更容易违约。 2.预测未完成的贷款是否会发生违约。所以去掉无关列。
- 冗余的编号列:ListingKey, ListingNumber,LoanNumber等。
- 仅与投资人相关列:LP_CustomerPayments,LP_ServiceFees等。
#删除无关列
df = df.drop(['ListingKey', 'ListingNumber','LenderYield', 'EstimatedEffectiveYield', 'EstimatedLoss',
'EstimatedReturn','LoanKey', 'LoanNumber', 'MemberKey','LP_CustomerPayments',
'LP_CustomerPrincipalPayments', 'LP_InterestandFees', 'LP_ServiceFees',
'LP_CollectionFees', 'LP_GrossPrincipalLoss', 'LP_NetPrincipalLoss',
'LP_NonPrincipalRecoverypayments', 'PercentFunded', 'Recommendations',
'InvestmentFromFriendsCount', 'InvestmentFromFriendsAmount',
'Investors'],axis=1)
从2009年7月开始,Prosper调整了对客户的评估方式,此次我们只对2009-07-01后的贷款进行分析。
#筛选2009-07-01后的数据
df = df[df['ListingCreationDate']>'2009-7-1']
去掉意义重复列:
- BorrowerAPR,BorrowerRate直接相关,只对BorrowerAPR进行分析;
- ProsperRating (numeric),ProsperRating (Alpha)只是不同表达形式,只使用ProsperRating (Alpha);
- CreditScoreRangeUpper,CreditScoreRangeLower直接相关,只用CreditScoreRangeLower。
#去掉意义重复列
df = df.drop(['BorrowerRate','ProsperRating (numeric)',
'CreditScoreRangeUpper'],axis=1)
Prosper对于新客户的评分和老客户有所区别,此次仅针对新客户数据进行分析。
#筛选出新客户
df = df[df['TotalProsperLoans'].isnull()]
#去掉与新客户无关列
df = df.drop(['CreditGrade', 'TotalProsperLoans','TotalProsperPaymentsBilled',
'OnTimeProsperPayments', 'ProsperPaymentsLessThanOneMonthLate',
'ProsperPaymentsOneMonthPlusLate', 'ProsperPrincipalBorrowed',
'ProsperPrincipalOutstanding','ScorexChangeAtTimeOfListing'],axis=1)
4.2 缺失值处理
首先查看下,各变量数据缺失情况。
missing = pd.concat([df.isnull().any(),df.count()], axis =1)
column = ['是否缺失','数量']
missing = pd.DataFrame(list(missing.values),index = list(missing.index),columns = column)
total = missing['数量'].max()
missing['缺失数量'] = total - missing['数量']
missing['缺失率'] = missing['缺失数量']/total
miss = missing[missing['是否缺失'] == True]
miss

- 删除缺失率过大的变量:ClosedDate,GroupKey, LoanFirstDefaultedCycleNumber
- Occupation列:缺失1307条,用‘Other’替换 NaN。
- EmploymentStatusDuration列:仅缺少15条,直接删除缺失的数据。
- DebtToIncomeRatio列:缺失5124条,缺失率较高。因为绝大部分数值在0.5以下,所以在0-0.5之间随机赋值。
#处理空值
df = df.drop(['ClosedDate','GroupKey',
'LoanFirstDefaultedCycleNumber'],axis = 1)
df.Occupation = df.Occupation.fillna('Other')
df.dropna(subset = ['EmploymentStatusDuration'],inplace = True)
#为DebtToIncomeRatio列空值赋值
def ratio(s):
if s>= 0:
a=s
else:
a=np.random.uniform(0,0.5)
return a
df.DebtToIncomeRatio = df.DebtToIncomeRatio.apply(ratio)
4.3 数据转换
- 为了便于处理,将ProsperScore,CreditScoreRangeLower,
EmploymentStatusDuration格式转为int。
#格式转换
df['ProsperScore'] = df.ProsperScore.astype(int)
df['CreditScoreRangeLower'] = df.CreditScoreRangeLower.astype(int)
df['EmploymentStatusDuration'] = df.EmploymentStatusDuration.astype(int)
- LoanStatus数据变换
平台把借款状态分为12种:Cancelled(取消)、Chargedoff(冲销,投资人有损失)、Completed(正常完成,投资人无损失)、Current(贷款还款中)、Defaulted(坏账,投资人有损失)、FinalPaymentInProgress(最后还款中,投资人无损失)、Past Due(逾期还款,投资人无损失)。
本文依据交易是仍在进行中还是已关闭,以及已关闭交易中投资人有无损失将所有数据分成以下三组:
Current(包含Current,Past Due)、
Defaulted(包含Defaulted,Chargedoff)、
Completed(包含Completed,FinalPaymentInProgress)。
为了便于后续分析计算,再将“Completed”改为1,“Defaulted”改为0。
# LoanStatus变换
def loan_status(s):
if s=='Defaulted':
a = 0
elif s=='Chargedoff':
a = 0
elif s=='Completed':
a = 1
elif s == 'FinalPaymentInProgress':
a = 1
else:
a='Current'
return a
# 新建一个Status变量
df['Status'] = df['LoanStatus'].apply(loan_status)
#将数据集分成已完成(Loandata_finished)和未完成(Loandata_unfinished)两个文件
df_finished = df[df['Status']!='Current']
df_unfinished = df[df['Status']=='Current']
#保存数据
df.to_csv('LoanData_clean.csv')
df_finished.to_csv('LoanData_finished.csv')
df_unfinished.to_csv('LoanData_unfinished.csv')
#计算违约率
defaulted_ratio_finished = 1-df_finished.Status.mean()
defaulted_ratio_finished
已完成的贷款的违约率为defaulted_ratio_finished =26.07%
5.使用Tableau进行数据探索
5.1 信用情况与坏账率
此数据集有多个特征体现了贷款用户的信用情况。其中,信用等级(ProsperRating)是Prosper根据自身模型建立,是用于确定贷款利率的主要依据,而信用评分(CreditScore)则是由官方信用评级机构提供。
由图5-1可以看到,随着信用等级(ProsperRating)的不断升高,违约率呈现明显的下降趋势。
而在信用评分(CreditScore)中,低分段(640-700),违约率处于比较高的位置,且没有太大变化。大于720的部分,随着信用评分的升高,违约率明显下降。
说明整体而言,借款人的信用水平越高,违约可能性越低。

5.2 收入与违约率
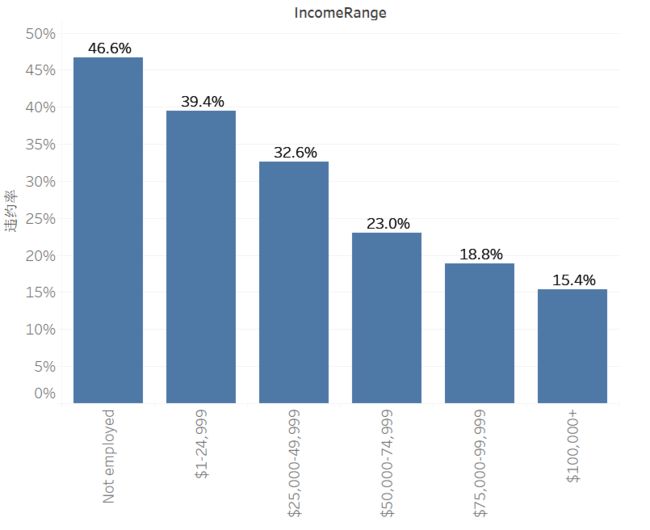
在不同年收入(IncomeRange)中,Not employed的借款人,违约率最高,随着收入增加,违约率不断降低。
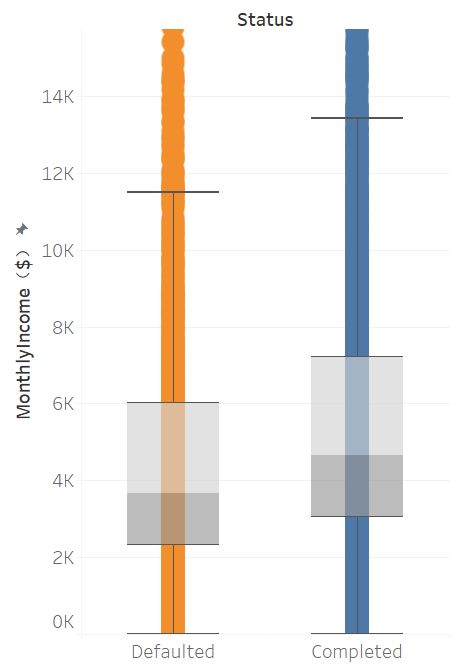
在不同贷款状态下(Status),违约用户的整体月收入(MonthlyIncome)明显低于未违约用户。
5.3 负债收入比与违约率
根据图5-4的左图,违约用户与未违约用户的整体负债收入比差异不大。
再根据负债收入比(DebtToIncome)的四分位点,将所有数据分成数据量接近的四组。从图5-4的右图可以看到低比例(负债收入比0-0.12)与中等比例(0.12-0.19)的违约率都较低。较高比例(0.19-0.29)的违约率略高于前面二者。但高比例(大于0.29)的用户违约率显著升高。

5.4 银行卡额度透支率与违约率
根据银行卡额度透支率(BankcardUtilization)的四分位点,将数据分成 '未使用','较低透支(0,0.3]','中等透支(0.3,0.7]', '较高透支(0.7,1]','严重透支(1,5]'五组。
可以看到,严重透支的借款人,违约率最高。
其次是未使用的用户,这也是为什么金融机构对于“白户”会格外关注的原因。

5.5 征信查询次数与违约率
近半年征信查询次数(InquiriesLast6Months)可以反应出借款人近期向金融机构申请借款的频繁程度,间接体现了借款人近期的资金状况。
图5-6中,绿线表示不同查询次数下的借款笔数。可以看到,绝大部分在7次以下。
而在查询次数0-7区间内,违约率随着查询次数的增加而升高。

5.6 当前逾期与违约率
当前逾期(CurrentDelinquencies)可以很好的反应出借款人的信用情况。
由图5-7,可以看到大部分借款人的当前逾期在2次以内。而在0-6的区间内,违约率随当前逾期数的增加而升高。

5.7 申请信息与违约率
5.7.1 申请理由(ListingCategory)
为了避免某些数量极少的分类对违约率排序的影响,首先筛选出借款笔数在30以上的分类。
由图5-8可以看到,数量最多的是1- Debt Consolidation(债务整合)。
而违约率最高的依次是15- Medical/Dental(医疗),13-Household Expenses(家庭开支),3-Business(商业),均高于30%。


5.7.2 贷款金额(LoanAmount)
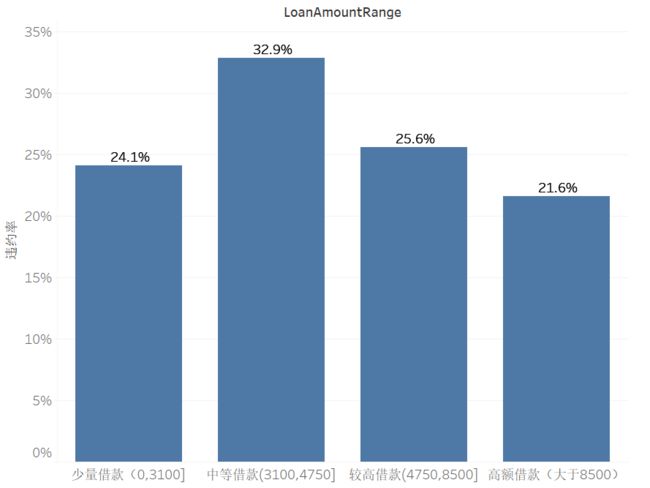
根据贷款金额(LoanAmount)的四分位点,将数据分为数量接近的四组。比较有意思的是,中等借款(3100,4750)的违约率最高,而高额借款(大于8500)的违约率反而最低。
这很可能是因为能申请到高额借款的用户,各方面条件都不错,从而降低了违约率。
5.8 受雇佣状态持续时间与违约率
由图5-11可以看到,在0-30区间内,随着持续时间的增长,违约率逐渐降低,而这一区间也包含了一半左右的数据。
当持续时间继续增长,违约率看不出有明显变化规律。

5.9 地区与违约率
在不同地区之间,违约率也存在比较明显的差异。LA,SD等城市,违约率较高。UT,CO等城市,违约率较低。

5.10 是否拥有房产与违约率
整体而言,有房产的借款人,违约率要明显低于无房产的借款人。

6.建模分析
导入相关库。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
6.1 数据转换
将数据中的字符串变量,均转换为数字。
#将字符串变量用相应的数字变量替换
def harmonize_data(df):
#ProsperRating (Alpha)
df.loc[df['ProsperRating (Alpha)'] == 'HR', 'ProsperRating (Alpha)'] = 1
df.loc[df['ProsperRating (Alpha)'] == 'E', 'ProsperRating (Alpha)'] = 2
df.loc[df['ProsperRating (Alpha)'] == 'D', 'ProsperRating (Alpha)'] = 3
df.loc[df['ProsperRating (Alpha)'] == 'C', 'ProsperRating (Alpha)'] = 4
df.loc[df['ProsperRating (Alpha)'] == 'B', 'ProsperRating (Alpha)'] = 5
df.loc[df['ProsperRating (Alpha)'] == 'A', 'ProsperRating (Alpha)'] = 6
df.loc[df['ProsperRating (Alpha)'] == 'AA', 'ProsperRating (Alpha)'] = 7
#IsBorrowerHomeowner
df.loc[df['IsBorrowerHomeowner'] == True, 'IsBorrowerHomeowner'] =1
df.loc[df['IsBorrowerHomeowner'] == False, 'IsBorrowerHomeowner'] =0
#BorrowerState
le = LabelEncoder().fit(df['BorrowerState'])
df.loc[:,'BorrowerState'] = le.transform(df['BorrowerState'])
#IncomeRange
df.loc[df['IncomeRange'] == 'Not employed', 'IncomeRange'] = 1
df.loc[df['IncomeRange'] == '$0 ', 'IncomeRange'] = 2
df.loc[df['IncomeRange'] == '$1-24,999', 'IncomeRange'] = 3
df.loc[df['IncomeRange'] == '$25,000-49,999', 'IncomeRange'] = 4
df.loc[df['IncomeRange'] == '$50,000-74,999', 'IncomeRange'] = 5
df.loc[df['IncomeRange'] == '$75,000-99,999', 'IncomeRange'] = 6
df.loc[df['IncomeRange'] == '$100,000+', 'IncomeRange'] = 7
return df
df_finished = harmonize_data(df_finished)
#格式转换
df_finished['Status'] = df_finished.Status.astype(int)
6.2 建立模型
按照测试集30%,训练集70%的比例划分数据集,并使用随机森林算法,建立模型。
Y = df_finished['Status']
X = df_finished[['ProsperRating (Alpha)','IncomeRange','DebtToIncomeRatio',
'BankcardUtilization','StatedMonthlyIncome',
'IsBorrowerHomeowner','ListingCategory (numeric)',
'EmploymentStatusDuration', 'InquiriesLast6Months',
'CreditScoreRangeLower','BorrowerState',
'CurrentDelinquencies', 'LoanOriginalAmount']]
#划分数据集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3,random_state=42)
#建立模型
clf = RandomForestClassifier(random_state=42,n_estimators = 200)
clf.fit(X_train,Y_train)
6.3 模型评估
#对测试集进行预测
result = clf.predict(X_test)
#计算准确率
accuracy = clf.score(X_test,Y_test)
accuracy
该模型测试集预测准确率为:accuracy=73.99%
6.4 特征重要性
对于随机森林算法,可以查看在这个模型中,每个特征的重要程度。
#查看各特征的重要性
FeatureImp = pd.Series(clf.feature_importances_,index=list(X_train.columns)).sort_values(ascending=False)
FeatureImp

#特征重要性作图
FeatureImp.sort_values().plot(kind='barh')
plt.xlabel('Feature Importance');

如图6-2所示,StatedMonthlyIncome和EmploymentStatusDuration两个特征最为重要。
6.5 数据预测
根据此模型,对目前仍在进行中的贷款进行违约与否的预测。
#数据预测
df_unfinished = harmonize_data(df_unfinished)
unfinished = df_unfinished[['ProsperRating (Alpha)','IncomeRange','BorrowerState',
'DebtToIncomeRatio', 'BankcardUtilization',
'StatedMonthlyIncome', 'IsBorrowerHomeowner',
'ListingCategory (numeric)','EmploymentStatusDuration',
'InquiriesLast6Months','CreditScoreRangeLower',
'CurrentDelinquencies','LoanOriginalAmount']]
unfinished_predict = clf.predict(unfinished)
#保存预测数据
df_unfinished.to_csv('LoanData_unfinished_predict.csv')
#计算违约率
defaulted_ratio_predict = 1-df_unfinished['StatusPredict'].mean()
defaulted_ratio_predict
仍在进行中的贷款违约率为defaulted_ratio_predict =3.64%
7.总结
本文详细描述了对于Prosper贷款数据,从数据探索到建立模型,并进行预测的完整过程。
发现月收入(StatedMonthlyIncome)以及受雇佣状态持续时间(EmploymentStatusDuration)对是否会违约的影响程度最大。主要是因为这二者是体现借款人稳定性的重要因素。
而在模型建立方面,还可以调整此模型的参数,来进行改进从而提高准确率,也可以尝试使用其他算法,如逻辑回归等,建立新的模型进行比较。
8.参考资料
解读美国第一家网贷平台Prosper
基于python的网贷平台Prosper数据分析
网贷平台Prosper2005~2014贷款数据分析(一)