本文同步于个人Github博客:https://github.com/johnnian/Blog/issues/34,欢迎关注并交流。
分布式日志收集系统(Flume-NG)
应用场景
在生产环境中,有若干台服务器,每台服务器都部署着一套生产版本系统,为了方便分析与查看日志,需要统一收集日志。
目前市面上,有不少开源的日志收集系统,如强大的ELK(ElasticSearch, Logstash, Kibana)、Flume-NG等。ELK提供日志检索的索引、强大的图形界面,而Flume-NG比较小巧,对于小项目用起来比较简单,所以这里选择用Flume-NG:
- 日志采集客户端: Flume-NG
- 消息传递: Kafka
网络拓扑图如下:
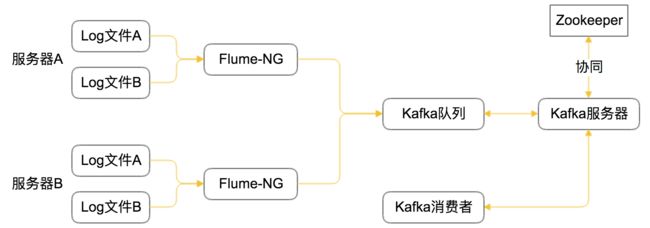
如图所示,服务器A、B 上的日志文件,被对应的Flume-NG客户端收集后,传递给 Kafka 消息队列,最终由Kafaka客户端消费(存储数据库,或者写入到本地文件中)
安装步骤
1、Kafaka安装与配置
步骤1: 下载Kafka安装包
点击下载Kafka
➜ wget http://mirrors.hust.edu.cn/apache/kafka/0.11.0.1/kafka_2.11-0.11.0.1.tgz
步骤2: 安装配置
这里的Zookeeper、Kafka暂时都是配置单点,如果想要配置集群,请参考:
- Zookeeper安装部署(单点/集群)
##### 解压
➜ tar -zxvf kafka_2.11-0.11.0.1.tgz
➜ cd kafka_2.11-0.11.0.1
##### 配置启动Zookeeper, 包括端口、集群等, 默认端口2181
➜ vi config/zookeeper.properties
➜ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
➜ netstat -an | grep 2181
tcp46 0 0 *.2181 *.* LISTEN
##### 配置启动Kafka,默认端口9092
➜ vi config/server.properties
# 因为部署Kafka单点,需要放开配置
advertised.listeners=PLAINTEXT://127.0.0.1:9092
##### 后台进程的形式启动kafka
➜ nohup ./bin/kafka-server-start.sh config/server.properties &
2、Flume-NG安装与配置
步骤1: 下载安装包
➜ wget http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
➜ tar -zxvf apache-flume-1.7.0-bin.tar.gz
➜ cd apache-flume-1.7.0-bin
步骤2: 配置与启动
➜ cp conf/flume-conf.properties.template conf/flume-conf.properties
➜ vi conf/flume-conf.properties
下面是我的示例配置文件:具体的配置选项,可以参考官网的配置说明
agent.sources = s1 s2
agent.sinks = k1 k2
agent.channels = c1 c2
#配置source
agent.sources.s1.type = exec
agent.sources.s1.command = tail -F /Users/Johnnian/tmp/logs/test1.log
agent.sources.s1.channels = c1
agent.sources.s2.type = exec
agent.sources.s2.command = tail -F /Users/Johnnian/tmp/logs/test2.log
agent.sources.s2.channels = c2
#配置channel
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000000
agent.channels.c1.transactionCapacity = 100
agent.channels.c2.type = memory
agent.channels.c2.capacity = 1000000
agent.channels.c2.transactionCapacity = 100
#配置sinks
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.kafka.bootstrap.servers = 127.0.0.1:9092
agent.sinks.k1.kafka.topic = test1
agent.sinks.k1.channel = c1
agent.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k2.kafka.bootstrap.servers = 127.0.0.1:9092
agent.sinks.k2.kafka.topic = test2
agent.sinks.k2.channel = c2
Flume-NG, 基本概念可以看下面的图:
每个JVM只能有一个 Flume-NG的Agent,每个agent由: sources、channels、sinks 三个模块组成;
1个source --> 1个channel --> N个sinks
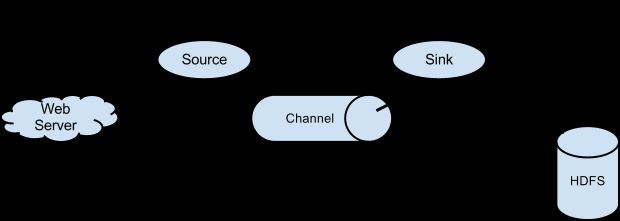
日志收集的思路是:
- Source 用 Linux的 tail 命令抓取log的变化;
- Sink 使用KafkaTopic,把log中变化的内容发送到Kafka;
- 编写Kafka消费者代码,将日志写入到指定的位置;
步骤3: 启动 Flume-NG
➜ nohup ./bin/flume-ng agent -n agent -c conf -f conf/flume-conf.properties &
3、日志收集消费者安装与配置
日志收集客户端,把收集到的日志写入指定位置,如 使用logback每天滚动写入日志文件,或者写入 MongoDB、HBase等位置;
这里我使用 Springboot + logback + spring-kafka ,写入日志文件,具体Demo代码放在这里: 点击查看, 可以修改对应的Topic、日志路径等。
使用方法: 需要先安装Maven
➜ mvn clean install
➜ cd target
➜ java -jar flumelogger-1.0.0.jar
默认情况下,运行Springboot程序,在打包的时候会把所有的配置文件都打包到jar文件中,如果需要灵活更改配置,可以配置文件单独拷贝一份出来,放在jar包同一目录:
[root@0bf998fffd28 flumelogger]# tree
.
|-- application.properties
|-- flumelogger-1.0.0.jar
`-- logback-spring.xml
默认情况下,flumelogger-1.0.0.jar 会优先加载同目录下的application.properties,可以通过在 application.properties 文件中指定logback.xml的路径,就可以达到动态配置的效果:
[root@0bf998fffd28 flumelogger]# vi application.properties
logging.config=/root/flumelogger/logback-spring.xml
参考链接
- Flume 1.7.0 官方文档
- Kafak 官方文档