[toc]
事务介绍
四大特性ACID
1. 原子性(Atomicity)
2. 一致性(Consistency) //真正的老大
3. 隔离性(Isolation)
4. 持久性(Durability)
高并发的情况下,多个事务之间会出现问题:
1. 脏读(Dirty Read):事务A读取了事务B未提交的数据,并在这个基础上又做了其它操作。
2. 不可重复读(Unrepeatable Read): 事务A读取了事务B已提交的更改数据。
3. 幻读(Plantom Read)::事务A读取了事务B已提交的新增数据。
事务隔离级别
为了应对这些问题,隔离不同的事务,出现了事务隔离级别
1. READ_UNCOMMITTED
2. READ_COMMITTED
3. REPEATABLE_READ
4. SERIALIZABLE
从上往下,级别越来越高,安全性能越来越高,并发性能越来越差。
|事务隔离级别|脏读|不可重复读|幻读|
|---------|--|---|
|READ_UNCOMMITTED|允许|允许|允许|
|READ_COMMITTED|禁止|允许|允许|
|REPEATABLE_READ|禁止|禁止|允许|
|SERIALIZABLE|禁止|禁止|禁止|
JDBC也提供了这四类事务的隔离级别,默认的隔离级别对不同的数据库产品而言不一样。MySQL数据库默认隔离级别READ_COMMITTED 。
`DatabaseMetaData meta = DBUtil.getDataSource().getConnection().getMetaData();`
`int` `defaultIsolation = meta.getDefaultTransactionIsolation();`
java.sql.Connection类中可以查看所有的隔离级别。
Spring中的事务
事务的传播行为
- ** PROPAGATION_REQUIRED**
- ** RROPAGATION_REQUIRES_NEW**
- ** PROPAGATION_NESTED**
- ** PROPAGATION_SUPPORTS**
- ** PROPAGATION_NOT_SUPPORTED**
- ** PROPAGATION_NEVER**
- ** PROPAGATION_MANDATORY**
假设事务从方法 A 传播到方法 B,您需要面对方法 B,问自己一个问题:
方法 A 有事务吗?
1. 如果没有,就新建一个事务;如果有,就加入当前事务。这就是 PROPAGATION_REQUIRED,它也是 Spring 提供的默认事务传播行为,适合绝大多数情况。
2. 如果没有,就新建一个事务;如果有,就将当前事务挂起。这就是 RROPAGATION_REQUIRES_NEW,意思就是创建了一个新事务,它和原来的事务没有任何关系了。
- 如果没有,就新建一个事务;如果有,就在当前事务中嵌套其他事务。这就是 PROPAGATION_NESTED,也就是传说中的“嵌套事务”了,所嵌套的子事务与主事务之间是有关联的(当主事务提交或回滚,子事务也会提交或回滚)。
4. 如果没有,就以非事务方式执行;如果有,就使用当前事务。这就是 PROPAGATION_SUPPORTS,这种方式非常随意,没有就没有,有就有,有点无所谓的态度,反正我是支持你的。
5. 如果没有,就以非事务方式执行;如果有,就将当前事务挂起。这就是 PROPAGATION_NOT_SUPPORTED,这种方式非常强硬,没有就没有,有我也不支持你,把你挂起来,不鸟你。
6. 如果没有,就以非事务方式执行;如果有,就抛出异常。这就是 PROPAGATION_NEVER,这种方式更猛,没有就没有,有了反而报错,确实够牛的,它说:我从不支持事务!
7. 如果没有,就抛出异常;如果有,就使用当前事务。这就是 PROPAGATION_MANDATORY,这种方式可以说是牛逼中的牛逼了,没有事务直接就报错,确实够狠的,它说:我必须要有事务!
- 来源: http://www.importnew.com/21603.html#comment-514576
spring又提供了其它的方法:
****事务超时(Transaction Timeout)****:为了解决事务时间太长,消耗太多的资源,所以故意给事务设置一个最大时常,如果超过了,就回滚事务。
****只读事务(Readonly Transaction)****:为了忽略那些不需要事务的方法,比如读取数据,这样可以有效地提高一些性能。
spring声明式事务
基于TransactionProxyFactoryBean的方式
这种方式并不经常使用,需要对每个类都需要配置代理类,维护开发比较麻烦。
1 配置文件中配置事务管理器
2 配置业务层代码
PROPAGATION_REQUIRED
3. 注入代理类: "accountServiceProxy"
基于AspectJ的xml配置方式。
应用较广泛
1 配置事务管理器
2 配置事务的通知
3 配置切面
基于注解的事务管理
1 配置事务管理器
2 开启注解事务
3 在业务层上添加注解
@Transactional(propagation=Propagation.REQUIRED)
分布式事务
分布式事务的原因:
1. 分库,分表。当数据库单表一年产生的数据超过1000W,那么就要考虑分库分表,具体分库分表的原理在此不做解释,以后有空详细说,简单的说就是原来的一个数据库变成了多个数据库。这时候,如果一个操作既访问01库,又访问02库,而且要保证数据的一致性,那么就要用到分布式事务
2. 应用的SOA化。 所谓的SOA化,就是业务的服务化。比如原来单机支撑了整个电商网站,现在对整个网站进行拆解,分离出了订单中心、用户中心、库存中心。对于订单中心,有专门的数据库存储订单信息,用户中心也有专门的数据库存储用户信息,库存中心也会有专门的数据库存储库存信息。这时候如果要同时对订单和库存进行操作,那么就会涉及到订单数据库和库存数据库,为了保证数据一致性,就需要用到分布式事务。
本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
分布式事务的应用场景
1. 支付
2. 在线下单
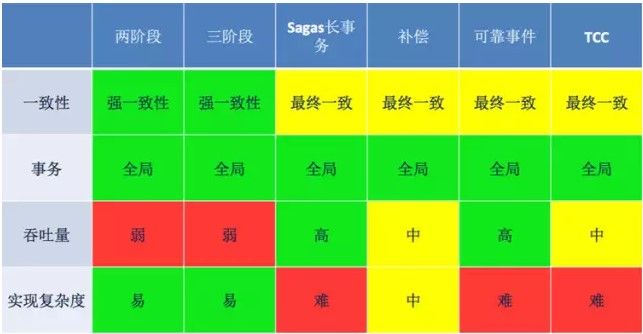
常见的分布式事务解决方案
基于XA协议的两阶段提交
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。
其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。总的来说,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
消息事务+最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,具体原理如下:
1. A系统向消息中间件发送一条预备消息
2. 消息中间件保存预备消息并返回成功
3. A执行本地事务
4. A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
步骤一出错,则整个事务失败,不会执行A的本地操作
步骤二出错,则整个事务失败,不会执行A的本地操作
步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
-
步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
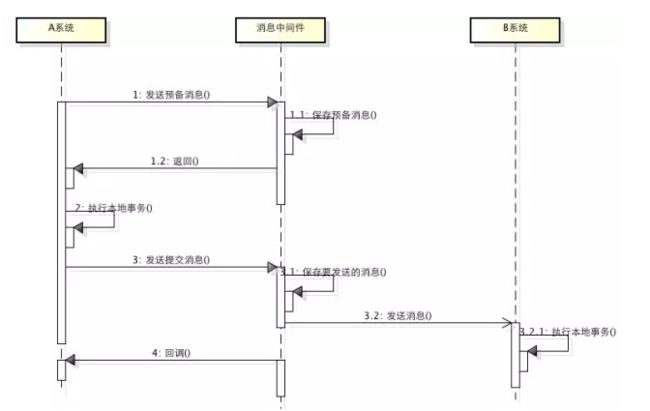 image.png
image.png
虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
TCC编程模式
所谓的TCC编程模式,也是两阶段提交的一个变种。TCC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
分布式事务