预备知识
- Trie(字典树)
- KMP字符串匹配算法
AC自动机求解问题的类型
一句话概括就是:多模匹配。
KMP求解的问题是在一个字符串S中找到字符串T出现的位置,例如:在"Iloveyou"中寻找字符串"ove"此时称S为目标串,称T为模式串。因此KMP属于单模匹配。
多模匹配顾名思义就是要和目标串匹配的模式串不止一个。这时就要请出来AC自动机解决这个问题。
图文介绍
先上个图。之后结合这幅图来讲。
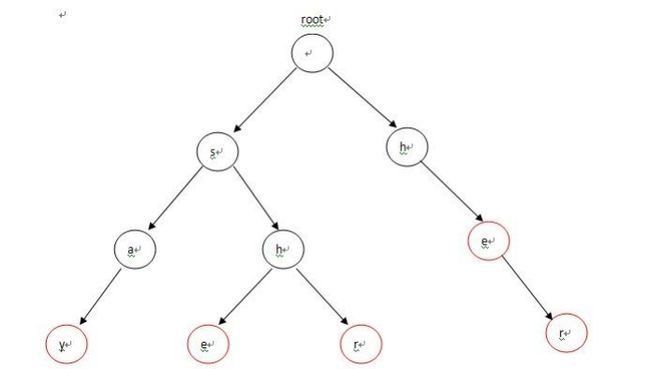
假设模式串集合为{"say", "she", "shr", "he", "her"}
目标串是"yasherhs"。
建立AC自动机的方法就是把所有模式串放到一个Trie上,如上图。
但是相对于一般字典树的两个基本属性:
1.son[x]表示点x的儿子集合。
2.data[x]=k表示root到x所表示的字符串出现k次。
还有一个神奇的属性:
3.fail[x]表示x的失配指针。具体含义就是(建议看了下面的图再来理解这句话):设root到x表示的字符串是S,root到fail[x]表示的字符串是T,那么T就应该是 S最长的后缀。
下图虚线展示了fail指针的连接方式:

例如对于字符串"shr",其最长的后缀在Trie里没有出现,所以其fail指针指向root。对于字符串"she",其最长的后缀"he"出现在Trie中,于是其就fail指针就指向'e'那个点。
那么这个fail指针究竟是何方神圣,有何神通呢?我们回想KMP进行匹配的过程:next[i]表示模式串前i个字符中,最长的后缀=前缀的长度。现在我们的模式串不止一个了,因此其fail指针还有可能指向别的字符串上的点。这样就相当于把原来一个模式串的next扩展到了多个模式串的next,意义就扩展为所有的模式串的前i个字符中最长的后缀=前缀的长度。正确性就可以保证了。至于复杂度的证明方式和kmp类似。
现在的问题是,如何求fail指针?联系kmp的next数组的意义,容易发现root的每个儿子的fail都指向root(前缀和后缀是不会包含整个串的)。也就是上图中root所连的's'和'h'的fail都指向root。若已经求得'sh'所在点的fail,我们来考虑如何求'she'所在点的fail。根据'sh'所在点的fail得到'h'是'sh'的最长后缀,而'h'又有儿子'e',因此'she'的最长后缀应该是'he',其fail指针就指向'he'所在点。
概括AC自动机求fail指针的过程:
1.对整个字典树进行bfs(宽度优先搜索)遍历。
2.若当前搜索到点x,那么对于x的第i个儿子(也就是代表字符i的儿子),一直往x的fail跳,直到跳到某个点也有i这个儿子,x的第i个儿子的fail就指向这个点的儿子i。
上述过程类似于kmp求next的过程,可以根据代码理解。
过程getfail用于求出AC自动机的fail指针(C++版):
struct node
{
node* fail; node* son[26];
int data;
void init()
{
data = 0, fail = NULL;
memset(son, 0, sizeof(son));
}
};
node* root;
int head, tail;
node* que[30007];
void getfail()
{
head = 1, que[tail = 1] = root; //数组实现队列
while (head <= tail)
{
node* x = que[head++];
for (int i = 0; i < 26; i++)
if (x->son[i]) //x有儿子i
{
if (x == root) x->son[i]->fail = root; //x是root,其儿子的fail都指向root
else
{
node* tmp = x->fail;
while (tmp) //一直往fail跳
{
if (tmp->son[i]) { x->son[i]->fail = tmp->son[i]; break; } //这个点也有儿子i
tmp = tmp->fail;
}
if (!tmp) x->son[i]->fail = root;
}
que[++tail] = x->son[i];
}
}
}
求出来fail指针后,我们就很容易依照kmp的匹配过程写出AC自动机的匹配过程了:
1.若当前匹配到目标串的第i个字符。判断当前在Trie上的点有没有表示字符i的儿子,有就跳过去。如果没有就一直往fail跳,直到有一个点有表示字符i的儿子为止。如果没有任何一个点有表示字符i的儿子,那就重新回到根。
2.开一个临时点tmp,并从tmp一直往tmp的fail跳,若root到tmp形成了一个单词(模式串),就加上tmp的data。
还是看代码吧(晕):
int match(char *s)
{
int ret = 0;
node* now = root;
while (*s != '\0')
{
while (!now->son[*s - 'a'] && now != root) now = now->fail;
now = now->son[*s - 'a'];
if (!now) now = root;
node* tmp = now;
while (tmp != root) ret += tmp->data, tmp = tmp->fail;
s++;
}
return ret;
}
汇总一下AC自动机的代码(指针版):
#include
#include
#include
struct node
{
node* fail; node* son[26];
int data;
void init()
{
data = 0, fail = NULL;
memset(son, 0, sizeof(son));
}
};
node* root;
int n, m;
char str[2000007];
void insert(char* s)
{
node* now = root;
while (*s != '\0')
{
if (!now->son[*s - 'a']) now->son[*s - 'a'] = new node, now->son[*s - 'a']->init();
now = now->son[*s - 'a'];
s++;
}
now->data++;
}
int head, tail;
node* que[30007];
void getfail()
{
head = 1, que[tail = 1] = root;
while (head <= tail)
{
node* x = que[head++];
for (int i = 0; i < 26; i++)
if (x->son[i])
{
if (x == root) x->son[i]->fail = root;
else
{
node* tmp = x->fail;
while (tmp)
{
if (tmp->son[i]) { x->son[i]->fail = tmp->son[i]; break; }
tmp = tmp->fail;
}
if (!tmp) x->son[i]->fail = root;
}
que[++tail] = x->son[i];
}
}
}
int match(char *s)
{
int ret = 0;
node* now = root;
while (*s != '\0')
{
while (!now->son[*s - 'a'] && now != root) now = now->fail;
now = now->son[*s - 'a'];
if (!now) now = root;
node* tmp = now;
while (tmp != root) ret += tmp->data, tmp = tmp->fail;
s++;
}
return ret;
}
int main()
{
root = new node, root->init();
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++) scanf("%s", str), insert(str);
getfail();
scanf("%s", str);
printf("%d\n", match(str));
return 0;
}
上一道例题加强理解:
3172. 【GDOI2013模拟4】贴瓷砖
Time Limits: 4000 ms Memory Limits: 524288 KB
Description
A镇的主街是由N个小写字母构成,镇长准备在上面贴瓷砖,瓷砖一共有M种,第i种上面有Li个小写字母,瓷砖不能旋转也不能被分割开来,瓷砖只能贴在跟它身上的字母完全一样的地方,允许瓷砖重叠,并且同一种瓷砖的数量是无穷的。
问街道有多少字母(地方)不能被瓷砖覆盖。
Input
第一行输入街道长度N(1<=N<=300,000)。
第二行输入N个英文小写字母描述街道的情况。
第三行输入M(1<=M<=5000),表示瓷砖的种类。
接下来M行,每行描述一种瓷砖,长度为Li(1<=Li<=5000),全部由小写字母构成。
Output
输出有多少个地方不能被瓷砖覆盖。
Sample Input
输入1:
6
abcbab
2
cb
cbab
输入2:
4
abab
2
bac
baba
输入3:
6
abcabc
2
abca
cab
Sample Output
输出1: 2
输出2: 4
输出3: 1
数据范围:N(1<=N<=300,000)
首先对于所有模式串建立AC自动机,将目标串放到上面匹配。若目标串在第i位时成功匹配,那么就把所有成功匹配的子串全部打上标记,最后没打标记的就是无法被覆盖的部分。但是这样子效率是很低的,因为我们把每个成功匹配的子串都打了标记,实际上只需要对最长的那个子串打标记即可。而且打标记是对于一个区间的,直接暴力标记可能超时(尽管已经有人水过去了)。正确的做法是使用差分数组,O(1)区间加法,最后O(n)求出每个位置的值。
但是这样还有一个问题,在上面AC自动机的这个过程中:
node* tmp = now;
while (tmp != root) ret += tmp->data, tmp = tmp->fail;
这样跳本来是为了保证目标串能够被多个模式串匹配到,可我们仅仅关心其中最长的一个。因此需要给每个点加一个属性mx[x]表示从x一直往fail[x]跳,路径上最长的单词长度是多少。这是可以预处理的。在字典树上,一个点的深度就是root到这个点形成的字符串的长度。
代码:
#include
#include
#include
#include
using namespace std;
const int N = 3e5 + 7, M = 5e3 + 7, L = 807; //卡内存的题目,不要开满空间
int root, tot, fail[M * L], son[M * L][26];
short data[M * L], dep[M * L], mx[M * L];
int n, m, c[N];
char str[N], str1[M];
void insert(char *s)
{
int now = root;
while (*s != '\0')
{
if (!son[now][*s - 'a']) son[now][*s - 'a'] = ++tot;
now = son[now][*s - 'a'], s++;
}
data[now]++; //该处形成了一个模式串
}
queue que; //STL省空间
void getfail() //求fail指针
{
que.push(root);
while (!que.empty())
{
int x = que.front(); que.pop();
for (int i = 0; i < 26; i++)
if (son[x][i])
{
dep[son[x][i]] = dep[x] + 1;
if (x == root)
fail[son[x][i]] = root, mx[son[x][i]] = data[son[x][i]] ? 1 : 0; //对于根的每个儿子mx,如果其形成了模式串就为1,否则为0
else
{
int tmp = fail[x];
while (tmp)
{
if (son[tmp][i]) { fail[son[x][i]] = son[tmp][i]; break; }
tmp = fail[tmp];
}
if (!tmp) fail[son[x][i]] = root;
if (data[son[x][i]]) mx[son[x][i]] = dep[son[x][i]]; //x的这个儿子形成了一个模式串,由于fail指针是往深度比x更小的点跳的,因此mx就是x这个儿子的深度
else mx[son[x][i]] = mx[fail[son[x][i]]]; //不然就是其fail指针的mx
}
que.push(son[x][i]);
}
}
}
void match()
{
int now = 1;
for (int i = 1; i <= n; i++)
{
while (!son[now][str[i] - 'a'] && now != root) now = fail[now];
now = son[now][str[i] - 'a'];
if (!now) now = root;
c[i + 1]--, c[i - (mx[now]) + 1]++; //差分数组上打标记
}
}
int main()
{
root = tot = 1;
scanf("%d%s%d", &n, str + 1, &m);
while (m--) scanf("%s", str1), insert(str1);
getfail(), match();
int ans = 0;
for (int i = 1, sum = 0; i <= n; i++) { sum += c[i]; if (sum <= 0) ans++; } //统计答案
printf("%d\n", ans);
return 0;
}