原文:https://www.raywenderlich.com/174-beginning-machine-learning-with-scikit-learn
作者: Mikael Konutgan 2018年2月12日·中级·文章·15分钟
在这个使用scikit-learn教程的Beginning Machine Learning中,您将学习如何创建自己的CoreML模型并将其集成到iOS应用程序中。
- Swift 4,iOS 11,Xcode 9

借助iOS 11,Apple发布了Core ML框架,允许您将经过培训的机器学习模型集成到您的应用程序中。Apple提供了一种工具,可将许多模型格式转换为其.mlmodel格式。但是,您如何创建和培训机器学习模型?在本教程中,您将通过使用scikit-learn创建自己的机器学习模型,并通过Apple的Core ML框架将其集成到iOS应用程序中。在此过程中,您将学习如何:
- 在macOS上安装流行的Python机器学习包。
- 创建预测机器学习模型。
- 将这些模型集成到您自己的iOS应用程序中。
入门
下载入门项目,然后构建并运行它。

该应用程序有3个滑块,每个广告预算一个:电视广告,广播广告和报纸广告。在过去几年中,您已经记录了广告支出的金额(以数千美元计算)以及您的销售额(以数千个单位显示)。
现在,您希望构建和培训机器学习模型,以帮助根据各种广告预算方案预测您的销售结果。之后,您希望将模型方便地打包到iOS应用程序中,以便您和您的团队可以即时检查结果。
在本教程中,您将构建此模型并使用Core ML将其集成到应用程序中,以便在移动任何滑块时,销售预测将更新。
但首先,您需要安装必要的Python工具。
安装Anaconda
Anaconda是一个开源发行版。它包含数千个预配置的软件包,使用户能够使用Python中最流行的数据科学和机器学习工具快速启动并运行。
在本教程中,您只会涉及Anaconda所提供的内容,因此我建议您查看anaconda.org以了解有关它的更多信息。
要安装Anaconda,请访问他们的下载链接,然后下载 Python 2.7版本; Apple coremltools只使用Python 2。
下载后,运行安装程序。继续阅读“简介”,“自述文件”和“许可证”,直到进入“ 目标选择”步骤。安装Anaconda最简单,最干净的方法是进入本地项目。为此,请选择在特定磁盘上安装...,选择正确的磁盘,单击选择文件夹...,导航到您选择的用户目录,然后创建一个名为Beginning-Machine-Learning的新文件夹。

注意:如果安装程序跳过“ 目标选择”步骤,请单击“ 安装类型”步骤上的“ 更改安装位置...” 以返回该目标。
选择目标后,单击继续,然后单击安装,开始安装过程。这应该需要大约10分钟。
要验证安装,请打开终端和cd(更改目录)到安装anaconda 的Beginning-Machine-Learning文件夹中。然后,输入以下命令:
./anaconda2/bin/python --version
您将看到使用Python 2版本的成功响应,如下所示:

恭喜!Python与其最重要的数据科学/机器学习包一起安装。
安装Core ML社区工具
coremltools一个开源的苹果项目日后会使用到scikit学习模型转化成可以在iOS应用使用格式的一个工具。
python 没有安装 coremltools。
在终端中,从Beginning-Machine-Learning目录运行以下命令:
./anaconda2/bin/pip install -U coremltools

Jupyter Notebook
安装好所有东西后,您就可以开始使用Jupyter Notebook; 将Jupyter Notebook当作为类似 Swift Playgrounds 的 Python 版本。
在Beginning-Machine-Learning目录中,在Terminal中输入以下两个命令:
mkdir notebooks
./anaconda2/bin/jupyter notebook notebooks
在这里,您首先创建了一个名为notebooks的新文件夹。然后,您从该新文件夹启动了Jupyter Notebook Server。
您的默认浏览器应该打开Jupyter Notebook页面。如果没有,您将在终端中看到页面的URL,以便您可以手动打开它; 看起来应该是这样的:http://localhost:8888/?token=7609a66aaffa819340a882f8ff88361db3f72667c07c764d。
现在您需要创建一个新Notebook。为此,请单击 “New”,然后单击 “Python 2”:
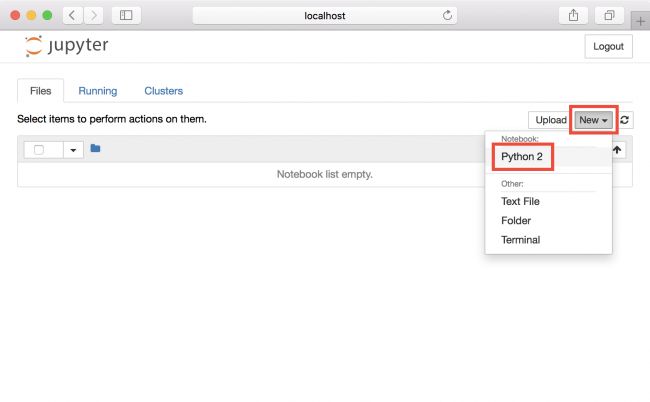
给新Notebook一个更好的名字。单击 File,然后 Rename...,并将名称更改为 Advertising:

单击软盘以保存更改。
注意:如果您在尝试保存Notebook时遇到问题,请确保您没有在页面上运行浏览器扩展程序; 广告拦截器之类的东西可能会导致问题。
Notebook很像Swift Playgrounds。您可以输入Python表达式,然后按Control-Enter执行它们并查看内联结果。
尝试键入类似的内容2 + 2并点击Control-Enter以获得结果。此外,尝试使用Shift + Enter插入新单元格,以及执行当前单元格。
您还可以像在普通Python文件中一样创建函数和类:

如果要进一步了解界面,请通过选择菜单栏中的“ 帮助”来查看“ 用户界面 ”。
准备就绪后,按住Shift键并单击每个单元格左侧的空白区域,然后使用dd快捷方式删除您在获取任何内容时所创建的任何单元格。
使用干净的Notebook,您已准备好进行下一步:创建线性回归模型以预测广告收入。
训练和验证线性回归模型
下载此示例广告数据并将csv文件放入您的notebooks文件夹中。
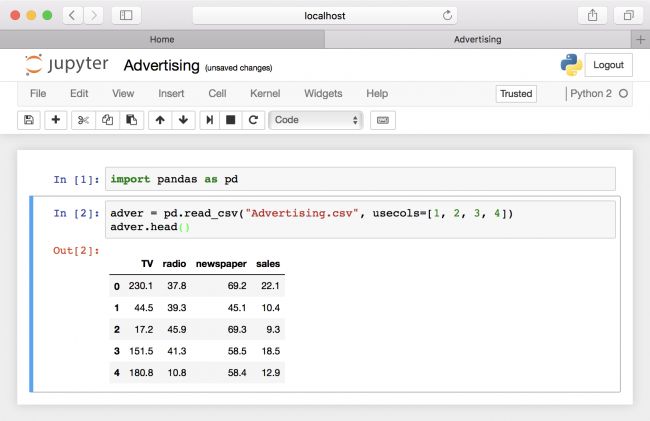
现在,在Notebook的第一个单元格中输入以下代码:
import pandas as pd
使用Shift-Enter运行单元格。然后,将以下行添加到第二个单元格并运行该单元格:
adver = pd.read_csv("Advertising.csv", usecols=[1, 2, 3, 4])
adver.head()
首先,您导入了[pandas](https://pandas.pydata.org/)库。pandas是一个数据分析库,有许多工具可以导入,清理和转换数据。
实际数据不像样本广告数据那样随时可用。您将使用pandas它来形成用作机器学习模型的输入。在上面的代码中,您使用它来导入csv文件并将其转换为pandas 的格式 - 数据框,这是一种标准格式,大多数Python机器学习库(包括scikit-learn)将接受作为输入。
您应该看到Notebook中数据的前几行。每行代表一个数据点:电视,广播和报纸广告花费了多少,以及特定时期的销售额。
首先,您需要从输出列中分离出数据中的输入列。按照惯例,这些被分别称为X和y。在新单元格中输入以下代码并运行它:
X, y = adver.iloc[:, :-1], adver.iloc[:, -1]
要正确训练和验证模型,您需要将数据拆分为两组:
- 训练集:用于训练模型。这些样本用作机器学习算法的输入。
- 测试集:模型尚未见到,该集用于测试或验证模型。由于测试集的销售已经知道且独立于训练集,因此测试集可用于获得使用训练集训练模型的程度的分数。
幸运的是,scikit-learn提供了一个易于使用的功能,可以将数据分成训练和测试集。将以下内容添加到Notebook中的第一个单元格中,在pandas导入下:
import sklearn.model_selection as ms
确保单元格具有焦点,然后使用Control-Enter运行它。现在,在Notebook的末尾,将以下内容键入新单元格并运行该单元格:
X_train, X_test, y_train, y_test = ms.train_test_split(X, y, test_size=0.25, random_state=42)

该函数返回4个值:用于训练和测试的输入,以及用于训练和测试的输出。该函数采用以下参数:
- X:我们从Advertisments.csv示例数据中读取的输入(支出金额)。
- y:来自样本数据的输出(销售数量)。
- test_size:用于测试的数据百分比,通常设置为25%到40%之间。
- random_state:如果没有输入,该函数将随机选择用于列车和测试样本的行。在生产中,这正是您想要的,但对于像这样的开发和教程,获得一致的结果非常重要,这样您就可以知道出现问题时的位置。
在此处详细了解该train_test_split功能。
现在,数据按照您希望的方式进行拆分,现在是时候根据该数据创建和训练线性回归模型了。
注意:查看这个精彩的教程,了解线性回归的工作原理和原因。
在包含pandas和sklearn.model_selection导入的单元格中,附加以下导入并运行单元格:
import sklearn.linear_model as lm
然后,在Notebook的底部,将以下行输入新单元格并运行它:
regr = lm.LinearRegression() # 1
regr.fit(X_train, y_train) # 2
regr.score(X_test, y_test) # 3

- 在这里,您将创建一个线性回归模型对象(
regr)。 - 对于scikit-learn模型,该
fit方法始终训练模型,它接收训练输入列和输出列。 - 分数决定了模型的优秀程度。大多数scikit-learn模型都有一个将测试数据作为参数的分数方法。在线性回归的情况下,分数可以让您了解预测输出与测试数据的实际输出的接近程度。
你应该看到得分为0.89。
现在,您可以使用线性回归对象来预测新输入值的销售额。为此,请将以下内容添加到另一个单元格中并运行它:
X_new = [[ 50.0, 150.0, 150.0],
[250.0, 50.0, 50.0],
[100.0, 125.0, 125.0]]
regr.predict(X_new)

您应该看到以下输出:
array([ 34.15367536, 23.83792444, 31.57473763])
因此,如果您花费5万美元,15万美元和15万美元用于三个平台的营销,您可以预期销售34,150台!
您用于训练线性回归的三个步骤与绝大多数scikit-learn模型需要使用的步骤完全相同。
接下来,您将使用相同的三种方法来创建和训练支持向量机(SVM)模型。SVM是最流行的机器学习工具之一。因为它们是更复杂的模型,所以需要更长的时间才能正确训练和调整。
训练和验证支持向量机模型
将另一个导入添加到第一个单元格并重新运行它:
import sklearn.svm as svm
然后,将以下每个代码块添加到单元格中并运行它们:
svr = svm.LinearSVR(random_state=42)
svr.fit(X_train, y_train)
svr.score(X_test, y_test)
svr.predict(X_new)

您应该看到0.867的分数和一组新的预测。您将看到SVM预测相似,但完全不同。支持向量机以不同的方式工作,可能适合您的数据,也可能不适合您的数据。机器学习中最难的部分之一是为该模型找到合适的模型和正确的参数,以获得最佳结果。
如果您想了解有关SVM的更多信息,请查看scikit-learn.org上的文档。
将模型转换为Apple的Core ML格式
建立模型后,就可以将其导出到Core ML了。您已coremltools在本教程的开头安装,因此请继续将导入添加到第一个单元格中,并最后一次运行:
import coremltools
现在,在Notebook的最后一个单元格中,输入以下代码并运行它:
input_features = ["tv", "radio", "newspaper"]
output_feature = "sales"
model = coremltools.converters.sklearn.convert(regr, input_features, output_feature)
model.save("Advertising.mlmodel")
该coremltools.converters.sklearn.convert函数采用以下参数:
- 要转换的scikit-learn模型。
- Xcode将用于生成Swift类接口的输入和输出功能名称。
最后,save()获取导出的文件名。保存模型时,应确保使用.mlmodel扩展名。
完成的Notebook看起来像这样:
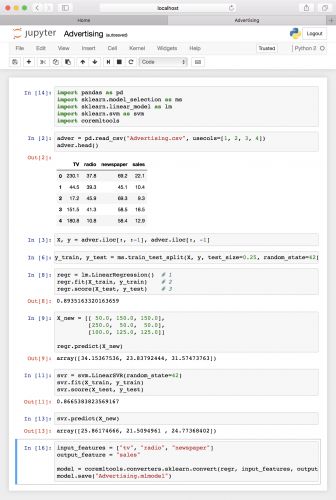
如果查看存储Notebook的文件夹,您将看到名为Advertising.mlmodel的新文件。这是Core ML模型文件,您可以放入Xcode!你接下来会这样做。
将Core ML模型集成到您的应用程序中
回到之前构建并运行的入门项目,将Advertising.mlmodel从notebooks目录拖到Xcode中的Project导航器中。

出现提示时,选中“ 根据需要复制项目”,“ 创建组和广告”框,然后单击“ 完成”。将模型导入Xcode项目后,在Project导航器中单击它,您将看到有关它的一些信息:
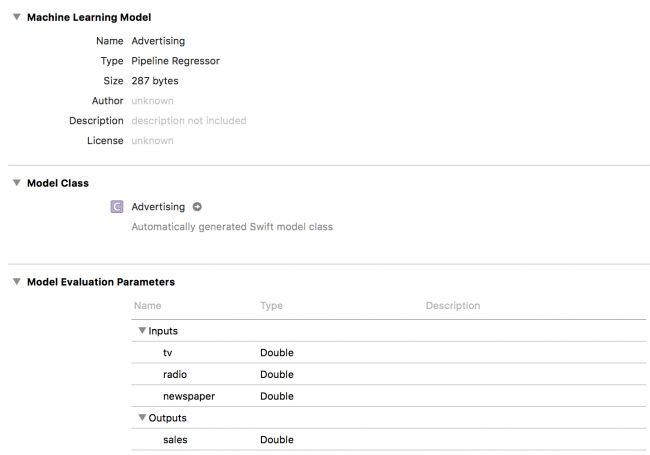
注意:如果您想知道为什么这个屏幕看起来有点乏味,那是因为您在将内容转换为.mlmodel时没有添加任何其他元数据。如果要执行此操作,请查看Model Interface文档以查看可以提供的元数据。
片刻之后,您应该看到自动生成的Swift模型类。点击上面的小箭头将带您进入Xcode从中生成的界面.mlmodel。
打开ViewController.swift并在下面添加一个新属性numberFormatter:
private let advertising = Advertising()
然后,向下滚动到sliderValueChanged(_:),并替换以下行:
let sales = 0.0
使用以下代码:
let input = AdvertisingInput(tv: tv, radio: radio, newspaper: newspaper)
guard let output = try? advertising.prediction(input: input) else {
return
}
let sales = output.sales
类似于scikit-learn的predict()方法,Core ML模型有一个prediction方法,它接受一个输入结构并返回一个输出结构,这两个结构都是Xcode之前生成的。
构建并运行应用程序。请注意每当您更改其中一个输入参数时,销售预测是如何更新的!

然后去哪儿?
您可以从此处下载完整的iOS应用程序和Jupyter Notebook。
请务必查看scikit-learn文档,特别是选择正确估算器的流程图。scikit-learn中的所有估算器都遵循相同的API,因此您可以尝试许多不同的机器学习算法来找到最适合您的用例的算法。
如果您想了解有关其他ML库的更多信息,请查看我们的Keras和Core ML入门机器学习教程。
另请参阅此Python数据科学手册,其中包含有关机器学习的部分以及更多算法。