方差分析主要通过F检验来进行效果评测,若治疗方案的F检验显著,则说明检验样本组间均值不同。
ANOVA模型拟合
从函数形式上看,ANOVA和回归方法都是广义线性模型的特例。因此回归分析章节中提到的lm()函数也能分析ANOVA模型。不过,在这个章节中,我们基本使用aov()函数。最后,会提供了个lm()函数的例子。
aov()函数
aov()函数的语法为aov(formula, data=dataframe)。下表列举了表达式可以使用的特殊符号。
| 符号 | 用途 |
|---|---|
| ~ | 分隔符号,左边为响应变量(因变量),右边为解释变量(自变量) |
| : | 表示预测变量的交互项 |
| * | 表示所有可能交互项的简洁方式 |
| ^ | 表示交互项达到某个次数 |
| . | 表示包含除因变量外的所有变量 |
下面是常见研究设计的表达式
| 设计 | 表达式 |
|---|---|
| 单因素ANOVA | y ~ A |
| 含单个协变量的单因素ANOVA | y ~ x + A |
| 双因素ANOVA | y ~ A * B |
| 含两个协变量的双因素ANOVA | y ~ x1 + x2 + A * B |
| 随机化区组 | y ~ B + A (B是区组因子) |
| 单因素组内ANOVA | y ~ A + Error(subject/A) |
| 含单个组内因子(W)和单个组间因子的重复测量ANOVA | y ~ B * W + Error(Subject/W) |
表达式中各项的顺序
当
因子不止一个,并且是非平衡设计;
存在协变量
两者之一时,等式右边的变量都与其他变量相关。此时,我们无法清晰地划分它们对因变量的影响。
例如,对于双因素方差分析,若不同处理方式中的观测数不同,那么模型y ~ A*B与模型y ~ B*A的结果不同。
R默认类型I(序贯型)方法计算ANOVA效应(类型II和III分别为分层和边界型,详见R实战(第2版)202页)。R中的ANOVA表的结果将评价:
- A对y的影响
- 控制A时,B对y的影响
- 控制A和B的主效应时,A与B的交互影响。
一般来说,越基础性的效应需要放在表达式前面。
car包的Anova()函数提供了三种类型方法,若想与其他软件(如SAS SPSS)提供的结果保持一致,可以使用它,细节可参考helo(Anova, package="car")。
单因素方差分析
单因素方法分析中,你感兴趣的是比较分类因子定义的两个或多个组别中的因变量均值。以multcomp包中cholesterol数据集为例(包含50个患者接收5种降低胆固醇疗法的一种,前三种是同样的药物不同的用法,后二者是候选药物)。哪种药物疗法降低胆固醇最多呢?
> library(mvtnorm)
> library(survival)
> library(TH.data)
> library(MASS)
> library(multcomp)
> attach(cholesterol)
> table(trt)
trt
1time 2times 4times drugD drugE
10 10 10 10 10
> aggregate(response, by=list(trt),FUN=mean)
Group.1 x
1 1time 5.78197
2 2times 9.22497
3 4times 12.37478
4 drugD 15.36117
5 drugE 20.94752
> aggregate(response, by=list(trt),FUN=sd)
Group.1 x
1 1time 2.878113
2 2times 3.483054
3 4times 2.923119
4 drugD 3.454636
5 drugE 3.345003
> fit <- aov(response ~ trt)
> summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
trt 4 1351.4 337.8 32.43 9.82e-13 ***
Residuals 45 468.8 10.4
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> library(gplots)
载入程辑包:‘gplots’
The following object is masked from ‘package:stats’:
lowess
> plotmeans(response ~ trt, xlab = "Treatment", ylab = "Response", main = "Mean Plot \nwith 95% CI")
> detach(cholesterol)
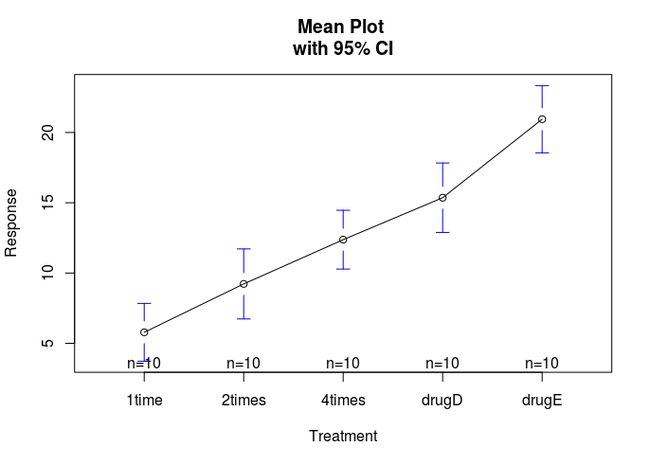
从结果可以看到,均值显示drugE降低胆固醇最多,各组标准差相对恒定。ANOVA对治疗方式的F检验非常显著,说明五种疗法的效果不同。
多重比较
虽然ANOVA对各种疗法的F检验表明五种药物的治疗效果不同,但是没有告诉你哪种疗法与其他疗法不同。多重比较可以解决这个问题。例如,TukeyHSD()函数提供了对各组均值差异的成对检验。
> TukeyHSD(fit)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = response ~ trt)
$trt
diff lwr upr p adj
2times-1time 3.44300 -0.6582817 7.544282 0.1380949
4times-1time 6.59281 2.4915283 10.694092 0.0003542
drugD-1time 9.57920 5.4779183 13.680482 0.0000003
drugE-1time 15.16555 11.0642683 19.266832 0.0000000
4times-2times 3.14981 -0.9514717 7.251092 0.2050382
drugD-2times 6.13620 2.0349183 10.237482 0.0009611
drugE-2times 11.72255 7.6212683 15.823832 0.0000000
drugD-4times 2.98639 -1.1148917 7.087672 0.2512446
drugE-4times 8.57274 4.4714583 12.674022 0.0000037
drugE-drugD 5.58635 1.4850683 9.687632 0.0030633
> par(las=2)
> par(mar=c(5,8,4,2))
> plot(TukeyHSD(fit))
第一个par语句用来旋转轴标签,第二个用来增大左边界的面积,可使标签摆放更美观。
成对比较图形如下图所示。
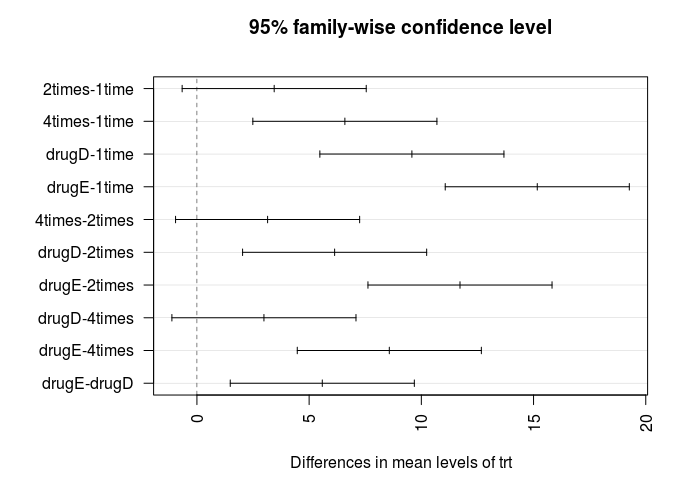
multcomp包中的
glht()函数提供了多重均值比较更为全面的方法,既适用于线性模型,也适用于广义线性模型。下面代码重现了上述检验结果,并用不同的图形进行展示。
> library(multcomp)
> par(mar=c(5,4,6,2))
> tur <- glht(fit, linfct=mcp(trt="Tukey"))
> plot(cld(tur, level=0.05), col="lightgrey")

par语句增大了顶部边界面积,cld()函数中的level选项设置了使用的显著水平。
有相同的字母的组说明均值差异不显著。
评估检验的假设条件
可以使用Q-Q图来检验正态性
> library(car)
> qqPlot(lm(response ~ trt, data = cholesterol), simulate=T, main="Q-Q Plot", labels=FALSE)

注意qqPlot需要lm()拟合。
方差齐次性检验:
例如,可以通过如下代码做Bartlett检验
> bartlett.test(response ~ trt, data = cholesterol)
Bartlett test of homogeneity of variances
data: response by trt
Bartlett's K-squared = 0.57975, df = 4, p-value = 0.9653
结果表明五组方差没有显著地不同。
注意,方差齐性分析对离群点非常敏感。可以利用car包outlierTest()检验。
单因素协方差分析
ANCOVA扩展了ANOVA,包含一个或多个定量的协变量。
下面的例子来自multcomp包中的litter数据集。怀孕的小鼠被分为四个小组,每组接受不同剂量的药物处理。产下幼崽的体重均值为因变量,怀孕时间为协变量。
> data(litter, package = 'multcomp')
> attach(litter)
> table(dose)
dose
0 5 50 500
20 19 18 17
> aggregate(weight, by=list(dose), FUN=mean)
Group.1 x
1 0 32.30850
2 5 29.30842
3 50 29.86611
4 500 29.64647
> fit <- aov(weight ~ gesttime + dose)
> summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
gesttime 1 134.3 134.30 8.049 0.00597 **
dose 3 137.1 45.71 2.739 0.04988 *
Residuals 69 1151.3 16.69
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
由于使用了协变量,我们可以通过effect包中的effects()函数计算调整的组均值。
> library(effects)
载入程辑包:‘effects’
The following object is masked from ‘package:car’:
Prestige
> effect("dose", fit)
dose effect
dose
0 5 50 500
32.35367 28.87672 30.56614 29.33460
同样,我们可以使用multcomp包对所有均值进行成对比较。另外,该包还可以用来检验用户自定义的均值假设。
下面代码清单可以用来检验未用药和其他三种药条件影响是否不同。
> library(multcomp)
> contrast <- rbind("no drug vs. drug" = c(3, -1, -1, -1))
> summary(glht(fit, linfct=mcp(dose=contrast)))
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: User-defined Contrasts
Fit: aov(formula = weight ~ gesttime + dose)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
no drug vs. drug == 0 8.284 3.209 2.581 0.012 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Adjusted p values reported -- single-step method)
对照c(3, -1, -1, -1)设定第一组和其他三组的均值进行比较。假设检验量t在p<0.05下显著。由此可以得出结论。详见help(glht)。
评估检验的假设条件
ANCOVA与ANOVA相同,都需要正态性和同方差假设,检验可以参考上一节。另外ANCOVA还假定回归斜率相同。
本例中,假定四个处理组通过怀孕时间来预测出生体重的回归斜率都相同。ANCOVA模型包含怀孕时间X剂量的交互项时,可以对回归斜率的同质性进行检验。交互效果若显著,则意味着时间和幼崽出生体重的关系依赖于药物剂量的水平。
fit2 <- aov(weight ~ gesttime*dose, data=litter)
summary(fit2)
HH包中的ancova()函数可以绘制因变量、协变量和因子之间的关系图。例如代码:
library(HH)
ancova(weight ~ gesttime + dose, data=litter)
用回归来做ANOVA
同样是之前比较五种降低胆固醇药物疗法的影响的例子,我们分别用两种不同的方法来做(aov()和lm())。
> library(multcomp)
载入需要的程辑包:mvtnorm
载入需要的程辑包:survival
载入需要的程辑包:TH.data
载入需要的程辑包:MASS
载入程辑包:‘TH.data’
The following object is masked from ‘package:MASS’:
geyser
> levels(cholesterol)
NULL
> levels(cholesterol$trt)
[1] "1time" "2times" "4times" "drugD" "drugE"
> fit.aov <- aov(response ~ trt, data=cholesterol)
> summary(fit.aov)
Df Sum Sq Mean Sq F value Pr(>F)
trt 4 1351.4 337.8 32.43 9.82e-13 ***
Residuals 45 468.8 10.4
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> fit.lm <- lm(response ~ trt, data = cholesterol)
> summary(fit.lm) # 因子的第一个水平变成了参考组,随后的变量都以它为标准
Call:
lm(formula = response ~ trt, data = cholesterol)
Residuals:
Min 1Q Median 3Q Max
-6.5418 -1.9672 -0.0016 1.8901 6.6008
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.782 1.021 5.665 9.78e-07 ***
trt2times 3.443 1.443 2.385 0.0213 *
trt4times 6.593 1.443 4.568 3.82e-05 ***
trtdrugD 9.579 1.443 6.637 3.53e-08 ***
trtdrugE 15.166 1.443 10.507 1.08e-13 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.227 on 45 degrees of freedom
Multiple R-squared: 0.7425, Adjusted R-squared: 0.7196
F-statistic: 32.43 on 4 and 45 DF, p-value: 9.819e-13