名词的概念:
1、cl_int clGetPlatformIDs (cl_uint num_entries,cl_platform_id *platforms,cl_uint *num_platforms)
Platform (平台):主机加上OpenCL框架管理下的若干设备构成了这个平台,通过这个平台,应用程序可以与设备共享资源并在设备上执行kernel。实际使用中基本上一个厂商对应一个Platform,比如Intel, AMD都是这样。
2、cl clGetDeviceIDs (cl_platform_id platform,cl_device_type device_type,cl_uint num_entries,
cl_device_id *devices,cl_uint *num_devices)
Device(设备):官方的解释是计算单元(Compute Units)的集合。举例来说,GPU是典型的device。Intel和AMD的多核CPU也提供OpenCL接口,所以也可以作为Device。
3、cl_context clCreateContext (const cl_context_properties *properties, cl_uint num_devices,
const cl_device_id *devices,
void ( CL_CALLBACK *pfn_notify)(const char *errinfo,const void *private_info, size_t cb,void *user_data),
void *user_data,cl_int *errcode_ret)
Context(上下文):OpenCL的Platform上共享和使用资源的环境,包括kernel、device、memory objects、command queue等。使用中一般一个Platform对应一个Context。
4、cl_command_queue clCreateCommandQueue (cl_context context,cl_device_id device,
cl_command_queue_properties properties,cl_int *errcode_ret)
当设备执行任务时,由主机来提交命令,将命令发送到队列中。命令队列和设备对应,一个命令队列只能关联到一个设备,但是单个设备可以有多个命令队列,这就可以将不同的命令提交到不同队列。
Command Queue(指令队列):在指定设备上管理多个指令(Command)。队列里指令执行可以顺序也可以乱序。一个设备可以对应多个指令队列。
5、cl_program clCreateProgramWithSource (cl_context context,cl_uint count,const char **strings,
const size_t *lengths,cl_int *errcode_ret)
cl_int clBuildProgram (cl_program program,cl_uint num_devices,const cl_device_id *device_list,
const char *options,
void ( CL_CALLBACK *pfn_notify)(cl_program program,void *user_data),
void *user_data)
Program:OpenCL程序,由kernel函数、其他函数和声明等组成。
6、cl_mem clCreateBuffer (cl_context context,cl_mem_flags flags,size_t size,void *host_ptr,
cl_int *errcode_ret)
Memory Object(内存对象):在主机和设备之间传递数据的对象,一般映射到OpenCL程序中的global memory。有两种具体的类型:Buffer Object(缓存对象)和Image Object(图像对象)。
cl_int clEnqueueReadBuffer (cl_command_queue command_queue,cl_mem buffer,cl_bool blocking_read,
size_t offset,size_t size,void *ptr,cl_uint num_events_in_wait_list,const cl_event *event_wait_list,
cl_event *event)
7、cl_kernel clCreateKernel (cl_program program, const char *kernel_name, cl_int *errcode_ret)
Kernel(核函数):可以从主机端调用,运行在设备端的函数。
cl_int clSetKernelArg (cl_kernel kernel,cl_uint arg_index,size_t arg_size,const void *arg_value)
8、cl_int clEnqueueNDRangeKernel (cl_command_queue command_queue,cl_kernel kernel,
cl_uint work_dim,const size_t *global_work_offset,const size_t *global_work_size,
const size_t *local_work_size,cl_uint num_events_in_wait_list,const cl_event *event_wait_list,
cl_event *event)
NDRange:主机端运行设备端kernel函数的主要接口。实际上还有其他的,NDRange是非常常见的,用于分组运算,以后具体用到的时候就知道区别了。
9. 设置Group Size
一个OpenCL运行任务中并行计算的单位是work-item。而work-item的组织形式就由维数(dim),各维度尺寸( global_work_size)和分组方式( local_work_size)等参数决定。
注意几点:一是维数,一般的OpenCL设备最大支持维数为3,可以查询CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS来获取;二是local_work_size,合适的size与具体OpenCL设备的最大并发资源有关,可以不设置。
/** step 9: set work group size */
cl_uint work_dim = 3;
// in most opencl device, max dimition is 3
size_t global_work_size[] = { ARRAY_SIZE, 1, 1 };
size_t *local_work_size = NULL; // let opencl device determine how to break work items into work groups
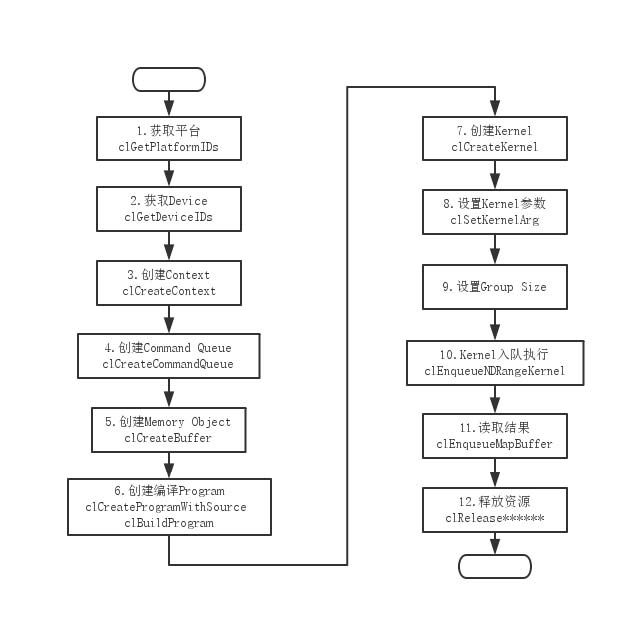
Host端来看,OpenCL的组要执行流程是这样的:
List basic kernel source:
char *kernelSource =
"__kernel void test(__global int *pInOut)\n"
"{\n"
" int index = get_global_id(0);\n"
" pInOut[index] += pInOut[index];\n"
"}\n";
与这个例子运算结果等价的程序为
for (int i = 0; i < ARRAY_SIZE; i++)
{
a[i] += a[i];
}