Android中,绘图的API很多,比如2D的绘图skia;3D的绘图OpenGLES,Vulkan等。Android 开始,的View系统中,多数都是采用2D的模式的View Widget,比如绘制一张Bitmap图片,显示一个按钮等。随着Android系统的更新,和用户对视觉效果的追求,以前的这套2D View系统,不仅不能满足要求,而且渲染非常的慢。所以Android一方面完善对3D的API的支持,另一方面修改原来View Widget的渲染机制。
渲染机制的更新,Android提出了硬件加速的机制,其作用就是将2D的绘图操纵,转换为对应的3D的绘图操纵,这个转换的过程,我们把它叫做录制。需要显示的时候,再用OpenGLES通过GPU去渲染。界面创建时,第一次全部录制,后续的过程中,界面如果只有部分区域的widget更新,只需要重新录制更新的widget。录制好的绘图操纵,保存在一个显示列表DisplayList中,需要真正显示到界面的时候,直接显示DisplayList中的绘图 操纵。这样,一方面利用GPU去渲染,比Skia要快;另一方面,采用DisplayList,值重新录制,有更新区域,最大程度利用上一帧的数据,效率自然就快很多。这就是硬件加速的来源。
roundRectClipState
语言苍白,实践为先,我们结合测试示例,来看看硬件加速是怎么回事~
应用使用硬件(GPU)绘制实例
这个是Android原生的测试硬件绘制的应用:
* frameworks/base/tests/HwAccelerationTest/src/com/android/test/hwui/HardwareCanvasSurfaceViewActivity.java
private static class RenderingThread extends Thread {
private final SurfaceHolder mSurface;
private volatile boolean mRunning = true;
private int mWidth, mHeight;
public RenderingThread(SurfaceHolder surface) {
mSurface = surface;
}
void setSize(int width, int height) {
mWidth = width;
mHeight = height;
}
@Override
public void run() {
float x = 0.0f;
float y = 0.0f;
float speedX = 5.0f;
float speedY = 3.0f;
Paint paint = new Paint();
paint.setColor(0xff00ff00);
while (mRunning && !Thread.interrupted()) {
final Canvas canvas = mSurface.lockHardwareCanvas();
try {
canvas.drawColor(0x00000000, PorterDuff.Mode.CLEAR);
canvas.drawRect(x, y, x + 20.0f, y + 20.0f, paint);
} finally {
mSurface.unlockCanvasAndPost(canvas);
}
... ...
try {
Thread.sleep(15);
} catch (InterruptedException e) {
// Interrupted
}
}
}
void stopRendering() {
interrupt();
mRunning = false;
}
}
应用这里拿到一个Surface,然后lock一个HardwareCanvas,用lock的HardwareCanvas进行绘制,我们绘制的就可以使用硬件GPU进行绘制。这里每隔15秒循环一次,绘制一个小方块,在屏幕上不停的运动。而背景,被绘制成0x00000000,黑色。
硬件绘制Java层相关流程
通过前面的代码,关键的是在lockHardwareCanvas。
lockHardwareCanvas的代码如下:
* frameworks/base/core/java/android/view/SurfaceView.java
@Override
public Canvas lockHardwareCanvas() {
return internalLockCanvas(null, true);
}
private Canvas internalLockCanvas(Rect dirty, boolean hardware) {
mSurfaceLock.lock();
if (DEBUG) Log.i(TAG, System.identityHashCode(this) + " " + "Locking canvas... stopped="
+ mDrawingStopped + ", surfaceControl=" + mSurfaceControl);
Canvas c = null;
if (!mDrawingStopped && mSurfaceControl != null) {
try {
if (hardware) {
c = mSurface.lockHardwareCanvas();
} else {
c = mSurface.lockCanvas(dirty);
}
} catch (Exception e) {
Log.e(LOG_TAG, "Exception locking surface", e);
}
}
if (DEBUG) Log.i(TAG, System.identityHashCode(this) + " " + "Returned canvas: " + c);
if (c != null) {
mLastLockTime = SystemClock.uptimeMillis();
return c;
}
... ...
return null;
}
这里Canvas是通过mSurface来申请的。
* frameworks/base/core/java/android/view/Surface.java
public Canvas lockHardwareCanvas() {
synchronized (mLock) {
checkNotReleasedLocked();
if (mHwuiContext == null) {
mHwuiContext = new HwuiContext();
}
return mHwuiContext.lockCanvas(
nativeGetWidth(mNativeObject),
nativeGetHeight(mNativeObject));
}
}
Surface中封装了一个 HwuiContext ,其构造函数如下:
HwuiContext() {
mRenderNode = RenderNode.create("HwuiCanvas", null);
mRenderNode.setClipToBounds(false);
mHwuiRenderer = nHwuiCreate(mRenderNode.mNativeRenderNode, mNativeObject);
}
在HwuiContext的构造函数中,创建了一个RenderNode,创建了一个HwuiRenderer。nHwuiCreate创建一个native的HwuiRender。
这里的HwuiContext,就是和HWUI打交道了。
HwuiContext的lockCanvas实现如下:
Canvas lockCanvas(int width, int height) {
if (mCanvas != null) {
throw new IllegalStateException("Surface was already locked!");
}
mCanvas = mRenderNode.start(width, height);
return mCanvas;
}
RenderNode的start函数:
public DisplayListCanvas start(int width, int height) {
return DisplayListCanvas.obtain(this, width, height);
}
static DisplayListCanvas obtain(@NonNull RenderNode node, int width, int height) {
if (node == null) throw new IllegalArgumentException("node cannot be null");
DisplayListCanvas canvas = sPool.acquire();
if (canvas == null) {
canvas = new DisplayListCanvas(node, width, height);
} else {
nResetDisplayListCanvas(canvas.mNativeCanvasWrapper, node.mNativeRenderNode,
width, height);
}
canvas.mNode = node;
canvas.mWidth = width;
canvas.mHeight = height;
return canvas;
}
RenderNode,start时,将创建一个DisplayListCanvas。DisplayListCanvas是显示列表的Canvas。DisplayListCanvas 构建时,将通过nCreateDisplayListCanvas创建一个native的DisplayListCanvas。
private DisplayListCanvas(@NonNull RenderNode node, int width, int height) {
super(nCreateDisplayListCanvas(node.mNativeRenderNode, width, height));
mDensity = 0; // disable bitmap density scaling
}
DisplayListCanvas和RecordingCanvas的构造函数都比较简单,但是留意一下Canvas的构造函数:
public Canvas(long nativeCanvas) {
if (nativeCanvas == 0) {
throw new IllegalStateException();
}
mNativeCanvasWrapper = nativeCanvas;
mFinalizer = NoImagePreloadHolder.sRegistry.registerNativeAllocation(
this, mNativeCanvasWrapper);
mDensity = Bitmap.getDefaultDensity();
}
这里的mNativeCanvasWrapper,就是nCreateDisplayListCanvas时,创建的native对应的Canvas。后续,JNI中都是通过mNativeCanvasWrapper去找到对应的nativ的Canvas的。
我们先来看这些相关的类之间的关系~

其中,RenderNode,DisplayListCanvas,HwuiRenderer构成了硬件绘制的重要元素。
再回到我们的测试代码,我们这里有两个绘制操纵:
- drawColor
- drawRect
drawColor是在DisplayListCanvas的父类RecordingCanvas中实现的:
public final void drawColor(@ColorInt int color, @NonNull PorterDuff.Mode mode) {
nDrawColor(mNativeCanvasWrapper, color, mode.nativeInt);
}
这里调用native的nDrawColor方法。
drawRect也是在DisplayListCanvas的父类RecordingCanvas中实现的:
@Override
public final void drawRect(float left, float top, float right, float bottom,
@NonNull Paint paint) {
nDrawRect(mNativeCanvasWrapper, left, top, right, bottom, paint.getNativeInstance());
}
调用native的nDrawRect方法。
native处理流程
native的Canvas创建
DisplayListCanvas的JNI实现如下:
* frameworks/base/core/jni/android_view_DisplayListCanvas.cpp
const char* const kClassPathName = "android/view/DisplayListCanvas";
static JNINativeMethod gMethods[] = {
// ------------ @FastNative ------------------
{ "nCallDrawGLFunction", "(JJLjava/lang/Runnable;)V",
(void*) android_view_DisplayListCanvas_callDrawGLFunction },
// ------------ @CriticalNative --------------
{ "nCreateDisplayListCanvas", "(JII)J", (void*) android_view_DisplayListCanvas_createDisplayListCanvas },
{ "nResetDisplayListCanvas", "(JJII)V", (void*) android_view_DisplayListCanvas_resetDisplayListCanvas },
{ "nGetMaximumTextureWidth", "()I", (void*) android_view_DisplayListCanvas_getMaxTextureWidth },
{ "nGetMaximumTextureHeight", "()I", (void*) android_view_DisplayListCanvas_getMaxTextureHeight },
{ "nInsertReorderBarrier", "(JZ)V", (void*) android_view_DisplayListCanvas_insertReorderBarrier },
{ "nFinishRecording", "(J)J", (void*) android_view_DisplayListCanvas_finishRecording },
{ "nDrawRenderNode", "(JJ)V", (void*) android_view_DisplayListCanvas_drawRenderNode },
{ "nDrawLayer", "(JJ)V", (void*) android_view_DisplayListCanvas_drawLayer },
{ "nDrawCircle", "(JJJJJ)V", (void*) android_view_DisplayListCanvas_drawCircleProps },
{ "nDrawRoundRect", "(JJJJJJJJ)V",(void*) android_view_DisplayListCanvas_drawRoundRectProps },
};
nCreateDisplayListCanvas对应的实现为android_view_DisplayListCanvas_createDisplayListCanvas。
static jlong android_view_DisplayListCanvas_createDisplayListCanvas(jlong renderNodePtr,
jint width, jint height) {
RenderNode* renderNode = reinterpret_cast(renderNodePtr);
return reinterpret_cast(Canvas::create_recording_canvas(width, height, renderNode));
}
注意我们这里的renderNodePtr。这个是RenderNode在native层的对象(地址)。
Canvas的create_recording_canvas函数如下:
Canvas* Canvas::create_recording_canvas(int width, int height, uirenderer::RenderNode* renderNode) {
if (uirenderer::Properties::isSkiaEnabled()) {
return new uirenderer::skiapipeline::SkiaRecordingCanvas(renderNode, width, height);
}
return new uirenderer::RecordingCanvas(width, height);
}
isSkiaEnabled没有被enable的,所以创建的是native的RecordingCanvas。Android 8.0开始,对HWUI进行了重构,增加了RenderPipeline的概念。目前有三种类型的pipeline,分别对应不同的渲染。
enum class RenderPipelineType {
OpenGL = 0,
SkiaGL,
SkiaVulkan,
NotInitialized = 128
};
默认还是OpenGL类型。
native的RecordingCanvas如下:
* frameworks/base/libs/hwui/RecordingCanvas.cpp
RecordingCanvas::RecordingCanvas(size_t width, size_t height)
: mState(*this), mResourceCache(ResourceCache::getInstance()) {
resetRecording(width, height);
}
RecordingCanvas创建时,创建了对应的CanvasState,和ResourceCache。CanvasState是Canvas的状态,管理Snapshot的栈,实现matrix,save/restore,clipping等Renderer的接口。ResourceCache主要是做资源cache,cache为点九类型。
在resetRecording函数中,又做了很多初始化。
void RecordingCanvas::resetRecording(int width, int height, RenderNode* node) {
LOG_ALWAYS_FATAL_IF(mDisplayList, "prepareDirty called a second time during a recording!");
mDisplayList = new DisplayList();
mState.initializeRecordingSaveStack(width, height);
mDeferredBarrierType = DeferredBarrierType::InOrder;
}
- 创建了显示列表mDisplayList,这个很重要,稍后我们再介绍。它主要用来保存显示列表的绘制命令。
- 初始化CanvasState
到此,native的Canvas创建完成。
Draw操纵的录制
测试代码中,一共两个绘制操纵,我们以这两个绘制操纵为例,来说明绘制的操纵的录制。
nDrawColor nDrawRect
* frameworks/base/core/jni/android_graphics_Canvas.cpp
static const JNINativeMethod gDrawMethods[] = {
{"nDrawColor","(JII)V", (void*) CanvasJNI::drawColor},
{"nDrawPaint","(JJ)V", (void*) CanvasJNI::drawPaint},
{"nDrawPoint", "(JFFJ)V", (void*) CanvasJNI::drawPoint},
{"nDrawPoints", "(J[FIIJ)V", (void*) CanvasJNI::drawPoints},
{"nDrawLine", "(JFFFFJ)V", (void*) CanvasJNI::drawLine},
{"nDrawLines", "(J[FIIJ)V", (void*) CanvasJNI::drawLines},
{"nDrawRect","(JFFFFJ)V", (void*) CanvasJNI::drawRect},
drawColor函数
static void drawColor(JNIEnv* env, jobject, jlong canvasHandle, jint color, jint modeHandle) {
SkBlendMode mode = static_cast(modeHandle);
get_canvas(canvasHandle)->drawColor(color, mode);
}
canvasHandle为native RecordingCanvas的handle,所以get_canvas获取到的是RecordingCanvas。
RecordingCanvas的drawColor函数如下:
* frameworks/base/libs/hwui/RecordingCanvas.cpp
void RecordingCanvas::drawColor(int color, SkBlendMode mode) {
addOp(alloc().create_trivial(getRecordedClip(), color, mode));
}
- alloc()获取到的是DisplayList的allocator
- create_trivial是一个模板函数
template
T* create_trivial(Params&&... params) {
static_assert(std::is_trivially_destructible::value,
"Error, called create_trivial on a non-trivial type");
return new (allocImpl(sizeof(T))) T(std::forward(params)...);
}
类型 T为ColorOp,参数params为(getRecordedClip(), color, mode),其作用就是构造已给ColorOp。
- allocImpl,分配内存空间
ColorOp的定义在头文件中:
frameworks/base/libs/hwui/RecordedOp.h
struct ColorOp : RecordedOp {
// Note: unbounded op that will fillclip, so no bounds/matrix needed
ColorOp(const ClipBase* localClip, int color, SkBlendMode mode)
: RecordedOp(RecordedOpId::ColorOp, Rect(), Matrix4::identity(), localClip, nullptr)
, color(color)
, mode(mode) {}
const int color;
const SkBlendMode mode;
};
RecordedOp.h中定义了所以的绘图操纵。
如nDrawRect对应的操纵为RectOp:
void RecordingCanvas::drawRect(float left, float top, float right, float bottom,
const SkPaint& paint) {
if (CC_UNLIKELY(paint.nothingToDraw())) return;
addOp(alloc().create_trivial(Rect(left, top, right, bottom),
*(mState.currentSnapshot()->transform), getRecordedClip(),
refPaint(&paint)));
}
struct RectOp : RecordedOp {
RectOp(BASE_PARAMS) : SUPER(RectOp) {}
};
所有的绘图操作都继承RecordedOp。
RecordedOp定义如下:
struct RecordedOp {
/* ID from RecordedOpId - generally used for jumping into function tables */
const int opId;
/* bounds in *local* space, without accounting for DisplayList transformation, or stroke */
const Rect unmappedBounds;
/* transform in recording space (vs DisplayList origin) */
const Matrix4 localMatrix;
/* clip in recording space - nullptr if not clipped */
const ClipBase* localClip;
/* optional paint, stored in base object to simplify merging logic */
const SkPaint* paint;
protected:
RecordedOp(unsigned int opId, BASE_PARAMS)
: opId(opId)
, unmappedBounds(unmappedBounds)
, localMatrix(localMatrix)
, localClip(localClip)
, paint(paint) {}
};
- opId,RecordedOpId中的ID,用以调转到对应的函数
- unmappedBounds,绘制区域的大小
- localMatrix,transform
- ClipBase,截取
- paint,画笔
绘图操纵创建后,通过addOp方法,添加到DisplayList中:
int RecordingCanvas::addOp(RecordedOp* op) {
// skip op with empty clip
if (op->localClip && op->localClip->rect.isEmpty()) {
// NOTE: this rejection happens after op construction/content ref-ing, so content ref'd
// and held by renderthread isn't affected by clip rejection.
// Could rewind alloc here if desired, but callers would have to not touch op afterwards.
return -1;
}
int insertIndex = mDisplayList->ops.size();
mDisplayList->ops.push_back(op);
if (mDeferredBarrierType != DeferredBarrierType::None) {
// op is first in new chunk
mDisplayList->chunks.emplace_back();
DisplayList::Chunk& newChunk = mDisplayList->chunks.back();
newChunk.beginOpIndex = insertIndex;
newChunk.endOpIndex = insertIndex + 1;
newChunk.reorderChildren = (mDeferredBarrierType == DeferredBarrierType::OutOfOrder);
newChunk.reorderClip = mDeferredBarrierClip;
int nextChildIndex = mDisplayList->children.size();
newChunk.beginChildIndex = newChunk.endChildIndex = nextChildIndex;
mDeferredBarrierType = DeferredBarrierType::None;
} else {
// standard case - append to existing chunk
mDisplayList->chunks.back().endOpIndex = insertIndex + 1;
}
return insertIndex;
}
不得不说,这里有点复杂,但是很巧妙。
- 所有的绘图操纵,我们把它叫做Ops,都保存在ops中。ops就好比一个公司,而Ops就是一个员工。而每个Ops都有一个序号insertIndex,按照加入的先后顺序,相当与工号。
- chunk中还没有元素时,mDeferredBarrierType为DeferredBarrierType::InOrder,这个时候就会增加一个Chunk。除非重新插入Barrier,即insertReorderBarrier,要不然,后续添加的Ops都是在同一个Chunk中的。Chunk就好比公司里面的部门,部门说,工号从多少号到多少号的归属于这个部门。beginOpIndex是开始的序号,endOpIndex是结束的序号,这之间的,都是属于同一个Chunk,每加入一个Ops,endOpIndex就会加1。
- 怎么来理解children呢?按照前面的类比,可以理解为一个部门里面的小组。beginChildIndex和endChildIndex之间的Ops都属于同一个Children。
其实,这的Ops,chunk,children就是对Android View系统的抽象化。Chunk对应RootView,而children对应ViewGroup,Ops再对应,绘制Color,Rect等操纵。就是这么神奇~
我们来看一下DisplayList和Ops之间的关系

绘制操纵完成后,所有绘制操纵极其参数都保存在DisplayList中了。那么这些绘制操纵什么时候显示出来呢?我们继续看。
创建RenderNode
RenderNode用以录制绘图操纵的批处理,当绘制的时候,可以store和apply。
java层的代码如下:其实RenderNode就对应前面我们所说的ViewGroup,有一个RootView,同样也有一个RootNode。
我们先来看RenderNode是怎么创建的
public static RenderNode create(String name, @Nullable View owningView) {
return new RenderNode(name, owningView);
}
private RenderNode(String name, View owningView) {
mNativeRenderNode = nCreate(name);
NoImagePreloadHolder.sRegistry.registerNativeAllocation(this, mNativeRenderNode);
mOwningView = owningView;
}
nCreate是JNI方法。
RenderNode的JNI实现如下:
const char* const kClassPathName = "android/view/RenderNode";
static const JNINativeMethod gMethods[] = {
// ----------------------------------------------------------------------------
// Regular JNI
// ----------------------------------------------------------------------------
{ "nCreate", "(Ljava/lang/String;)J", (void*) android_view_RenderNode_create },
{ "nGetNativeFinalizer", "()J", (void*) android_view_RenderNode_getNativeFinalizer },
{ "nOutput", "(J)V", (void*) android_view_RenderNode_output },
{ "nGetDebugSize", "(J)I", (void*) android_view_RenderNode_getDebugSize },
{ "nAddAnimator", "(JJ)V", (void*) android_view_RenderNode_addAnimator },
{ "nEndAllAnimators", "(J)V", (void*) android_view_RenderNode_endAllAnimators },
{ "nRequestPositionUpdates", "(JLandroid/view/SurfaceView;)V", (void*) android_view_RenderNode_requestPositionUpdates },
{ "nSetDisplayList", "(JJ)V", (void*) android_view_RenderNode_setDisplayList },
nCreate函数实现为android_view_RenderNode_create
static jlong android_view_RenderNode_create(JNIEnv* env, jobject, jstring name) {
RenderNode* renderNode = new RenderNode();
renderNode->incStrong(0);
if (name != NULL) {
const char* textArray = env->GetStringUTFChars(name, NULL);
renderNode->setName(textArray);
env->ReleaseStringUTFChars(name, textArray);
}
return reinterpret_cast(renderNode);
}
在JNI中就创建了一个native的RenderNode
* frameworks/base/libs/hwui/RenderNode.cpp
RenderNode::RenderNode()
: mDirtyPropertyFields(0)
, mNeedsDisplayListSync(false)
, mDisplayList(nullptr)
, mStagingDisplayList(nullptr)
, mAnimatorManager(*this)
, mParentCount(0) {}
创建完成的RenderNode,是给到DisplayListCanvas的。
HwuiContext和HwuiRenderer
nHwuiCreate创建HwuiRenderer
* frameworks/base/core/jni/android_view_Surface.cpp
static const JNINativeMethod gSurfaceMethods[] = {
... ...
// HWUI context
{"nHwuiCreate", "(JJ)J", (void*) hwui::create },
{"nHwuiSetSurface", "(JJ)V", (void*) hwui::setSurface },
{"nHwuiDraw", "(J)V", (void*) hwui::draw },
{"nHwuiDestroy", "(J)V", (void*) hwui::destroy },
};
nHwuiCreate函数实现如下:
static jlong create(JNIEnv* env, jclass clazz, jlong rootNodePtr, jlong surfacePtr) {
RenderNode* rootNode = reinterpret_cast(rootNodePtr);
sp surface(reinterpret_cast(surfacePtr));
ContextFactory factory;
RenderProxy* proxy = new RenderProxy(false, rootNode, &factory);
proxy->loadSystemProperties();
proxy->setSwapBehavior(SwapBehavior::kSwap_discardBuffer);
proxy->initialize(surface);
// Shadows can't be used via this interface, so just set the light source
// to all 0s.
proxy->setup(0, 0, 0);
proxy->setLightCenter((Vector3){0, 0, 0});
return (jlong) proxy;
}
创建了一个RenderProxy,nHwuiCreate返回的是一个RenderProxy实例。
RenderProxy的构造函数如下:
* frameworks/base/libs/hwui/renderthread/RenderProxy.cpp
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode,
IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance()), mContext(nullptr) {
mContext = mRenderThread.queue().runSync([&]() -> CanvasContext* {
return CanvasContext::create(mRenderThread, translucent, rootRenderNode, contextFactory);
});
mDrawFrameTask.setContext(&mRenderThread, mContext, rootRenderNode);
}
这里诞生了很多东西:
- RenderProxy是一个代理者,严格的单线程。所有的方法都必须在自己的线程中调用。
- RenderThread,渲染线程,是一个单例,也就是说,一个进程中只有一个,所有的绘制操纵都必须在这个线程中完成。应用端很多操纵,都以RenderTask的形式post到RenderThread线程中完成。
- CanvasContext,上下文,由于OpenGL是单线程的,所以,我们给到GPU的绘图命令都封装在各自的上下文中。这个和上层的HwuiRenderer是对应的。
- DrawFrameTask,比较特殊的一个RenderTask。可重复使用的绘制Task。
我们先来理解这个HWUI的Thread。
RenderThread
hwui中很多C++的新特性,代码比较难理解。
* frameworks/base/libs/hwui/renderthread/RenderThread.h
class RenderThread : private ThreadBase {
PREVENT_COPY_AND_ASSIGN(RenderThread);
- PREVENT_COPY_AND_ASSIG阻止拷贝构造函数和=重载
- 继承ThreadBase,ThreadBase继承Android的基本类Thread
在构造RenderThread时,就启动了RenderThread线程。
RenderThread::RenderThread()
: ThreadBase()
, mDisplayEventReceiver(nullptr)
, mVsyncRequested(false)
, mFrameCallbackTaskPending(false)
, mRenderState(nullptr)
, mEglManager(nullptr)
, mVkManager(nullptr) {
Properties::load();
start("RenderThread");
}
ThreadBase的构造函数值得一看:
ThreadBase()
: Thread(false)
, mLooper(new Looper(false))
, mQueue([this]() { mLooper->wake(); }, mLock) {}
mQueue的实例化,C++的新特性。其实就是构造一个Queue,第一个参数是一个函数。函数体为:
{ mLooper->wake(); }
这个函数执行的时候,就唤醒mLooper,线程开始工作。
WorkQueue的构造函数如下:
WorkQueue(std::function&& wakeFunc, std::mutex& lock)
: mWakeFunc(move(wakeFunc)), mLock(lock) {}
我们再来看RenderThread是怎么工作的。RenderThread起来后,就会执行RenderThread的threadLoop。
threadLoop如下:
bool RenderThread::threadLoop() {
setpriority(PRIO_PROCESS, 0, PRIORITY_DISPLAY);
if (gOnStartHook) {
gOnStartHook();
}
initThreadLocals();
while (true) {
waitForWork();
processQueue();
if (mPendingRegistrationFrameCallbacks.size() && !mFrameCallbackTaskPending) {
drainDisplayEventQueue();
mFrameCallbacks.insert(mPendingRegistrationFrameCallbacks.begin(),
mPendingRegistrationFrameCallbacks.end());
mPendingRegistrationFrameCallbacks.clear();
requestVsync();
}
if (!mFrameCallbackTaskPending && !mVsyncRequested && mFrameCallbacks.size()) {
// TODO: Clean this up. This is working around an issue where a combination
// of bad timing and slow drawing can result in dropping a stale vsync
// on the floor (correct!) but fails to schedule to listen for the
// next vsync (oops), so none of the callbacks are run.
requestVsync();
}
}
return false;
}
- initThreadLocals初始化Thread的本地变量
- threadLoop中while循环,不停处理请求。如果没有任务时,等在waitForWork
前面是创建完RenderProxy后,还会设置一些参数
RenderProxy* proxy = new RenderProxy(false, rootNode, &factory);
proxy->loadSystemProperties();
proxy->setSwapBehavior(SwapBehavior::kSwap_discardBuffer);
proxy->initialize(surface);
// Shadows can't be used via this interface, so just set the light source
// to all 0s.
proxy->setup(0, 0, 0);
proxy->setLightCenter((Vector3){0, 0, 0});
我们以initialize为例。
void RenderProxy::initialize(const sp& surface) {
mRenderThread.queue().post(
[ this, surf = surface ]() mutable { mContext->setSurface(std::move(surf)); });
}
initialize时,将给mRenderThread的队列中post一个东西,Oops...现在还不知道它是什么。下面我们将来看它是什么。
post是一个模板函数:
* frameworks/base/libs/hwui/thread/WorkQueue.h
template
void post(F&& func) {
postAt(0, std::forward(func));
}
template
void postAt(nsecs_t time, F&& func) {
enqueue(WorkItem{time, std::function(std::forward(func))});
}
post的时候,将根据传进来的参数,创建一个WorkItem,enqueue到消息队列mWorkQueue中。
void enqueue(WorkItem&& item) {
bool needsWakeup;
{
std::unique_lock _lock{mLock};
auto insertAt = std::find_if(
std::begin(mWorkQueue), std::end(mWorkQueue),
[time = item.runAt](WorkItem & item) { return item.runAt > time; });
needsWakeup = std::begin(mWorkQueue) == insertAt;
mWorkQueue.emplace(insertAt, std::move(item));
}
if (needsWakeup) {
mWakeFunc();
}
}
mWakeFunc如果需要唤醒,就通过mWakeFunc函数,唤醒mLooper。还记得吗?mWakeFunc是ThreadBase中构建WorkQueue时,传下来的无名函数。
WorkItem定义如下。
struct WorkItem {
WorkItem() = delete;
WorkItem(const WorkItem& other) = delete;
WorkItem& operator=(const WorkItem& other) = delete;
WorkItem(WorkItem&& other) = default;
WorkItem& operator=(WorkItem&& other) = default;
WorkItem(nsecs_t runAt, std::function&& work)
: runAt(runAt), work(std::move(work)) {}
nsecs_t runAt;
std::function work;
};
对于我们的initialize函数而言,这里的WorkItem中的work是不是mContext->setSurface?答案是肯定的。
再来看RenderThread,收到新消息后怎么处理。
首先用processQueue处理Queue。
void processQueue() { mQueue.process(); }
最终还是 回到WorkQueue 中。
void process() {
auto now = clock::now();
std::vector toProcess;
{
std::unique_lock _lock{mLock};
if (mWorkQueue.empty()) return;
toProcess = std::move(mWorkQueue);
auto moveBack = find_if(std::begin(toProcess), std::end(toProcess),
[&now](WorkItem& item) { return item.runAt > now; });
if (moveBack != std::end(toProcess)) {
mWorkQueue.reserve(std::distance(moveBack, std::end(toProcess)) + 5);
std::move(moveBack, std::end(toProcess), std::back_inserter(mWorkQueue));
toProcess.erase(moveBack, std::end(toProcess));
}
}
for (auto& item : toProcess) {
item.work();
}
}
这里将mWorkQueue中未处理的WorkItem找处理,放到toProcess中。再调用每个Item的work方法。
对于我们的initialize函数而言,这里是不是就是mContext->setSurface?也就是CanvasContext的setSurface方法:
void CanvasContext::setSurface(sp&& surface) {
ATRACE_CALL();
mNativeSurface = std::move(surface);
ColorMode colorMode = mWideColorGamut ? ColorMode::WideColorGamut : ColorMode::Srgb;
bool hasSurface = mRenderPipeline->setSurface(mNativeSurface.get(), mSwapBehavior, colorMode);
mFrameNumber = -1;
if (hasSurface) {
mHaveNewSurface = true;
mSwapHistory.clear();
} else {
mRenderThread.removeFrameCallback(this);
}
}
神奇吧~
很多RenderProxy中的操作,都是通过这种方式post到CanvasContext中,且运行在RenderThread线程中。
我们再来看一个特殊的Task DrawFrameTask。
RenderProxy创建时,创建的DrawFrameTask
* frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp
DrawFrameTask::DrawFrameTask()
: mRenderThread(nullptr)
, mContext(nullptr)
, mContentDrawBounds(0, 0, 0, 0)
, mSyncResult(SyncResult::OK) {}
DrawFrameTask::~DrawFrameTask() {}
void DrawFrameTask::setContext(RenderThread* thread, CanvasContext* context,
RenderNode* targetNode) {
mRenderThread = thread;
mContext = context;
mTargetNode = targetNode;
}
到目前位置,DisplayList有了,RenderThread有了,但是绘制在哪儿呢?我们这里直接解密吧,具体的流程就不介绍了,我们单看hwui这部分的逻辑。
显示时,上层会调syncAndDrawFrame
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}
int DrawFrameTask::drawFrame() {
LOG_ALWAYS_FATAL_IF(!mContext, "Cannot drawFrame with no CanvasContext!");
mSyncResult = SyncResult::OK;
mSyncQueued = systemTime(CLOCK_MONOTONIC);
postAndWait();
return mSyncResult;
}
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue().post([this]() { run(); });
mSignal.wait(mLock);
}
这类,drawFrame,也就通过RenderThread,post一个WorkItem到RenderThread的队列里面,在RenderThread线程中执行的。
RenderThread处理Queue时,执行的确是这里的run函数。
void DrawFrameTask::run() {
ATRACE_NAME("DrawFrame");
bool canUnblockUiThread;
bool canDrawThisFrame;
{
TreeInfo info(TreeInfo::MODE_FULL, *mContext);
canUnblockUiThread = syncFrameState(info);
canDrawThisFrame = info.out.canDrawThisFrame;
}
// Grab a copy of everything we need
CanvasContext* context = mContext;
// From this point on anything in "this" is *UNSAFE TO ACCESS*
if (canUnblockUiThread) {
unblockUiThread();
}
if (CC_LIKELY(canDrawThisFrame)) {
context->draw();
} else {
// wait on fences so tasks don't overlap next frame
context->waitOnFences();
}
if (!canUnblockUiThread) {
unblockUiThread();
}
}
- 先调用syncFrameState,同步一下Frame的状态
- 再通过CanvasContext的draw方法去绘制
OK,现在,主要的流程就到CanvasContext,我们看看CanvasContext
CanvasContext
渲染的上下文。
* frameworks/base/libs/hwui/renderthread/CanvasContext.cpp
CanvasContext* CanvasContext::create(RenderThread& thread, bool translucent,
RenderNode* rootRenderNode, IContextFactory* contextFactory) {
auto renderType = Properties::getRenderPipelineType();
switch (renderType) {
case RenderPipelineType::OpenGL:
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique(thread));
case RenderPipelineType::SkiaGL:
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique(thread));
case RenderPipelineType::SkiaVulkan:
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique(thread));
default:
LOG_ALWAYS_FATAL("canvas context type %d not supported", (int32_t)renderType);
break;
}
return nullptr;
}
前面我们已经说过,渲染Pipeline有几种类型,Pipeline由IRenderPipeline描述。创建CanvasContext时,会根据pipeline的类型,创建对应的Pipeline,他们的关系如下:

IRenderPipeline是统一的接口。默认的类型是OpenGLPipeline,用的是OpenGL实现。这可以可通过属性debug.hwui.renderer来设置。对应地逻辑如下:
* frameworks/base/libs/hwui/Properties.cpp
#define PROPERTY_RENDERER "debug.hwui.renderer"
RenderPipelineType Properties::getRenderPipelineType() {
if (sRenderPipelineType != RenderPipelineType::NotInitialized) {
return sRenderPipelineType;
}
char prop[PROPERTY_VALUE_MAX];
property_get(PROPERTY_RENDERER, prop, "skiagl");
if (!strcmp(prop, "skiagl")) {
ALOGD("Skia GL Pipeline");
sRenderPipelineType = RenderPipelineType::SkiaGL;
} else if (!strcmp(prop, "skiavk")) {
ALOGD("Skia Vulkan Pipeline");
sRenderPipelineType = RenderPipelineType::SkiaVulkan;
} else { //"opengl"
ALOGD("HWUI GL Pipeline");
sRenderPipelineType = RenderPipelineType::OpenGL;
}
return sRenderPipelineType;
}
SkiaOpenGLPipeline和SkiaVulkanPipeline,两者都用到skia进行Ops的渲染,也就是说,Ops的录制是用skia来完成的。后面的显示才用到OpenGL或Vulkan。
我们再来看一下CanvasContext的构造函数:
CanvasContext::CanvasContext(RenderThread& thread, bool translucent, RenderNode* rootRenderNode,
IContextFactory* contextFactory,
std::unique_ptr renderPipeline)
: mRenderThread(thread)
, mOpaque(!translucent)
, mAnimationContext(contextFactory->createAnimationContext(mRenderThread.timeLord()))
, mJankTracker(&thread.globalProfileData(), thread.mainDisplayInfo())
, mProfiler(mJankTracker.frames())
, mContentDrawBounds(0, 0, 0, 0)
, mRenderPipeline(std::move(renderPipeline)) {
rootRenderNode->makeRoot();
mRenderNodes.emplace_back(rootRenderNode);
mRenderThread.renderState().registerCanvasContext(this);
mProfiler.setDensity(mRenderThread.mainDisplayInfo().density);
}
- contextFactory
contextFactory是在Surface的JNI中创建RenderProxy时,传入的。主要是用来创建AnimationContext,AnimationContext主要用来处理动画Animation。
* frameworks/base/core/jni/android_view_Surface.cpp
class ContextFactory : public IContextFactory {
public:
virtual AnimationContext* createAnimationContext(renderthread::TimeLord& clock) {
return new AnimationContext(clock);
}
};
rootRenderNod,rootRenderNode前面在做Ops录制时的RenderNode。这里通过makeRoot,将其设置为Root的RenderNode。它是mRenderNodes中的第一个RenderNode。
CanvasContext实现了IFrameCallback接口,所以,CanvasContext能接收编舞者Choreographer的callback,处理实时动画。
我们再回过头看DrawFrameTask的run。首先是syncFrameState处理,同步Frame的State:
bool DrawFrameTask::syncFrameState(TreeInfo& info) {
ATRACE_CALL();
int64_t vsync = mFrameInfo[static_cast(FrameInfoIndex::Vsync)];
mRenderThread->timeLord().vsyncReceived(vsync);
bool canDraw = mContext->makeCurrent();
mContext->unpinImages();
for (size_t i = 0; i < mLayers.size(); i++) {
mLayers[i]->apply();
}
mLayers.clear();
mContext->setContentDrawBounds(mContentDrawBounds);
mContext->prepareTree(info, mFrameInfo, mSyncQueued, mTargetNode);
// This is after the prepareTree so that any pending operations
// (RenderNode tree state, prefetched layers, etc...) will be flushed.
if (CC_UNLIKELY(!mContext->hasSurface() || !canDraw)) {
if (!mContext->hasSurface()) {
mSyncResult |= SyncResult::LostSurfaceRewardIfFound;
} else {
// If we have a surface but can't draw we must be stopped
mSyncResult |= SyncResult::ContextIsStopped;
}
info.out.canDrawThisFrame = false;
}
if (info.out.hasAnimations) {
if (info.out.requiresUiRedraw) {
mSyncResult |= SyncResult::UIRedrawRequired;
}
}
// If prepareTextures is false, we ran out of texture cache space
return info.prepareTextures;
}
- makeCurrent,这个从早期的版本就有,早期只有Opengl pipeline时,Opengl只支持单线程。我们首先要通过makeCurrent,告诉GPU处理当前的上下文(context)。
- unpinImages,hwui为了提高速度,对各种object都做了cache,这里的unpin,就是让cache去做unpin,以前的都不要了。
- setContentDrawBounds,设置绘制的区域大小
- prepareTree,前面我们也说过,Android View是树型结构的,这就是在绘制之前,去准备这些Tree节点的绘图操作Ops。这个过程也是非常的复杂。
回到run函数,syncFrameState后,如果,可以绘制,也就是存在更新。直接让CanvasContext去绘制了。
CanvasContext的draw是在RenderPipeline中完成的。而Ops的渲染则是通过BakedOpRenderer完成。默认用的是OpenGLPipeline,简单的来看,这段流程。

其中就两个主要的流程:PrepareTree和Draw。在流程图上,只是标记了一下,没有仔细的画。下面的我们来看看,这里都做了什么,我们的界面是怎么画出来的。
Node Tree的准备
离开我们的测试应用代码很久了,回来测试的代码。此时,RenderThread,DrawFrameTask,CanvasContext等已经就绪,绘制操纵已经被添加到了DisplayList中。
那么DisplayList,是怎么到CanvasContext中进行绘制的呢?
我们接着来看测试代码,接下来,就是Surface的unlock和post操纵。
mSurface.unlockCanvasAndPost(canvas);
SurfaceHolder直接调的Surface的unlockCanvasAndPost。
@Override
public void unlockCanvasAndPost(Canvas canvas) {
mSurface.unlockCanvasAndPost(canvas);
mSurfaceLock.unlock();
}
由于我们采用的hardware Context,走的HwuiContext的分支。
public void unlockCanvasAndPost(Canvas canvas) {
synchronized (mLock) {
checkNotReleasedLocked();
if (mHwuiContext != null) {
mHwuiContext.unlockAndPost(canvas);
} else {
unlockSwCanvasAndPost(canvas);
}
}
}
HwuiContext的unlockAndPost函数如下:
void unlockAndPost(Canvas canvas) {
if (canvas != mCanvas) {
throw new IllegalArgumentException("canvas object must be the same instance that "
+ "was previously returned by lockCanvas");
}
mRenderNode.end(mCanvas);
mCanvas = null;
nHwuiDraw(mHwuiRenderer);
}
我们在lockCanvas时,mRenderNode.start,unlock时,调的mRenderNode.end。
Node结束时,先结束Canvas的录制,然后将录制的List,给到RenderNode。
public void end(DisplayListCanvas canvas) {
long displayList = canvas.finishRecording();
nSetDisplayList(mNativeRenderNode, displayList);
canvas.recycle();
}
记住,Canvas录制的List,给到了RenderNode。这很重要。
finishRecording,我们直接看最后native的实现。
DisplayList* RecordingCanvas::finishRecording() {
restoreToCount(1);
mPaintMap.clear();
mRegionMap.clear();
mPathMap.clear();
DisplayList* displayList = mDisplayList;
mDisplayList = nullptr;
mSkiaCanvasProxy.reset(nullptr);
return displayList;
}
返回的就是前面我们已经录制好的mDisplayList。
录制好的DisplayList,最后给到哪儿呢?
nSetDisplayListJNI实现如下:
static void android_view_RenderNode_setDisplayList(JNIEnv* env,
jobject clazz, jlong renderNodePtr, jlong displayListPtr) {
RenderNode* renderNode = reinterpret_cast(renderNodePtr);
DisplayList* newData = reinterpret_cast(displayListPtr);
renderNode->setStagingDisplayList(newData);
}
JNI再通过setStagingDisplayList,给到RenderNode的mStagingDisplayList
void RenderNode::setStagingDisplayList(DisplayList* displayList) {
mValid = (displayList != nullptr);
mNeedsDisplayListSync = true;
delete mStagingDisplayList;
mStagingDisplayList = displayList;
}
到此,录制的Ops,是不是都给到RenderNode的mStagingDisplayList了。
现在,我们可以来看CanvasContext的PrepareTree了。
* frameworks/base/libs/hwui/renderthread/CanvasContext.cpp
void CanvasContext::prepareTree(TreeInfo& info, int64_t* uiFrameInfo, int64_t syncQueued,
RenderNode* target) {
mRenderThread.removeFrameCallback(this);
... ... //处理frame信息
info.damageAccumulator = &mDamageAccumulator;
info.layerUpdateQueue = &mLayerUpdateQueue;
mAnimationContext->startFrame(info.mode);
mRenderPipeline->onPrepareTree();
for (const sp& node : mRenderNodes) {
// 只有Primary的node是 FULL,其他都是实时
info.mode = (node.get() == target ? TreeInfo::MODE_FULL : TreeInfo::MODE_RT_ONLY);
node->prepareTree(info);
GL_CHECKPOINT(MODERATE);
}
mAnimationContext->runRemainingAnimations(info);
GL_CHECKPOINT(MODERATE);
freePrefetchedLayers();
GL_CHECKPOINT(MODERATE);
mIsDirty = true;
// 如果,窗口已经没有Native Surface,这一帧就丢掉。
if (CC_UNLIKELY(!mNativeSurface.get())) {
mCurrentFrameInfo->addFlag(FrameInfoFlags::SkippedFrame);
info.out.canDrawThisFrame = false;
return;
}
... ...
}
第一个问题,info是什么,从哪儿来的?从DrawFrameTask中来的。
void DrawFrameTask::run() {
ATRACE_NAME("DrawFrame");
bool canUnblockUiThread;
bool canDrawThisFrame;
{
TreeInfo info(TreeInfo::MODE_FULL, *mContext);
canUnblockUiThread = syncFrameState(info);
canDrawThisFrame = info.out.canDrawThisFrame;
}
TreeInfo顾名思义,描述Viewtree的,也就是RenderNode tree。
TreeInfo(TraversalMode mode, renderthread::CanvasContext& canvasContext)
: mode(mode), prepareTextures(mode == MODE_FULL), canvasContext(canvasContext) {}
注意这里的mode为TreeInfo::MODE_FULL。只有Primary的node是 FULL,其他都是实时。
Context可能会有多个Node,每个Node都进行Prepare。
* frameworks/base/libs/hwui/RenderNode.cpp
void RenderNode::prepareTree(TreeInfo& info) {
ATRACE_CALL();
LOG_ALWAYS_FATAL_IF(!info.damageAccumulator, "DamageAccumulator missing");
MarkAndSweepRemoved observer(&info);
// The OpenGL renderer reserves the stencil buffer for overdraw debugging. Functors
// will need to be drawn in a layer.
bool functorsNeedLayer = Properties::debugOverdraw && !Properties::isSkiaEnabled();
prepareTreeImpl(observer, info, functorsNeedLayer);
}
在RenderNode进行Prepare时,先对TreeInfo进行封,MarkAndSweepRemoved,主要是对可能的Node进行标记,删除。MarkAndSweepRemoved的代码如下:
class MarkAndSweepRemoved : public TreeObserver {
PREVENT_COPY_AND_ASSIGN(MarkAndSweepRemoved);
public:
explicit MarkAndSweepRemoved(TreeInfo* info) : mTreeInfo(info) {}
void onMaybeRemovedFromTree(RenderNode* node) override { mMarked.emplace_back(node); }
~MarkAndSweepRemoved() {
for (auto& node : mMarked) {
if (!node->hasParents()) {
node->onRemovedFromTree(mTreeInfo);
}
}
}
private:
FatVector, 10> mMarked;
TreeInfo* mTreeInfo;
};
能从tree上删除的就添加到mMarked中,在析构函数中,再对mMarked的mode进行删除。
prepareTreeImpl是RenderNode真正进行Prepare的地方。
void RenderNode::prepareTreeImpl(TreeObserver& observer, TreeInfo& info, bool functorsNeedLayer) {
info.damageAccumulator->pushTransform(this);
if (info.mode == TreeInfo::MODE_FULL) {
pushStagingPropertiesChanges(info);
}
uint32_t animatorDirtyMask = 0;
if (CC_LIKELY(info.runAnimations)) {
animatorDirtyMask = mAnimatorManager.animate(info);
}
bool willHaveFunctor = false;
if (info.mode == TreeInfo::MODE_FULL && mStagingDisplayList) {
willHaveFunctor = mStagingDisplayList->hasFunctor();
} else if (mDisplayList) {
willHaveFunctor = mDisplayList->hasFunctor();
}
bool childFunctorsNeedLayer =
mProperties.prepareForFunctorPresence(willHaveFunctor, functorsNeedLayer);
if (CC_UNLIKELY(mPositionListener.get())) {
mPositionListener->onPositionUpdated(*this, info);
}
prepareLayer(info, animatorDirtyMask);
if (info.mode == TreeInfo::MODE_FULL) {
pushStagingDisplayListChanges(observer, info);
}
if (mDisplayList) {
info.out.hasFunctors |= mDisplayList->hasFunctor();
bool isDirty = mDisplayList->prepareListAndChildren(
observer, info, childFunctorsNeedLayer,
[](RenderNode* child, TreeObserver& observer, TreeInfo& info,
bool functorsNeedLayer) {
child->prepareTreeImpl(observer, info, functorsNeedLayer);
});
if (isDirty) {
damageSelf(info);
}
}
pushLayerUpdate(info);
info.damageAccumulator->popTransform();
}
damageAccumulator是从CanvasContext中传过来的,是CanvasContext的成员,damage的累乘器。主要是用来标记,屏幕的那些区域被破坏了,需要重新绘制,所有的RenderNode累加起来,就是总的。
我们来看一眼pushTransform。
void DamageAccumulator::pushCommon() {
if (!mHead->next) {
DirtyStack* nextFrame = mAllocator.create_trivial();
nextFrame->next = nullptr;
nextFrame->prev = mHead;
mHead->next = nextFrame;
}
mHead = mHead->next;
mHead->pendingDirty.setEmpty();
}
void DamageAccumulator::pushTransform(const RenderNode* transform) {
pushCommon();
mHead->type = TransformRenderNode;
mHead->renderNode = transform;
}
damage累加器中,每一个元素由DirtyStack描述,分两种类型:TransformMatrix4和TransformRenderNode。采用一个双向链表mHead进行管理。
pushStagingPropertiesChanges,property是对RenderNode的描述,也就是对View的描述,比如大小,位置等。有两个状态,正在使用的syncProperties和待处理的mStagingProperties。syncProperties时,将mStagingProperties赋值给syncProperties。这里,很多状态都是这样同步的。
pushStagingDisplayListChanges,和前面的Property一样的流程,只是这里是syncDisplayList。这样,前面录制好Ops,就通过mStagingDisplayList传给mDisplayList。
绘制的Ops都放在mDisplayList中,这边会去递归的调用每个RenderNode的prepareTreeImpl。
pushLayerUpdate,将要更新的RenderNode都加到TreeInfo的layerUpdateQueue中,还有其对应的damage大小。
累加器的popTransform,就是将该Node的DirtyStack生效。
Prepare完成,代码量还是非常多的,我们主要关心我们的数据流。DisplayList的数据,不是更新到了Context的mLayerUpdateQueue中?
绘制
CanvasContext Prepare完后,绘制一帧的数据就准备好了。绘制是在各自的pipeline中进行的。OpenGLPipeline的绘制流程如下:
bool OpenGLPipeline::draw(const Frame& frame, const SkRect& screenDirty, const SkRect& dirty,
const FrameBuilder::LightGeometry& lightGeometry,
LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds,
bool opaque, bool wideColorGamut,
const BakedOpRenderer::LightInfo& lightInfo,
const std::vector>& renderNodes,
FrameInfoVisualizer* profiler) {
mEglManager.damageFrame(frame, dirty);
bool drew = false;
auto& caches = Caches::getInstance();
FrameBuilder frameBuilder(dirty, frame.width(), frame.height(), lightGeometry, caches);
frameBuilder.deferLayers(*layerUpdateQueue);
layerUpdateQueue->clear();
frameBuilder.deferRenderNodeScene(renderNodes, contentDrawBounds);
BakedOpRenderer renderer(caches, mRenderThread.renderState(), opaque, wideColorGamut,
lightInfo);
frameBuilder.replayBakedOps(renderer);
ProfileRenderer profileRenderer(renderer);
profiler->draw(profileRenderer);
drew = renderer.didDraw();
// post frame cleanup
caches.clearGarbage();
caches.pathCache.trim();
caches.tessellationCache.trim();
#if DEBUG_MEMORY_USAGE
caches.dumpMemoryUsage();
#else
if (CC_UNLIKELY(Properties::debugLevel & kDebugMemory)) {
caches.dumpMemoryUsage();
}
#endif
return drew;
}
Frame是描述一帧数据信息的,主要是宽,高,ufferAge,和Surface这几个属性。绘制开始时,由EglManager根据Surface的属性构建。
Frame EglManager::beginFrame(EGLSurface surface) {
LOG_ALWAYS_FATAL_IF(surface == EGL_NO_SURFACE, "Tried to beginFrame on EGL_NO_SURFACE!");
makeCurrent(surface);
Frame frame;
frame.mSurface = surface;
eglQuerySurface(mEglDisplay, surface, EGL_WIDTH, &frame.mWidth);
eglQuerySurface(mEglDisplay, surface, EGL_HEIGHT, &frame.mHeight);
frame.mBufferAge = queryBufferAge(surface);
eglBeginFrame(mEglDisplay, surface);
return frame;
}
damageFrame主要是部分更新参数的设置,前面我们也damage的区域就是前面Prepare时累加器累加出来的。
FrameBuilder,用来创建一帧Frame,继承CanvasStateClient。
FrameBuilder::FrameBuilder(const SkRect& clip, uint32_t viewportWidth, uint32_t viewportHeight,
const LightGeometry& lightGeometry, Caches& caches)
: mStdAllocator(mAllocator)
, mLayerBuilders(mStdAllocator)
, mLayerStack(mStdAllocator)
, mCanvasState(*this)
, mCaches(caches)
, mLightRadius(lightGeometry.radius)
, mDrawFbo0(true) {
// Prepare to defer Fbo0
auto fbo0 = mAllocator.create(viewportWidth, viewportHeight, Rect(clip));
mLayerBuilders.push_back(fbo0);
mLayerStack.push_back(0);
mCanvasState.initializeSaveStack(viewportWidth, viewportHeight, clip.fLeft, clip.fTop,
clip.fRight, clip.fBottom, lightGeometry.center);
}
FrameBuilder创建一个LayerBuilder的List来记录Rendernode的绘制状态,然后以倒序的方式去replay录制的RenderNode。
deferLayers主要是做了一个倒序,所有的RenderNode进行倒序,RenderNode的Ops也进行倒序。
void FrameBuilder::deferLayers(const LayerUpdateQueue& layers) {
// Render all layers to be updated, in order. Defer in reverse order, so that they'll be
// updated in the order they're passed in (mLayerBuilders are issued to Renderer in reverse)
for (int i = layers.entries().size() - 1; i >= 0; i--) {
RenderNode* layerNode = layers.entries()[i].renderNode.get();
// only schedule repaint if node still on layer - possible it may have been
// removed during a dropped frame, but layers may still remain scheduled so
// as not to lose info on what portion is damaged
OffscreenBuffer* layer = layerNode->getLayer();
if (CC_LIKELY(layer)) {
ATRACE_FORMAT("Optimize HW Layer DisplayList %s %ux%u", layerNode->getName(),
layerNode->getWidth(), layerNode->getHeight());
Rect layerDamage = layers.entries()[i].damage;
// TODO: ensure layer damage can't be larger than layer
layerDamage.doIntersect(0, 0, layer->viewportWidth, layer->viewportHeight);
layerNode->computeOrdering();
// map current light center into RenderNode's coordinate space
Vector3 lightCenter = mCanvasState.currentSnapshot()->getRelativeLightCenter();
layer->inverseTransformInWindow.mapPoint3d(lightCenter);
saveForLayer(layerNode->getWidth(), layerNode->getHeight(), 0, 0, layerDamage,
lightCenter, nullptr, layerNode);
if (layerNode->getDisplayList()) {
deferNodeOps(*layerNode);
}
restoreForLayer();
}
}
}
倒序的目的,其实就是解决谁先画,谁后画的问题。Node都是Tree结构,如果子tree先绘制,父tree后绘制,这样后绘制的就会将前面绘制的遮盖住,看不见了。注意我们的数据流,倒序后的Layer放在mLayerBuilders中。
BakedOpRenderer是渲染器Renderer。它是主要的渲染管理者,用以管理渲染的任务集合,比如一帧数据,和包含的FBO。管理着他们的生命周期,绑定FrameBuffer。这是FBO创建,销毁等的唯一的地方。而所有的渲染操纵都是通过Dispatcher进行传递。
BakedOpRenderer(Caches& caches, RenderState& renderState, bool opaque, bool wideColorGamut,
const LightInfo& lightInfo)
: mGlopReceiver(DefaultGlopReceiver)
, mRenderState(renderState)
, mCaches(caches)
, mOpaque(opaque)
, mWideColorGamut(wideColorGamut)
, mLightInfo(lightInfo) {}
mGlopReceiver是一个函数指针,默认为DefaultGlopReceiver。
static void DefaultGlopReceiver(BakedOpRenderer& renderer, const Rect* dirtyBounds,
const ClipBase* clip, const Glop& glop) {
renderer.renderGlopImpl(dirtyBounds, clip, glop);
}
replayBakedOps是一个模板函数,这样就可以自由决定录制Ops被replay的地方。它包含一个lambdas数组,通过这个数组,replay时,,录制的BakeOpState就能够通过state->op->opId找到对应的接收者进行replay。
replayBakedOps函数实现如下:
template
void replayBakedOps(Renderer& renderer) {
std::vector temporaryLayers;
finishDefer();
#define X(Type) \
[](void* renderer, const BakedOpState& state) { \
StaticDispatcher::on##Type(*(static_cast(renderer)), \
static_cast(*(state.op)), state); \
},
static BakedOpReceiver unmergedReceivers[] = BUILD_RENDERABLE_OP_LUT(X);
#undef X
#define X(Type) \
[](void* renderer, const MergedBakedOpList& opList) { \
StaticDispatcher::onMerged##Type##s(*(static_cast(renderer)), opList); \
},
static MergedOpReceiver mergedReceivers[] = BUILD_MERGEABLE_OP_LUT(X);
#undef X
// Relay through layers in reverse order, since layers
// later in the list will be drawn by earlier ones
for (int i = mLayerBuilders.size() - 1; i >= 1; i--) {
GL_CHECKPOINT(MODERATE);
LayerBuilder& layer = *(mLayerBuilders[i]);
if (layer.renderNode) {
// cached HW layer - can't skip layer if empty
renderer.startRepaintLayer(layer.offscreenBuffer, layer.repaintRect);
GL_CHECKPOINT(MODERATE);
layer.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
GL_CHECKPOINT(MODERATE);
renderer.endLayer();
} else if (!layer.empty()) {
// save layer - skip entire layer if empty (in which case, LayerOp has null layer).
layer.offscreenBuffer = renderer.startTemporaryLayer(layer.width, layer.height);
temporaryLayers.push_back(layer.offscreenBuffer);
GL_CHECKPOINT(MODERATE);
layer.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
GL_CHECKPOINT(MODERATE);
renderer.endLayer();
}
}
GL_CHECKPOINT(MODERATE);
if (CC_LIKELY(mDrawFbo0)) {
const LayerBuilder& fbo0 = *(mLayerBuilders[0]);
renderer.startFrame(fbo0.width, fbo0.height, fbo0.repaintRect);
GL_CHECKPOINT(MODERATE);
fbo0.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
GL_CHECKPOINT(MODERATE);
renderer.endFrame(fbo0.repaintRect);
}
for (auto& temporaryLayer : temporaryLayers) {
renderer.recycleTemporaryLayer(temporaryLayer);
}
}
这个表和前面我们在录制的流程中说的LUT就对应起来了,unmergedReceivers和mergedReceivers分别和对应的LUT表对应。比如我们的ColorOp,就调的BakedOpDispatcher::onColorOp。另外要注意的是,我们的drawColor是从fbo0这里调的。
void BakedOpDispatcher::onColorOp(BakedOpRenderer& renderer, const ColorOp& op,
const BakedOpState& state) {
SkPaint paint;
paint.setColor(op.color);
paint.setBlendMode(op.mode);
Glop glop;
GlopBuilder(renderer.renderState(), renderer.caches(), &glop)
.setRoundRectClipState(state.roundRectClipState)
.setMeshUnitQuad()
.setFillPaint(paint, state.alpha)
.setTransform(Matrix4::identity(), TransformFlags::None)
.setModelViewMapUnitToRect(state.computedState.clipState->rect)
.build();
renderer.renderGlop(state, glop);
}
我们需要绘制的color值,直接设置到画笔paint,blend模式也设置到paint。
这部分的逻辑在LayerBuilder的replayBakedOpsImpl函数中。
void LayerBuilder::replayBakedOpsImpl(void* arg, BakedOpReceiver* unmergedReceivers,
MergedOpReceiver* mergedReceivers) const {
if (renderNode) {
ATRACE_FORMAT_BEGIN("Issue HW Layer DisplayList %s %ux%u", renderNode->getName(), width,
height);
} else {
ATRACE_BEGIN("flush drawing commands");
}
for (const BatchBase* batch : mBatches) {
size_t size = batch->getOps().size();
if (size > 1 && batch->isMerging()) {
int opId = batch->getOps()[0]->op->opId;
const MergingOpBatch* mergingBatch = static_cast(batch);
MergedBakedOpList data = {batch->getOps().data(), size,
mergingBatch->getClipSideFlags(),
mergingBatch->getClipRect()};
mergedReceivers[opId](arg, data);
} else {
for (const BakedOpState* op : batch->getOps()) {
unmergedReceivers[op->op->opId](arg, *op);
}
}
}
ATRACE_END();
}
我们的drawcolor是从unmergedReceivers调的!
代码写的确实复杂,得慢慢的看,看明白后,有以后就可以跳过这一块的逻辑了,直接去看Ops绘制的地方~
渲染Ops的时,又被封装了一次,都被封装成Glop。Glop由GlopBuilder统一构建。构建完后,由renderGlop进行渲染。
void renderGlop(const BakedOpState& state, const Glop& glop) {
renderGlop(&state.computedState.clippedBounds, state.computedState.getClipIfNeeded(), glop);
}
void renderGlop(const Rect* dirtyBounds, const ClipBase* clip, const Glop& glop) {
mGlopReceiver(*this, dirtyBounds, clip, glop);
}
mGlopReceiver是一个函数指针,指向的是DefaultGlopReceiver。封装一下,最后的实现为BakedOpRenderer的renderGlopImpl。
renderGlopImpl函数如下:
void BakedOpRenderer::renderGlopImpl(const Rect* dirtyBounds, const ClipBase* clip,
const Glop& glop) {
prepareRender(dirtyBounds, clip);
// Disable blending if this is the first draw to the main framebuffer, in case app has defined
// transparency where it doesn't make sense - as first draw in opaque window. Note that we only
// apply this improvement when the blend mode is SRC_OVER - other modes (e.g. CLEAR) can be
// valid draws that affect other content (e.g. draw CLEAR, then draw DST_OVER)
bool overrideDisableBlending = !mHasDrawn && mOpaque && !mRenderTarget.frameBufferId &&
glop.blend.src == GL_ONE &&
glop.blend.dst == GL_ONE_MINUS_SRC_ALPHA;
mRenderState.render(glop, mRenderTarget.orthoMatrix, overrideDisableBlending);
if (!mRenderTarget.frameBufferId) mHasDrawn = true;
}
在renderGlopImpl中,准备了一个Render,最终是通过mRenderState的render进行渲染。在RenderState的render中,直接调用OpenGLES的接口,需绘制我们的Ops了。具体怎么绘制的,就是OpenGL的问题了,这里就不看了,交给OpenGL去吧。
waitOnFences等待所有的task已经绘制完成,这里的fence和BufferQueue那边的Fence不是同一个概念。绘制完后,通过swapBuffers函数,交换buffer,将绘制完的数据送去显示。
另外,hwui中还做了很多Jank的跟踪,便于debug性能
小结
测试代码才几行,底层却折腾了这么多,我们来总结一下:
- 硬件绘制,或硬件加速,就是通过hwui,将2D的绘图操纵转换为3D的绘图
- 每一个绘制采用一个RecordedOp进行描述,复杂的绘图将被拆分成简单的基本绘图,并利用RecordingCanvas进行录制。
- 每个View都对应RenderNode,而每个界面有一个DisplayList,用以保存录制的Ops。
- 每个进程只有一个RenderThread,所有的绘图都在RenderThread中完成,因此,其他线程的操纵都通过Task或WorkItem的形式post到RenderThread中完成。DrawFrameTask是RenderThread中比较特殊的一个task,是用以绘制整个界面的,跟随Vync而触发。
- OpenGL是单线程的,所以每个RenderThread都有各自的上下文,CanvasContext,通过Preparetree,将DisplayList中Ops都同步到CanvasContext的layerUpdateQueue中,准备好绘制帧的数据。
- 绘制是由具体的Pipeline完成的,目前有3中类型的Pipeline,OpenGLPipeline是默认的Pipeline。
- OpenGLPipeline绘制时,通过FrameBuilder和LayerBuilder,将DisplayList的数据进一步封装。在replayBakedOps时,将Opo的操纵转换为具体的绘制操纵,通过BakedOpDispatcher分发给BakedOpRenderer进行渲染。而真正的渲染是在mRenderState完成,直接调用OpenGL的接口。
这中间,只要抓住数据流,Ops和DisplayList,这条主线,理解起来就轻松些。总的来说,可以分为以下几个部分,我们用一张总体的图来描述:
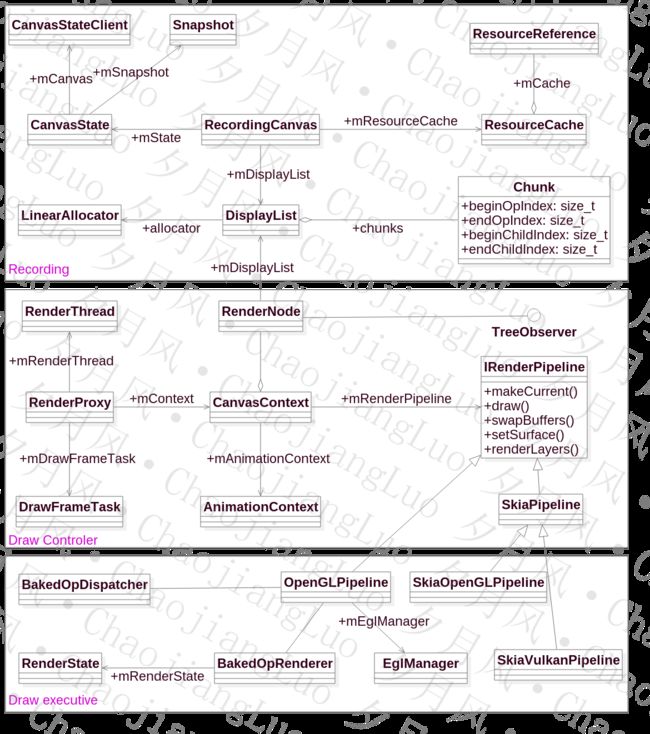
- Recording部分,这部分主要是2D到3D的转换,录制绘图操纵Ops
- Draw 控制部分,这部分主要和上层应用和显示系统同步,控制绘制的进行,包括动画的处理
- Draw的执行部分,这部分主要和具体的加速系统交互,采用具体的加速API进行界面的绘制
以上就是结合测试代码,讲解的hwui的具体内容。