本文对 Ensemble Model: Stacked Model Example 中的 R 语言代码进行详解。
本段代码介绍如下:
本文介绍了一种 ensemble model 即将若干种模型的预测结果合并,来获取房屋价格的预测值。
如下图标显示,其中 features sets 可以是一种或多种属性集合:
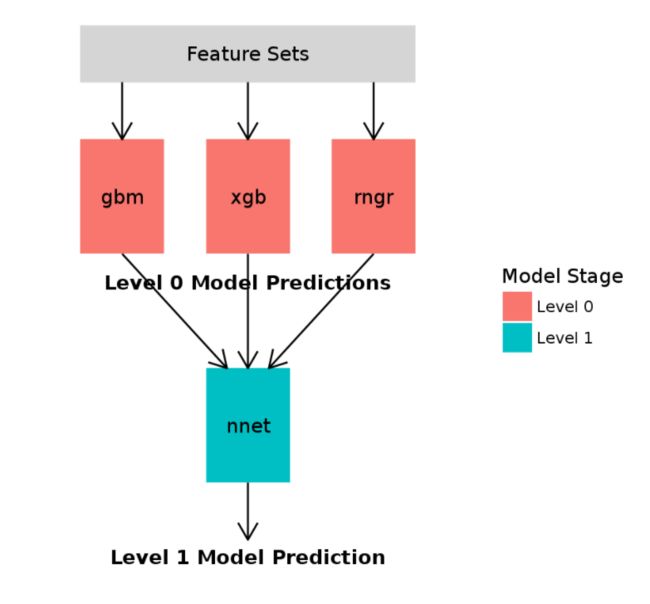
1. 数据准备
1.1 数据获取
train.raw <- read.csv(file.path(DATA.DIR,"train.csv"),stringsAsFactors = FALSE)
test.raw <- read.csv(file.path(DATA.DIR,"test.csv"), stringsAsFactors = FALSE)
1.2 数据初始化
1.2.1 选取重要的 features 并分类
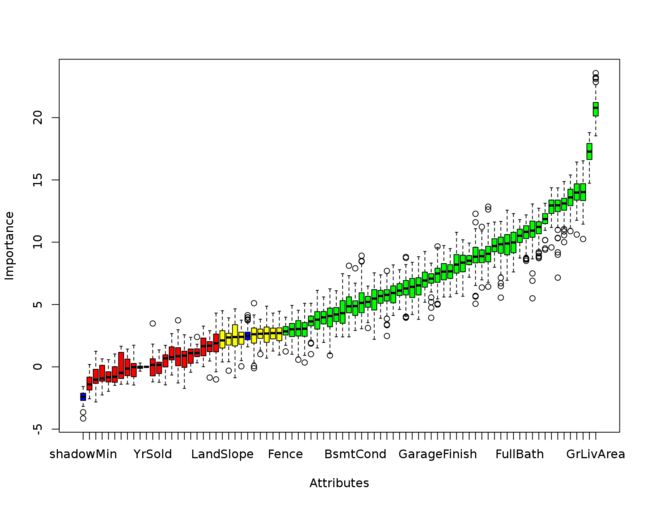
计算 features 的重要性
具体请参见 Boruta Feature Importance Analysis。主要步骤如下:
区分字符型和数字型数据
给数据集分类
填充缺失值
1.数字型缺失则设为 -1
2.字符型缺失则设为“*MISSING"-
执行 Boruta 分析,获取 features 的重要程度
set.seed(13) bor.results <- Boruta(sample.df,response, maxRuns=101, doTrace=0)
执行后结果 plot 如下:
分类 features
代码示例如下:
CONFIRMED_ATTR <- c("MSSubClass","MSZoning","LotArea","LotShape",
"LandContour","Neighborhood", …… ,"Fence")
1.2.2 为 Cross validation 进行数据分割
# create folds for training
set.seed(13)
data_folds <- createFolds(train.raw$SalePrice, k=5)
语法说明:createFolds(train.raw$SalePrice, k=5)
Create Level 0 Model Feature Sets
将拆分出两个 Feature Set, Feature Set 1 和 2
都包括 Boruta Confirmed and Tentative attributes。此处的每一个 Feature Set 都是由用户自定义的 R 函数生成的。这些函数将原始的 Training Set 变成 Feature Set。此处并没有使用额外的 Feature Engineering。
1.3 Feature Set 1
对 SalePrice 数据取 Log - Boruta Confirmed and tentative Attributes
具体语法:
id <- df$Id
if (class(df$SalePrice) != "NULL") {
y <- log(df$SalePrice)
} else {
y <- NULL
}
** 填补缺失值**
具体语法:
# for numeric set missing values to -1 for purposes
num_attr <- intersect(predictor_vars,DATA_ATTR_TYPES$integer)
for (x in num_attr){
predictors[[x]][is.na(predictors[[x]])] <- -1
}
# for character atributes set missing value
char_attr <- intersect(predictor_vars,DATA_ATTR_TYPES$character)
for (x in char_attr){
predictors[[x]][is.na(predictors[[x]])] <- "*MISSING*"
predictors[[x]] <- factor(predictors[[x]])
}
1.4 Feature Set 2(xgboost)
同 Feature Set 1,首先对 SalePrice 数据取 Log。
同 Feature Set 1,然后填补缺失值。
2. Level 0 Model Training
2.1 Helper Function For Training
为后续建模做一些准备的工作,包括根据 cross-validation 中的一份数据而建模(trainOneFold)以及根据这份数据及其模型得到预测值。
** train model on one data fold**
如下将合并为一个 funcion - prepL0FeatureSet1:
1.获取特定的一份 cross-validation 数据, 即 get fold specific cv data
cv.data <- list()
cv.data$predictors <- feature_set$train$predictors[this_fold,]
cv.data$ID <- feature_set$train$id[this_fold]
cv.data$y <- feature_set$train$y[this_fold]
2.对这一份数据,获得相应的 training data, 即
get training data for specific fold。
train.data <- list()
train.data$predictors <- feature_set$train$predictors[-this_fold,]
train.data$y <- feature_set$train$y[-this_fold]
3.使用 do.call() 一次性执行操作,寻找合适的 model。
fitted_mdl <- do.call(train,
c(list(x=train.data$predictors,y=train.data$y),
CARET.TRAIN.PARMS,
MODEL.SPECIFIC.PARMS,
CARET.TRAIN.OTHER.PARMS))
其中,
- do.call constructs and executes a function call from a name or a function and a list of arguments to be passed to it.
- R 语言中 train():Fit Predictive Models Over Different Tuning Parameters.
4.获取预测值, 即 make prediction from a model fitted to one fold。
yhat <- predict(fitted_mdl,newdata = cv.data$predictors,type = "raw")
score <- rmse(cv.data$y,yhat)
ans <- list(fitted_mdl=fitted_mdl,
score=score,
predictions=data.frame(ID=cv.data$ID,yhat=yhat,y=cv.data$y))
make prediction from a model fitted to one fold
根据已有的模型进行预测,如下也包装成一个函数 function - makeOneFoldTestPrediction:
fitted_mdl <- this_fold$fitted_mdl
yhat <- predict(fitted_mdl,newdata = feature_set$test$predictors,type = "raw")
2.2 gbm model
set caret training parameters
The caret
package (short for _C_lassification _A_nd _RE_gression _T_raining) is a set of functions that attempt to streamline the process for creating predictive models. The package contains tools for:
- data splitting
- pre-processing
- feature selection
- model tuning using resampling
- variable importance estimation
CARET.TRAIN.PARMS <-list(method="gbm")
CARET.TUNE.GRID <-expand.grid(n.trees=100,
interaction.depth=10,
shrinkage=0.1,
n.minobsinnode=10)
MODEL.SPECIFIC.PARMS <- list(verbose=0)
其中,
expand.grid(): 由所有的 supplied vectors or factors 新建一个 data frame 。
model specific training parameter
CARET.TRAIN.CTRL <- trainControl(method="none",
verboseIter=FALSE,
classProbs=FALSE)
CARET.TRAIN.OTHER.PARMS <- list(trControl=CARET.TRAIN.CTRL,
tuneGrid=CARET.TUNE.GRID,
metric="RMSE")
其中,
trainControl 生成一些列参数,这些参数将进一步调控如何生成模型,可能的参数有:
method:resampling method
……
verboseIter: 逻辑语句来打印 training log。
classProbs: 逻辑语句来决定是否应该计算 class probabilities
generate features for Level 1
为后续 Level 1 Model Prediction 做准备。
gbm_set <- llply(data_folds,trainOneFold,L0FeatureSet1)
其中,trainOneFold 是一个训练 Model,LOFeatureSet1 是一个处理过的 Feature 集合。
final model fit
最终选定一个 GBM Model。
gbm_mdl <- do.call(train, c(list(x=L0FeatureSet1$train$predictors,y=L0FeatureSet1$train$y),
CARET.TRAIN.PARMS,
MODEL.SPECIFIC.PARMS,
CARET.TRAIN.OTHER.PARMS))
CV Error Estimate
cv_y <- do.call(c,lapply(gbm_set,function(x){x$predictions$y}))
cv_yhat <- do.call(c,lapply(gbm_set,function(x){x$predictions$yhat}))
rmse(cv_y,cv_yhat)
cat("Average CV rmse:",mean(do.call(c,lapply(gbm_set,function(x){x$score}))))
其中,cat is useful for producing output in user-defined functions.
** create test submission**
最终的预测值是根据不同的 data folds(根据 cross validation 分成了若干 data folds)适用的不同 model 而生成的预测值的平均值,并写入 .csv 文件。
test_gbm_yhat <- predict(gbm_mdl,newdata = L0FeatureSet1$test$predictors,type = "raw")
gbm_submission <- cbind(Id=L0FeatureSet1$test$id,SalePrice=exp(test_gbm_yhat))
write.csv(gbm_submission,file="gbm_sumbission.csv",row.names=FALSE)
2.3 xgboost model
xgboost model 的流程、算法和 gbm model 相同,具体解释不再赘述,仅将主要流程和语法列举如下:
set caret training parameters
CARET.TRAIN.PARMS <- list(method="xgbTree")
CARET.TUNE.GRID <- expand.grid(nrounds=800,
max_depth=10,
eta=0.03,
gamma=0.1,
colsample_bytree=0.4,
min_child_weight=1)
MODEL.SPECIFIC.PARMS <- list(verbose=0)
** model specific training parameter**
CARET.TRAIN.CTRL <- trainControl(method="none",
verboseIter=FALSE,
classProbs=FALSE)
CARET.TRAIN.OTHER.PARMS <- list(trControl=CARET.TRAIN.CTRL,
tuneGrid=CARET.TUNE.GRID,
metric="RMSE")
generate Level 1 features
xgb_set <- llply(data_folds,trainOneFold,L0FeatureSet2)
final model fit
xgb_mdl <- do.call(train, c(list(x=L0FeatureSet2$train$predictors,y=L0FeatureSet2$train$y),
CARET.TRAIN.PARMS,
MODEL.SPECIFIC.PARMS,
CARET.TRAIN.OTHER.PARMS))
CV Error Estimate
cv_y <- do.call(c,lapply(xgb_set,function(x){x$predictions$y}))
cv_yhat <- do.call(c,lapply(xgb_set,function(x){x$predictions$yhat}))
rmse(cv_y,cv_yhat)
cat("Average CV rmse:",mean(do.call(c,lapply(xgb_set,function(x){x$score}))))
** create test submission**
test_xgb_yhat <- predict(xgb_mdl,newdata = L0FeatureSet2$test$predictors,type = "raw")
xgb_submission <- cbind(Id=L0FeatureSet2$test$id,SalePrice=exp(test_xgb_yhat))
write.csv(xgb_submission,file="xgb_sumbission.csv",row.names=FALSE)
2.4 ranger model
ranger model 的流程、算法和 xgboost、gbm model 相同,具体解释不再赘述,仅将主要流程和语法列举如下:
set caret training parameters
CARET.TRAIN.PARMS <- list(method="ranger")
CARET.TUNE.GRID <- expand.grid(mtry=2*as.integer(sqrt(ncol(L0FeatureSet1$train$predictors))))
MODEL.SPECIFIC.PARMS <- list(verbose=0,num.trees=500)
model specific training parameter
CARET.TRAIN.CTRL <- trainControl(method="none",
verboseIter=FALSE,
classProbs=FALSE)
CARET.TRAIN.OTHER.PARMS <- list(trControl=CARET.TRAIN.CTRL,
tuneGrid=CARET.TUNE.GRID,
metric="RMSE")
generate Level 1 features
rngr_set <- llply(data_folds,trainOneFold,L0FeatureSet1)
final model fit
rngr_mdl <- do.call(train, c(list(x=L0FeatureSet1$train$predictors,y=L0FeatureSet1$train$y),
CARET.TRAIN.PARMS,
MODEL.SPECIFIC.PARMS,
CARET.TRAIN.OTHER.PARMS))
CV Error Estimate
cv_y <- do.call(c,lapply(rngr_set,function(x){x$predictions$y}))
cv_yhat <- do.call(c,lapply(rngr_set,function(x){x$predictions$yhat}))
rmse(cv_y,cv_yhat)
cat("Average CV rmse:",mean(do.call(c,lapply(rngr_set,function(x){x$score}))))
create test submission
test_rngr_yhat <- predict(rngr_mdl,newdata = L0FeatureSet1$test$predictors,type = "raw")
rngr_submission <- cbind(Id=L0FeatureSet1$test$id,SalePrice=exp(test_rngr_yhat))
write.csv(rngr_submission,file="rngr_sumbission.csv",row.names=FALSE)
3. Level 1 Model Training
根据之前的结果,gbm_set、xgb_set、rngr_set 分别指代的是 gbm、xgb、rngr 模型下取出来的 features, 获取使用三个模型的预测值。
gbm_yhat <- do.call(c,lapply(gbm_set,function(x){x$predictions$yhat}))
xgb_yhat <- do.call(c,lapply(xgb_set,function(x){x$predictions$yhat}))
rngr_yhat <- do.call(c,lapply(rngr_set,function(x){x$predictions$yhat}))
3.1 Create predictions For Level 1 Model
问题:如下这一段没有读懂具体语法。
L1FeatureSet$train$id <- do.call(c,lapply(gbm_set,function(x){x$predictions$ID}))
L1FeatureSet$train$y <- do.call(c,lapply(gbm_set,function(x){x$predictions$y}))
predictors <- data.frame(gbm_yhat,xgb_yhat,rngr_yhat)
predictors_rank <- t(apply(predictors,1,rank))
colnames(predictors_rank) <- paste0("rank_",names(predictors))
L1FeatureSet$train$predictors <- predictors #cbind(predictors,predictors_rank)
L1FeatureSet$test$id <- gbm_submission[,"Id"]
L1FeatureSet$test$predictors <- data.frame(gbm_yhat=test_gbm_yhat, xgb_yhat=test_xgb_yhat, rngr_yhat=test_rngr_yhat)
3.2 Neural Net Model
同之前 Level 0 Model 的大致流程:
** set caret training parameters**
CARET.TRAIN.PARMS <- list(method="nnet")
CARET.TUNE.GRID <- NULL # NULL 使用了默认的微调参数
model specific training parameter
CARET.TRAIN.CTRL <- trainControl(method="repeatedcv",
number=5,
repeats=1,
verboseIter=FALSE)
CARET.TRAIN.OTHER.PARMS <- list(trControl=CARET.TRAIN.CTRL,
maximize=FALSE,
tuneGrid=CARET.TUNE.GRID,
tuneLength=7,
metric="RMSE")
# Other model specific parameters
MODEL.SPECIFIC.PARMS <- list(verbose=FALSE,linout=TRUE,trace=FALSE)
train the model
l1_nnet_mdl <- do.call(train,
c(list(x=L1FeatureSet$train$predictors, y=L1FeatureSet$train$y),
CARET.TRAIN.PARMS,
MODEL.SPECIFIC.PARMS,
CARET.TRAIN.OTHER.PARMS))
附录
For additional information on model stacking see these references:
- MLWave: Kaggle Ensembling Guide
- Kaggle Forum Posting: Stacking
- Winning Data Science Competitions: Jeong-Yoon Lee This talk is about 90 minutes long. The sections relevant to model stacking are discussed in these segments (h:mm:ss to h:mm:ss): 1:05:25 to 1:12:15 and 1:21:30 to 1:27:00.