- 1. 多处理机简介
- 2. 多处理机硬件
- 2.1. UMA(Uniform Memory Access)
- 2.1.1. 基于总线的UMA多处理机体系结构
- 2.1.2. 基于交叉开关的UMA多处理机
- 2.1.3. 基于多级交换的UMA多处理机
- 2.2. NUMA(nonuniform memory access)
- 2.3. 多核芯片
- 2.1. UMA(Uniform Memory Access)
- 3. 多处理机操作系统类型
- 3.1. 每个 CPU 都有自己的操作系统
- 3.2. 主从多处理机
- 3.3. 对称多处理机(Symmetric MultiProcessor, SMP)
- 4. 多处理机调度
- 4.1. 分时
- 4.2. 空间共享
- 4.3. 群调度( Gang Scheduling)
- 4.3.1. 基本思想
- 4.3.2. 调度方法
- 5. 参考资料
1. 多处理机简介

共享存储器多处理机
每个cpu都可同样访问消息传递多计算机
通过某种高速互联网络连接在一起, 每个存储器局部对应一个cpu, 且只能被该cpu访问,这些cpu 通过互联网络发送多字消息通信
易于构建, 编程难广域分布式系统
通过广域网连接,如Internet,
多处理机是共享存储器多处理机的简称,多个cpu共享一个公用的RAM.
2. 多处理机硬件
所以多处理机都具有每个cpu可访问全部存储器的性质,而有些多处理机有一些特性,
2.1. UMA(Uniform Memory Access)
读出每个存储器字的速度一样快
2.1.1. 基于总线的UMA多处理机体系结构

2.1.2. 基于交叉开关的UMA多处理机
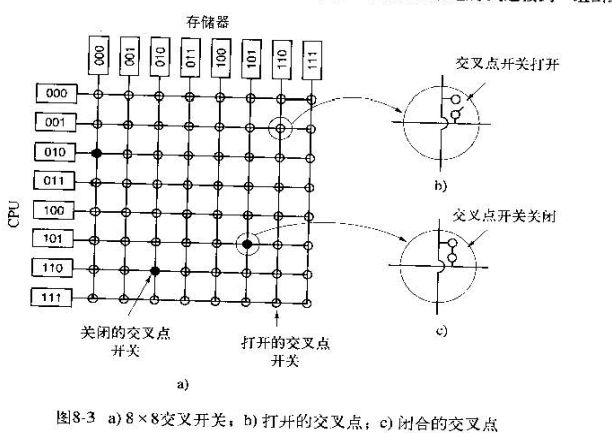
2.1.3. 基于多级交换的UMA多处理机


此开关检查module域来决定连入哪个存储器, 即连接x还是y
例如 Omega网络

n个cpu/存储器, 有 log 2n级, 每级只需n/2个开关,

比较:
| 网络 | 开关数 | 是否阻塞 |
|---|---|---|
| 交叉开关 | n2 | 不阻塞 |
| Omega网络 | n/2*log2n | 阻塞 |
2.2. NUMA(nonuniform memory access)
特性:
- 具有对所有cpu都可见的单个地址空间
- 通过 LOAD 和 STORE 指令来访问运程存储器
- 访问远程存储器慢于访问本地存储器
基于文件的多处理机
基本思想: 维护一个数据库来记录告诉缓存行的位置及其状态. 当一个高速缓存行被引用时,就查询数据库找出高速缓存行的位置以及它的dirty记录,(是否被修改过),
2.3. 多核芯片
每个核就是一个完整的 CPU , 可以共享内存, 但是 cache 不一定共享. 时常被成为 片级多处理机(Chip-level MultiProcessors, CMP).
与基于总线的多处理机和使用交换网络的多处理机的差别不大:
- 基于总线的 每个CPU 都有自己的cache
- CMP容错性低: 连接紧密, 一个共享模块的失效可能导致其他 CPU 出错
片上系统 (system on a chip)
芯片包含多个核,但是同时还包含若干个专业核, 比如视频与音频解码器, 加密芯片,网络接口等
3. 多处理机操作系统类型
3.1. 每个 CPU 都有自己的操作系统
优点: 共享操作系统代码

注意
- 在一个进程进行系统调用时,是在本机的 CPU 上被捕获并处理的,并使用操作系统表中的数据结构
- 因为每个操作系统都有自己的表,那么也有自己的进程集合, 通过自身调度这些进程,而没有进程共享. 如果一个用户登陆到 CPU1 , 那么他的进程全在 CPU1 上, 也就是可能导致其他CPU 空载
- 没有页面共享: 可能出现 CPU2 不断进行页面替换而 CPU1 却有多余的页面
- cache 不一致
3.2. 主从多处理机
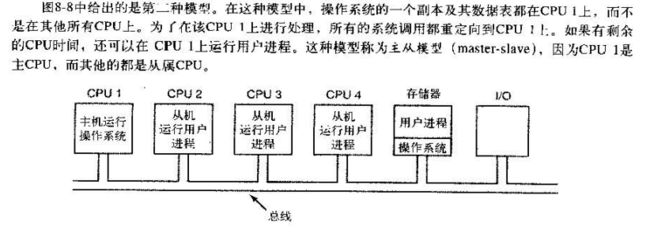
问题
如果有很多 CPU , 主 CPU 会成为瓶颈, 速度慢
3.3. 对称多处理机(Symmetric MultiProcessor, SMP)

消除了主从处理机的不对称性, 在存储器中有操作系统的一个副本, 但任何 CPU 都可以运行它.
这个模型动态平衡进程和存储器, 因为它只有一套操作系统数据表.
它存在的问题: 当两个或多个 CPU 同时运行操作系统代码时, 如请求同一个空闲存储器页面,这时应该使用互斥信号量(锁),使整个系统成为一大临界区. 这样在任一时刻只有一个 CPU 可运行操作系统
4. 多处理机调度
调度对象: 单进程还是多进程, 线程是内核进程还是用户线程.
- 用户线程: 对内核不可见,那么调度单个进程,.
- 内核线程: 调度单元是线程,
4.1. 分时

先讨论调度独立线程的情况, 如果有 CPU 空闲则选择优先级队列中的最优先线程到此 CPU
缺点:
- 随着 CPU 数量增加引起对调度数据结构的潜在竞争
- 当线程在 I/O 阻塞时引起上下文切换的开销(overhead)
亲和调度: 基本思想, 尽量使一个线程在它前一次运行过的 CPU 上运行,
4.2. 空间共享

当线程之间以某种方式彼此相关时, 可以使用此方法. 假设一组相关的线程是一次性创建的, 创建时, 检查是否有足够的空闲 CPU, 有 则 各自获得专用的 CPU, 否则等待,
优点: 消除了多道程序设计, 从而消除上下文切换开销
缺点: 当CPU被阻塞或根本无事可做时时间被浪费了
4.3. 群调度( Gang Scheduling)
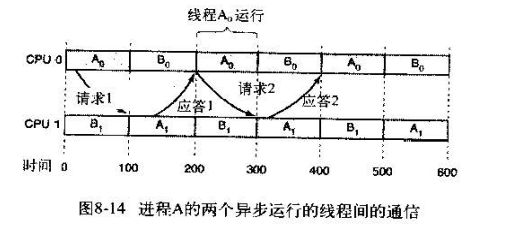
4.3.1. 基本思想
让一个进程的所有线程一起运行, 这样互相通信更方便,在一个时间片内可以发送和接收大量的消息.
4.3.2. 调度方法
- 把一组相关线程作为一个单位,即一个群, 一起调度
- 一个群中的所有成员在不同的分时 CPU 上同时运行
- 群中的所有成员共同开始和结束其时间片

5. 参考资料
- 现代操作系统
- Multi-Processor Systems | UCLA