字符串合并
paste('第',seq(5),'名')
#[1] "第 1 名" "第 2 名" "第 3 名" "第 4 名" "第 5 名"
paste('第',seq(5),'名',sep='')
#[1] "第1名" "第2名" "第3名" "第4名" "第5名"
paste0('第',seq(5),'名')
#[1] "第1名" "第2名" "第3名" "第4名" "第5名"
由以上可知,paste()默认连接符为空格,paste0()连接符为空,等于paste(sep = '')
paste(LETTERS[1:10],seq(5),sep = ':')
#[1] "A:1" "B:2" "C:3" "D:4" "E:5" "F:1" "G:2" "H:3" "I:4" "J:5"
paste(letters[1:4],seq(10),sep = '对')
#[1] "a对1" "b对2" "c对3" "d对4" "a对5" "b对6" "c对7" "d对8"
由以上可知,当被组合对象元素个数不相等时,会依次选取元素组合,最终的组合数等于元素个数多的那个
happen =["2019-03-06","南京","彩虹广场","理发师","手艺很棒","over"]
#[1] "2019-03-06" "南京" "彩虹广场" "理发师" "手艺很棒" "over"
paste(happen[1:length(happen)],collapse = '-')
#[1] "2019-03-06-南京-彩虹广场-理发师-手艺很棒-over"
针对变量内部元素进行拼接时,使用x[1:n]进行遍历,'n'小于x的维度
字符串的拆分
df = data.frame(taxa = paste('phylum','class','order','family',seq(100),'genera',sep = '_'),
site1 = runif(100,10,100),#随机生成100个10到100范围内的有理数
site2 = runif(100,10,20),
site3 = runif(100,1,10))
head(df)
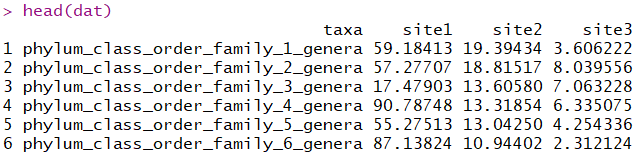
df$taxa = str_split_fixed(df$taxa,'_',5)[,5]
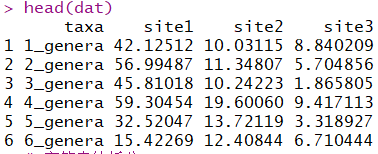
str_split_fixed(str,pattern,n),pattern为分隔符,如果pattern = '',则将str拆分成一个个字符,n表示将str拆分n个部分,若n小于str中分隔符个数,则只有前n-1个(3刀4段)分隔符发挥作用,后面的分隔符不起作用