HDFS是设计成一次写入,多次读取的场景,且不支持文件的修改
HDFS通常 位于 /hadoop-2.6.4/temp/dfs目录下
修改时间统一
date -s "2017-03-15 20:14:00"
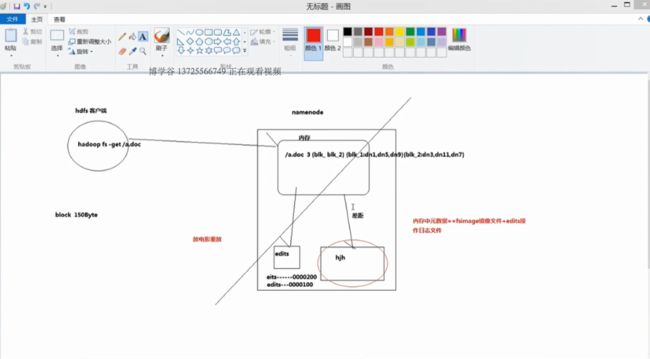
namenode
目录结构及文件分块位置的信息(元数据)的管理
datanode
文件的各个block的存储管理
shell命令操作
统一: hadoop fs
-ls:显示目录信息 hadoop fs -ls / 显示根目录信息
-mkdir (-p多级目录):创建目录 hadoop fs -mkdir /bbb 根目录上创建一个bbb的文件夹
-moveFromLocal:从本地剪贴到hdfs上 hadoop fs -moveFromlocal /root/app/a.txt(本地路径) /a(服务器路径)
-moveToLocal:从服务器剪贴到本地 hadoop fs -moveToLocal /aa/bb/1.txt服务器路径) /root/aaa(本地路径)
-appendToFile:追加一个文件到已经存在的文件末尾 hadoop fs -appendToFile /a.txt(本地路径) /b.txt(服务器路径)
-copyFromLocal:从本地拷贝
-copyToLocal:从服务器拷贝
-cat:显示文件内容 hadoop fs -cat /aaa/bbb/hellow.txt
-tail:显示一个文件的末尾 hadoop fs -tail /aaa/bbb/hellow.txt
-text:以字符形式打印一个文件内容 hadoop fs -text /aaa/bbb/hellow.txt
-chmod:更改文件权限 hadoop fs -chmod 666 /aaa/bbb/a.txt
-chown:更改所属组 hadoop fs -chown someuse:someGroup /aaa/bb/a.txt
-cp:从hdfs的一个路径拷贝到hdfs的另一个路径 hadoop fs -cp /aaa/bbb/a.txt /aaa/ccc/c.txt
-mv:hdfs路径上的剪贴
-get:等同于 -copyToLocal
-put:等同于 -copyFromLocal
-rm:删除 hadoop fs -rm -r /aaa/bbb
-df:统计文件系统的可用空间信息 hadoop fs -df -h /
-du:统计文件夹的大小信息 hadoop fs -du /aaa
-count:统计指定目录下文件节点的数量个数 hadoop fs -count /aaa
-setrep:设置hdfs中文件的副本数量 hadoop fs -setrep 3 /aaa/jdk.tar.gz (注意这个命令不是立即执行的)
可以查看官网APIhadoop.apache.org/docs/r2.6.5/
hdfs dfsadmin -report 查看hdfs集群的工作状态、
HDFS写入数据流程
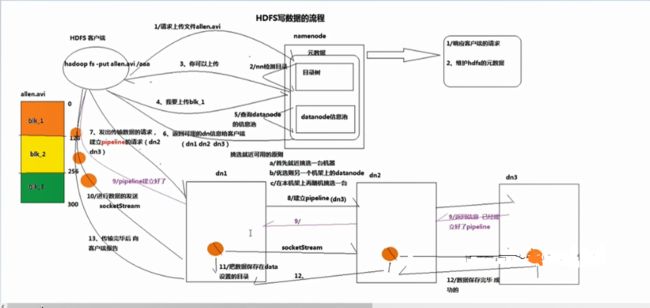
1.HDFS客户端向namdenode请求,namenode会检测目录树中是否存在一样的结构树
2.namenode检测完结构树中是否存在相同的结构树,就会通知HDFS客户端是否可以上传文件
3.可以上传文件就跟namenode通知需要上传文件,
4.HDFS客户端上传文件
5.namenode就会查询datanode信息池中挑选可用的节点以供上传(根据就近原则 a.首先就近挑选一台机器 b.优先选择另一个机架上的namenode c.本机架在挑选一台)
6.服务端返回可用的datanode给HDFS客户端(d1,d2,d3有备份)
7.HDFS客户端向datanode发出数据请求建立pipline的请求
8.datanode1向datanode2,datanode2又向datanode3建立pipline请求。
9.piplien请求建立好通知HDFS客户端。
10,客户端将文件分成每个小包,通过socketStream进行数据传输
11.datanode1创建目录存储数据。
12.然后将备份至datanode2,datanode3
13.通知HDFS客户端一个小包传输完毕,进行下一个小包的传输。
HDFS读取数据
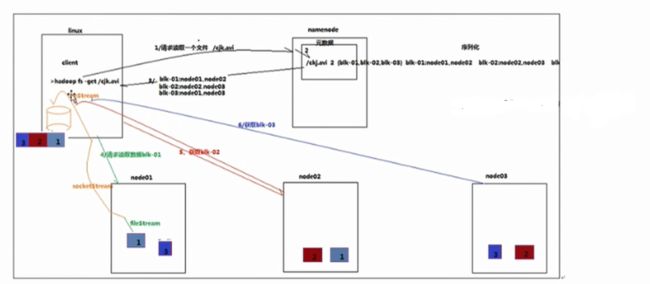
1.与namenode通信查询元数据,找到文件所在的datanode服务。namenode返回文件信息
2.挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3.datanode开始发送数据(从磁盘中读取数据放入流中,以packet为单位来校验)
4.客户端以packet为单位接收,先在本地缓存,然后写入目标文件
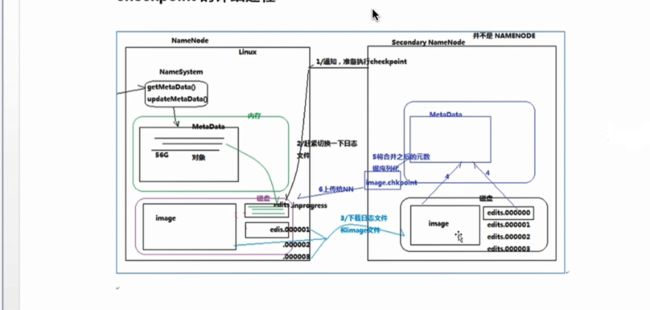
NAMENODE职责
负责客户端的请求与响应
元数据的管理(查询,修改)
元数据的额管理