一、行转列
近期在进行MES项目的开发,遇到了这样的一个问题:
需求页面是这样的:

这是一个显示生产线上设备状态的页面。注意红框框住的几列,这几列是显示设备参数的列,其并不是数据表中的列,而是由用户定义在其他表中的数据行转换而来的。(见下图)。

在数据表中,与其相关的两个表如下所示:
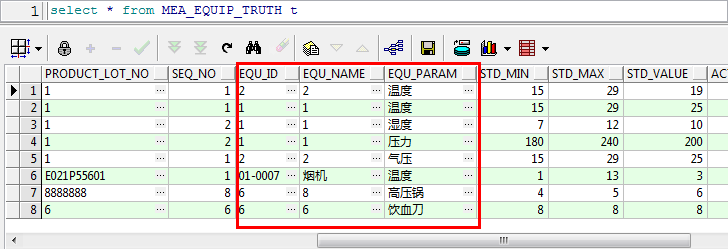
最后查询出来的效果应如下所示:

这里为了避免在传输过程中出现乱码问题,将中文参数,如“温度”,用英文参数"STD_PARAM_1"代替。
所以,这就是一个行转列问题。
解决这个问题需要分两步进行,要写两句SQL。
第一步先用一个Group By 查出参数表中有多少类需要参数。即为需要增加哪些类
"SELECT equ_param FROM MEA_EQUIP_TRUTH GROUP BY equ_param
查询出的结果为'压力'、'湿度'、'气压等'。
接下来需要使用Decode函数进行行转列,
转化SQL如下所示:
SELECT
MAX(M.EQU_ID) EQU_ID,
MAX(M.EQU_NAME) EQU_NAME,
MAX(M.EQU_STATUS) EQU_STATUS,
SUM(DECODE(T.EQU_PARAM, '压力', T.STD_VALUE)) STD_PARAM_1,
SUM(DECODE(T.EQU_PARAM, '压力', T.ACT_VALUE)) ACT_PARAM_1,
SUM(DECODE(T.EQU_PARAM, '湿度', T.STD_VALUE)) STD_PARAM_2,
SUM(DECODE(T.EQU_PARAM, '湿度', T.ACT_VALUE)) ACT_PARAM_2,
SUM(DECODE(T.EQU_PARAM, '气压', T.STD_VALUE)) STD_PARAM_3,
SUM(DECODE(T.EQU_PARAM, '气压', T.ACT_VALUE)) ACT_PARAM_3,
SUM(DECODE(T.EQU_PARAM, '温度', T.STD_VALUE)) STD_PARAM_4,
SUM(DECODE(T.EQU_PARAM, '温度', T.ACT_VALUE)) ACT_PARAM_4
FROM MEA_POSITION_EQUIP M, MEA_EQUIP_TRUTH T
WHERE M.COMPANY_CODE = '00'
AND M.COMPANY_CODE = T.COMPANY_CODE(+)
AND M.LINE_CODE = T.LINE_CODE(+)
AND M.POSITION_CODE = T.POSITION_CODE(+)
AND M.ITEM_CODE = T.ITEM_CODE(+)
AND M.PRODUCT_LOT_NO = T.PRODUCT_LOT_NO(+)
AND M.EQU_ID = T.EQU_ID(+)
GROUP BY M.COMPANY_CODE,
M.LINE_CODE,
M.ITEM_CODE,
M.POSITION_CODE,
M.PRODUCT_LOT_NO,
M.EQU_ID,
M.EQU_NAME
这个SQL中包含如下一些Oracle数据库的用法:
DECODE函数
DECODE 函数是实现行转列功能的关键函数。其为Orcale中的独有函数
SUM(DECODE(T.EQU_PARAM, '压力', T.STD_VALUE)) STD_PARAM_1,
这一行的意思是T表中的参数EQU_PARAM,如果等于'压力',则返回T表中相应行STD_VALUE的值。
其中'压力' 等值,可以在第一句SQL中查出。然后使用循环语句拼成上面的语句。这段循环可以写在SP中,亦写可以在JAVA中。
(+) 左右连接
关于(+)的用法 贴一篇网上的资料,介绍的很详细。
关键是要记住
(+) 哪个表有加号,这个表就是匹配表。如果加号写在右表,左表就是全部显示,所以是左连接。
即右加号为左连接,左加号为右连接
Oracle(+)号用法
二、Oracle 树查询
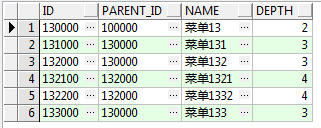
在工程上经常会使用树形结构,例如一级、二级、三级菜单 以及 ,省、市、县等。树形结构的数据会以如下方式存储在Oracle数据库中:

及每个节点有一个存储父节点ID的字段 PARENT_ID 。
像这种类型的存储结构,Oracle有专门的关键字进行查询:
贴一个树查询讲的比较好的博客oracle树形查询 start with connect by
select * from menu start with id='130000' connect by prior id = parent_id ;
对于树查询 关键是 对 关键字 prior 的理解。
prior 条件表示子数据需要满足父数据的什么条件
prior放的左右位置决定了检索是自底向上还是自顶向下. 左边是自上而下(找子节点),右边是自下而上(找父节点)
上面这条SQL的意义为,从ID = 130000 开始,如果有PARENT_ID 等于130000的全部查出来,然后递归。即父节点的ID等于子节点PARENT_ID的所有数据。这样可以查出130000节点下的所有子节点。
三、查出表中所有的列:
一切查出表信息的常用SQL
select column_name from user_tab_cols where table_name='TAB';
1、查找表的所有索引(包括索引名,类型,构成列):
select t.*,i.index_type from user_ind_columns t,user_indexes i where t.index_name = i.index_name and t.table_name = i.table_name and t.table_name = 要查询的表
2、查找表的主键(包括名称,构成列):
select cu.* from user_cons_columns cu, user_constraints au where cu.constraint_name = au.constraint_name and au.constraint_type = 'P' and au.table_name = 要查询的表
3、查找表的唯一性约束(包括名称,构成列):
select column_name from user_cons_columns cu, user_constraints au where cu.constraint_name = au.constraint_name and au.constraint_type = 'U' and au.table_name = 要查询的表
4、查找表的外键(包括名称,引用表的表名和对应的键名,下面是分成多步查询):
select * from user_constraints c where c.constraint_type = 'R' and c.table_name = 要查询的表
查询外键约束的列名:
select * from user_cons_columns cl where cl.constraint_name = 外键名称
查询引用表的键的列名:
select * from user_cons_columns cl where cl.constraint_name = 外键引用表的键名
5、查询表的所有列及其属性
select t.*,c.COMMENTS from user_tab_columns t,user_col_comments c where t.table_name = c.table_name and t.column_name = c.column_name and t.table_name = 要查询的表
6、查询所有表
select* from tabs