掌握了BeatifulSoup的基本用法之后,爬取单个网页实际上是比较简单的:只需要使用requests库中的get方法先向网页发出请求,用BeatifulSoup把网页转成soup,再对soup使用各种select方法,即可得到所需的网页元素,再稍做整理,即可得到所需的结构化内容。
那么,如果要爬取一系列的网页内容呢?
这就需要对爬取过程做一下调度准备了,下面以赶集网二手物品信息为例,介绍一下10万量级网页的爬取过程。
0.爬取目标
选择一个地市的赶集全部二手物品类目作为爬取目标,爬取其下所有二手物品页面、二手物品详细信息。

1.制定爬取过程策略
我们按照倒序来分析一下爬取过程
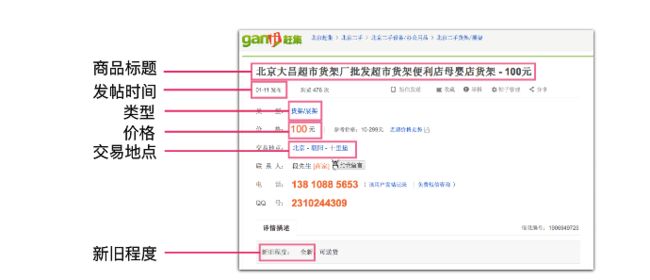
-最后一步:爬取最终的爬取页面,也就是上面的图二(爬取目标),存储所需信息
-倒数第二步:通过类目页面获取最后一步所需的最终页面的链接
-倒数第三步:想办法获取类目页面链接<-- 通过赶集首页-二手栏目,下方的二手物品类目,如上面图一。
我们再把这个过程正过来,也就是正常在赶集上找到对应物品信息的过程——爬取过程就是把这个找寻的过程重复再重复。
当然,上述处理过程中,需要将中间爬取的链接一步一步存储下来、一步一步再提取出来使用,并规避重复。

2.动手开始爬!
过程明确了,实现起来就不复杂了。主要需要注意的是中间存url、取url的过程:注意避免重复——爬过的留一个已爬记录,爬前到这个记录里检查一下有没有,如果已爬,那就跳过!
(1)第一部分代码:获取类目信息
import requests
from bs4 import BeautifulSoup
headers = {
'user-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36'
}
home_url = 'http://xa.ganji.com/wu/'
wb_data = requests.get(home_url,headers = headers)
soup = BeautifulSoup(wb_data.text,'lxml')
#print(soup)
utag = soup.select('dl > dt > a[target="_blank"]')
url_list = ''
for item in utag:
utag_tag = item.get('href')
#print(utag_tag)
url = 'http://xa.ganji.com{}'.format(utag_tag)
url_list = url_list + url + '\n'
print(url)
获取完后,把类目url存储为变量channel_list,备用。
(2)第二部分代码:两个获取页面信息的函数
这一步我们先写获取最终页面链接的函数、再写通过最终链接获取目标信息对应的函数。
函数1的参数有类目链接、子页面编码两个,在调用这个函数的时候,我们再去写对应的编码循环、类目循环。
函数2的参数只有最终页面链接一个。
import pymongo
import requests
from bs4 import BeautifulSoup
import time
from get_ori_url import channel_list,headers
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
#重新建立一个url集
urlset = ganji['urlset']
urlspideset = ganji['urlspideset']
second_info = ganji['second_info']
#step1: get the urls of secondhand
def get_urls(channel,pages):
url_secondhands = '{}o{}'.format(channel,pages)
time.sleep(6)
print(url_secondhands)
db_urls = [item['url'] for item in channel_sec.find()]
if url_secondhands in db_urls:
print('the',url_secondhands,'has spide already!')
pass
else:
wb_data = requests.get(url_secondhands,headers = headers)
soup = BeautifulSoup(wb_data.text,'lxml')
#add the url into have spide
channel_sec.insert_one({'url':url_secondhands})
#add: if page error,then pass
url_secondhand = soup.select('dd.feature > div > ul > li > a')
for item in url_secondhand:
url_s = item.get('href')
urlset.insert_one({'url':url_s})
print(url_s)
# insert the url had spide into a set;
#step2: get the information we need from the secondhand pages
def get_item_info(url):
time.sleep(2)
db_urls = [item['url'] for item in urlspideset.find()]
if url in db_urls:
print('the url "',url,'"has aready spide!')
pass
else:
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
title = soup.select('h1')
pagetime = soup.select('div.col-cont.title-box > div > ul.title-info-l.clearfix > li:nth-of-type(1) > i')
type = soup.select('div.leftBox > div:nth-of-type(3) > div > ul > li:nth-of-type(1) > span > a')
price = soup.select('div > ul > li:nth-of-type(2) > i.f22.fc-orange.f-type')
address = soup.select('div.leftBox > div:nth-of-type(3) > div > ul > li:nth-of-type(3)')
# can't get the pv,need other method
# pageview = soup.select('pageviews')
for t1,p1,type1,price1,add1 in zip(title,pagetime,type,price,address):
data = {
'title':t1.get_text(),
'pagetime':(p1.get_text().replace('发布','')).strip(),
'type':type1.get_text(),
'price':price1.get_text(),
'address':list(add1.stripped_strings)
}
second_info.insert_one(data)
print(data)
urlspideset.insert_one({'url':url})
(3)第三部分代码:调用上述函数获取目标信息
首先是调用函数get_urls,通过类目信息,获取最终页面链接集:
from multiprocessing import Pool
from get_ori_url import channel_list
from spider_ganji import get_urls
def get_url_from_channel(channel):
for num in range(1,71):
get_urls(channel,num)
if __name__ == '__main__':
pool = Pool()
pool.map(get_url_from_channel,channel_list.split())
根据调用的函数,获取的链接会存储在MongoDB下的ganji库urlset表中。
再调用函数 get_item_info,逐个页面获取所需信息:
from multiprocessing import Pool
from spider_ganji import get_item_info
from spider_ganji import urlset
from spider_ganji import urlspideset
#get all urls need to spide:
db_urls = [item['url'] for item in urlset.find()]
#get the urls already spide:
url_has_spide = [item['url'] for item in urlspideset.find()]
x = set(db_urls)
y = set(url_has_spide)
rest_urls = x-y
if __name__ == '__main__':
pool = Pool()
pool.map(get_item_info,rest_urls)
这一步用了一点去除已爬页面的技巧:首先是爬的过程中将已爬取url记录下来(也可以存储在所爬信息库中),如果出现中断,用所有需爬取 剔除 已爬取,即可规避重复爬取问题。
(关于剔重、规避中断过程中出现的问题,应该还有更好的解决方案:先记录异常页面、跳过、继续爬,最后再处理异常页面应该更合适?)
3.总结
大道至简,问题的解决方案应该是简洁的,大规模的数据爬取也是一样:难点并不在于某几个页面怎么爬,而在于过程上的控制和调度:调度过程越清晰,实现起来越容易,实现过程中多翻翻文档就好了(虽然我也觉得文档看起来累,不过确实还得翻,就跟认字时翻字典一样——现在只需要翻“电子词典”已经很方便了!)