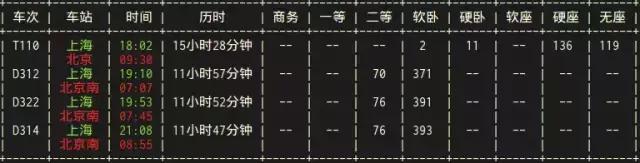
当你想查询一下火车票信息的时候,你还在上12306官网吗?或是打开你手机里的APP?下面让我们来用Python写一个命令行版的火车票查看器, 只要在命令行敲一行命令就能获得你想要的火车票信息!如果你刚掌握了Python基础,这将是个不错的小练习。

配图:火车票
注:想学习Python的小伙伴们进群:984632579领取从0到1完整学习资料 视频 源码 精品书籍 一个月经典笔记和99道练习题及答案
接口设计
一个应用写出来最终是要给人使用的,哪怕只是给你自己使用。所以,首先应该想想你希望怎么使用它?让我们先给这个小应用起个名字吧,既然及查询票务信息,那就叫它tickets好了。我们希望用户只要输入出发站,到达站以及日期就让就能获得想要的信息,所以tickets应该这样被使用:
$ tickets from to date
另外,火车有各种类型,高铁、动车、特快、快速和直达,我们希望可以提供选项只查询特定的一种或几种的火车,所以,我们应该有下面这些选项:
- -g 高铁
- -d 动车
- -t 特快
- -k 快速
- -z 直达
这几个选项应该能被组合使用,所以,最终我们的接口应该是这个样子的:
$ tickets [-gdtkz] from to date
接口已经确定好了,剩下的就是实现它了。
开发环境
写Python程序的一个良好实践是使用virtualenv这个工具建一个虚拟的环境。我们的程序使用Python3开发,下面在你的工作目录下建一个文件夹tickets,进去创建一个虚拟环境:
$ virtualenv -p /usr/bin/python3 venv
通过下面的命令激活它:
$ . venv/bin/activate
解析参数
Python有很多写命令行应用的工具,如argparse, docopt, options...这里,我们选用docopt这个简单易用的工具,我们先安装它:
$ pip3 install docopt
docopt可以按我们在文档字符串中定义的格式来解析参数,在tickets.py中:
# coding: utf-8
"""Train tickets query via command-line.
Usage:
tickets [-gdtkz]
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 南京 北京 2016-07-01
tickets -dg 南京 北京 2016-07-01
"""
from docopt import docopt
def cli():
"""command-line interface"""
arguments = docopt(doc)
print(arguments)
if name == 'main':
cli()
下面我们运行一下这个程序:
$ python3 tickets.py 上海 北京 2016-07-01
我们得到下面的参数解析结果:
{'-d': False, '-g': False, '-k': False, '-t': False, '-z': False, '': '2016-07-01', '': '上海', '': '北京'}
获取数据
参数已经解析好了,下面就是如何获取数据了,这也是最主要的部分。首先我们打开12306,进入余票查询页面,如果你使用chrome,那么按F12打开开发者工具,选中Network一栏,在查询框钟我们输入上海到北京,日期2016-07-01, 点击查询,我们在调试工具发现,查询系统实际上请求了这个URL
https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate=2016-07-01&from_station=SHH&to_station=BJP
并且返回的是JSON格式的数据!接下来问题就简单了,我们只需要构建请求URL然后解析返回的JSON数据就可以了。但是我们发现,URL里面from_station和to_station并不是汉字,而是一个代号,而用户输入的是汉字,我们要如何获取代号呢?我们打开网页源码看看有没有什么发现。
啊哈!果然,我们在网页里面找到了这个链接:点我, 这里面貌似是包含了所有车站的中文名,拼音,简写和代号等信息, 我们在项目目录下将它保存为stations.html。但是这些信息挤在一起,而我们只想要中文名和大写字母的代号信息,怎么办呢?
BINGO!正则表达式,我们写个小脚本来匹配提取出想要的信息吧, 在parse.py中:
# coding: utf-8
import re
from pprint import pprint
with open('stations.html', 'r') as f:
text = f.read()
stations = re.findall(u'([\u4e00-\u9fa5]+)|([A-Z]+)', text)
pprint(dict(stations), indent=4)
我们运行这个脚本,它将以字典的形式返回所有车站和它的大写字母代号, 我们将结果重定向到stations.py中,
$ python3 parse.py > stations.py
我们为这个字典加名字,stations, 最终,stations.py文件是这样的:
stations = {
'一间堡': 'YJT',
'一面坡': 'YPB',
...
'龙镇': 'LZA',
'龙骨甸': 'LGM'
}
现在,用户输入车站的中文名,我们就可以直接从这个字典中获取它的字母代码了:
...
from stations import stations
def cli():
arguments = docopt(doc)
from_staion = stations.get(arguments[''])
to_station = stations.get(arguments[''])
date = arguments[''] 构建URL
url = 'https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate={}&from_station={}&to_station={}'.format(
date, from_staion, to_station
)
万事俱备,下面我们来请求这个URL获取数据吧!这里我们使用requests这个库, 先安装它:
$ pip3 install requests
它提供了非常简单易用的接口,
...
import requests
def cli():
...添加verify=False参数, 不验证证书
r = requests.get(url, verify=False)
print(r.json())
从结果中,我们可以观察到,与车票有关的信息需要进一步提取:
def cli():
...
r = requsets.get(url);
rows = r.json()['data']['datas']
显示结果
数据已经获取到了,剩下的就是提取我们要的信息并将它显示出来。
prettytable这个库可以让我们它像MySQL数据库那样格式化显示数据。
$ pip3 install prettytable
这样使用它:
...
from prettytable import PrettyTable
def cli():
...
headers = '车次 车站 时间 历时 商务 一等 二等 软卧 硬卧 软座 硬座 无座'.split()
pt = PrettyTable()
pt._set_field_names(headers)
for row in rows:从row中根据headers过滤信息, 然后调用pt.add_row()添加到表中
...
print(pt)
练习
下面一些问题留给大家做练习:
从每一行row中按照headers过滤信息,将结果添加到prettytable中
1.像开始的图片中那样将出发站和到达站,出发时间和到达时间显示为一列
2.添加颜色(提示:使用colorama, termcorlor或ANSI转义字符)
3.添加异常处理,如果用户输入的车站或日期有错误怎么办?如果网络异常怎么办?...
4.添加更多的日期格式支持: 比如用户输入20181020也可以查
5.添加参数支持,用户可以指定火车类型