在学习编程的过程中,初学者(特别是想转行互联网的来自其它专业的初学者)往往因为缺乏实际项目的操作而陷入基础学习的环境中无法自拔,在学习Python的过程中,笔者最初也是一直停留在不断地print、列表、数组、各种数据结构的学习里,当然基础知识的学习很重要,但是没有项目的实际操作,往往无法得到提高并会心生厌倦,为了应对这个问题,接下来专栏将从Github开源项目选取一些比较有意思的项目,来为大家说明如何开展项目,如何安装环境,如何debug,如何找到解决问题的方法......
我们以抓取财经新闻的爬虫为例,默认centos系统、Python2.7环境,并且已经安装pyenv,如未安装pyenv请参考:
基于pyenv和virtualenv搭建python多版本虚拟环境
项目作者:
Hailong Zhang
项目地址:
Scrapy Spider for 各种新闻网站
感谢作者开源
1. 首先准备项目开发环境
$cd /home/andy/.pyenv/ENV2.7.10
$ mkdir works
$ cd works
$ pyenv activate ENV2.7.10
$ sudo yum install gcc libffi-devel openssl-devel libxml2 libxslt-devel libxml2-devel python-devel -y
$ sudo yum install python-setuptools
2. 依次安装pip、lxml、scrapy
$ easy_install pip
$ easy_install lxml
$ pip install scrapy
3. 从github克隆项目
$ mkdir spiders
$ git clone https://github.com/hailong0707/spider_news_all
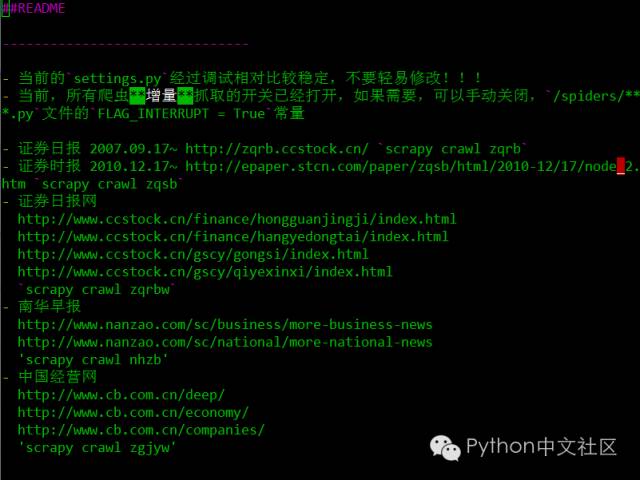
4. 查看README.md项目文档
$ cd spider_news_all
$ ls
$ vim README.md
5. 安装环境及数据库存储连接用的MySQL-python模块
$ sudo yum install python-devel
$ sudo yum install mysql-devel
$ pip install MySQL-python
$ pip install bs4

6. 创建新的与爬虫项目匹配的数据库和配置爬虫项目MySQLdb的连接账号密码
进入MySQL创建存储数据的数据库、表,记得刷新权限:
mysql> create database news;
mysql> grant all privileges on news.* to username@localhost identified by 'passwd';
mysql> flush privileges;
在db.sql的同级目录加载数据库表结构
$ mysql -u root -p
$ source db.sql
配置与数据库对应的爬虫系统的MySQLdb的连接账号密码:
$ vim pipelines.py
$ vim zqrb.py

7. 安装screen,运行项目,以抓取证券日报新闻为例,命名screen名称zqrb
$ sudo yum install screen
$ screen -S zqrb
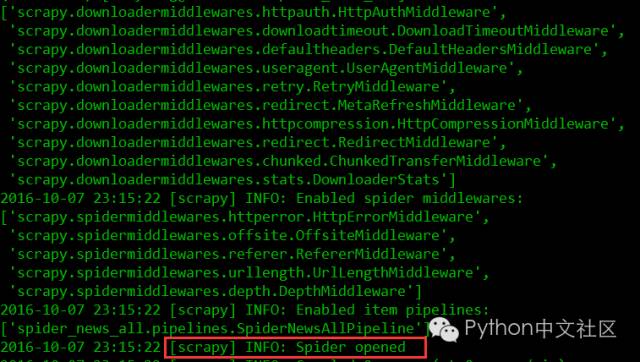
$ scrapy crawl zqrb
8. Debug,直接运行会发现报错,debug完再运行
AttributeError: 'list' object has no attribute 'iteritems'
查看项目的github主页,在Issues里有人已经提出解决方案,修改setting.py
ITEM_PIPELINES = { 'spider_news_all.pipelines.SpiderNewsAllPipeline': 300 }
修改之后再次运行,Great!Ctrl+A+D退出screen返回终端,让爬虫继续运行,Linux中可以利用crontab执行定时任务,比如可以设置每天晚上0点定时开启爬虫抓取。
$ scrapy crawl zqrb
--------------------------
本项目收录各种Python网络爬虫实战开源代码,并长期更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python中文社区
知乎专栏:Python中文社区
Python QQ交流群 :273186166
--------------------------
微信公众号:Python中文社区

Python中文社区 QQ交流群:
--------------------------
Python学习资源下载:
Python开发基础教学视频百度网盘下载地址:http://pan.baidu.com/s/1dEAlfSP
(密码请关注微信公众号“Python中文社区”后回复“视频”二字获取)
Python学习资料PDF电子书大合集百度网盘下载地址:http://pan.baidu.com/s/1bpuqex5
(密码请关注微信公众号“Python中文社区”后回复“资料”二字获取)
Python学习思维脑图大全汇总打包百度网盘下载地址:http://pan.baidu.com/s/1qYH6Tek
(密码请关注微信公众号“Python中文社区”后回复“思维”二字获取)