集合框架
1.常用容器继承关系图
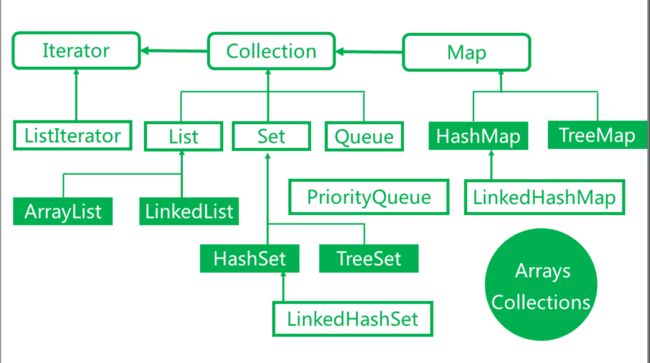
Iterator不是容器,只是一个操作遍历集合的方法
2.Collection和Map
在Java容器中一共定义了2种集合, 顶层接口分别是Collection和Map。但是这2个接口都不能直接被实现使用,分别代表两种不同类型的容器。
Collection:是容器继承关系中的顶层接口。是一组对象元素组。有些容器允许重复元素有的不允许,有些有序有些无序。 JDK不直接提供对于这个接口的实现,但是提供继承与该接口的子接口比如 List Set。
接口定义:
public interface Collection extends Iterable {
...
}
泛型
几个重要的接口方法:
add(E e)确保此 collection 包含指定的元素(可选操作)。
clear()移除此 collection 中的所有元素(可选操作)。
contains(Object o)如果此 collection 包含指定的元素,则返回 true。
isEmpty()如果此 collection 不包含元素,则返回 true。
iterator()返回在此 collection 的元素上进行迭代的迭代器。
remove(Object o)从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。
retainAll(Collection c)仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。
size()返回此 collection 中的元素数
toArray()返回包含此 collection 中所有元素的数组
toArray(T[] a)返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同
Map:一个保存键值映射的对象。 映射Map中不能包含重复的key,每一个key最多对应一个value。
Map集合提供3种遍历访问方法:
1.获得所有key的集合然后通过key访问value。
2.获得value的集合。
3.获得key-value键值对的集合(key-value键值对其实是一个对象,里面分别有key和value)。
Map的访问顺序取决于Map的遍历访问方法的遍历顺序。 有的Map,比如TreeMap可以保证访问顺序,但是有的比如HashMap,无法保证访问顺序。
接口定义如下:
public interface Map {
...
interface Entry {
K getKey();
V getValue();
...
}
}
泛型
几个重要的接口方法:
clear()从此映射中移除所有映射关系
containsKey(Object key)如果此映射包含指定键的映射关系,则返回 true。
containsValue(Object value)如果此映射将一个或多个键映射到指定值,则返回 true。
entrySet()返回此映射中包含的映射关系的 Set 视图。
equals(Object o) 比较指定的对象与此映射是否相等。
get(Object key)返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
isEmpty()如果此映射未包含键-值映射关系,则返回 true。
keySet()返回此映射中包含的键的 Set 视图。
put(K key, V value)将指定的值与此映射中的指定键关联(可选操作)。
putAll(Map m)从指定映射中将所有映射关系复制到此映射中(可选操作)。
remove(Object key)如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
size()返回此映射中的键-值映射关系数。
values()返回此映射中包含的值的 Collection 视图。
3个遍历Map的方法:
1.Set keySet():
会返回所有key的Set集合,因为key不可以重复,所以返回的是Set格式,而不是List格式。
获取到所有key的Set集合后,由于Set是Collection类型的,所以可以通过Iterator去遍历所有的key,然后再通过get方法获取value
如下:
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Set keySet = map.keySet();//先获取map集合的所有键的Set集合
Iterator it = keySet.iterator();//有了Set集合,就可以获取其迭代器。
while(it.hasNext()) {
String key = it.next();
String value = map.get(key);//有了键可以通过map集合的get方法获取其对应的值。
System.out.println("key: "+key+"-->value: "+value);//获得key和value值
}
2.Collection values():
直接获取values的集合,无法再获取到key。所以如果只需要value的场景可以用这个方法。获取到后使用Iterator去遍历所有的value。
如下:
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Collection collection = map.values();//返回值是个值的Collection集合
System.out.println(collection);
3.Set< Map.Entry< K, V>> entrySet():
是将整个Entry对象作为元素返回所有的数据。然后遍历Entry,分别再通过getKey和getValue获取key和value。
如下:
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
//通过entrySet()方法将map集合中的映射关系取出(这个关系就是Map.Entry类型)
Set> entrySet = map.entrySet();
//将关系集合entrySet进行迭代,存放到迭代器中
Iterator> it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = it.next();//获取Map.Entry关系对象me
String key = me.getKey();//通过关系对象获取key
String value = me.getValue();//通过关系对象获取value
}
通过以上3种遍历方式我们可以知道,如果你只想获取key,建议使用keySet。如果只想获取value,建议使用values。如果key value希望遍历,建议使用entrySet。
(虽然通过keySet可以获得key再间接获得value,但是效率没entrySet高,不建议使用这种方法)
3.List、Set和Queue
List和Set。他们2个是继承Collection的子接口,就是说他们也都是负责存储单个元素的容器。
最大的区别如下:
1.List是存储的元素容器是有个有序的可以索引到元素的容器,并且里面的元素可以重复。
2.Set里面和List最大的区别是Set里面的元素对象不可重复。
List:一个有序的Collection(或者叫做序列)。使用这个接口可以精确掌控元素的插入,还可以根据index获取相应位置的元素。
不像Set,list允许重复元素的插入。有人希望自己实现一个list,禁止重复元素,并且在重复元素插入的时候抛出异常,但是我们不建议这么做。
List提供了一种特殊的iterator遍历器,叫做ListIterator。这种遍历器允许遍历时插入,替换,删除,双向访问。 并且还有一个重载方法允许从一个指定位置开始遍历。
List接口新增的接口,会发现add,get这些都多了index参数,说明在原来Collection的基础上,List是一个可以指定索引,有序的容器。
在这注意以下添加的2个新Iteractor方法:
ListIterator listIterator();
ListIterator listIterator(int index);
ListIterator的代码:
public interface ListIterator extends Iterator {
// Query Operations
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
一个集合在遍历过程中进行插入删除操作很容易造成错误,特别是无序队列,是无法在遍历过程中进行这些操作的。
但是List是一个有序集合,所以在这实现了一个ListIteractor,可以在遍历过程中进行元素操作,并且可以双向访问。
List的实现类,ArrayList和LinkedList.
1.ArrayList
ArrayList是一个实现了List接口的可变数组可以插入null它的size, isEmpty, get, set, iterator,add这些方法的时间复杂度是
O(1),如果add n个数据则时间复杂度是O(n).ArrayList不是synchronized的。
然后我们来简单看下ArrayList源码实现。这里只写部分源码分析。
所有元素都是保存在一个Object数组中,然后通过size控制长度。
transient Object[] elementData;
private int size;
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
其实在每次add的时候会判断数据长度,如果不够的话会调用Arrays.copyOf,复制一份更长的数组,并把前面的数据放进去。
我们再看下remove的代码是如何实现的。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
其实就是直接使用System.arraycopy把需要删除index后面的都往前移一位然后再把最后一个去掉。
2.LinkedList
LinkedList是一个链表维护的序列容器。和ArrayList都是序列容器,一个使用数组存储,一个使用链表存储。
数组和链表2种数据结构的对比:
1.查找方面。数组的效率更高,可以直接索引出查找,而链表必须从头查找。
2.插入删除方面。特别是在中间进行插入删除,这时候链表体现出了极大的便利性,只需要在插入或者删除的地方断掉链
然后插入或者移除元素,然后再将前后链重新组装,但是数组必须重新复制一份将所有数据后移或者前移。
3.在内存申请方面,当数组达到初始的申请长度后,需要重新申请一个更大的数组然后把数据迁移过去才行。而链表只需
要动态创建即可。
如上LinkedList和ArrayList的区别也就在此.
总结:
List实现 使用场景 数据结构
ArrayList 数组形式访问List链式集合数据,元素可重复,访问元素较快 数组
LinkedList 链表方式的List链式集合,元素可重复,元素的插入删除较快 双向链表
Vector: 底层是数组数据结构。线程同步。被ArrayList替代了。因为效率低。
4.Set
Set的核心概念就是集合内所有元素不重复。在Set这个子接口中没有在Collection特别实现什么额外的方法,应该只是定义了一个Set概念。下面我们来看Set的几个常用的实现HashSet、LinkedHashSet、TreeSet
HashSet:
HashSet实现了Set接口,基于HashMap进行存储。遍历时不保证顺序,并且不保证下次遍历的顺序和之前一样。HashSet中允许null元素。
进入到HashSet源码中我们发现,所有数据存储在:
private transient HashMap
private static final Object PRESENT = new Object();
意思就是HashSet的集合其实就是HashMap的key的集合,然后HashMap的val默认都是PRESENT。HashMap的定义即是key不重复的集合。使用HashMap实现,这样HashSet就不需要再实现一遍。
所以所有的add,remove等操作其实都是HashMap的add、remove操作。遍历操作其实就是HashMap的keySet的遍历,举例如下
...
public Iterator iterator() {
return map.keySet().iterator();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public void clear() {
map.clear();
}
...
LinkedHashSet:
LinkedHashSet的核心概念相对于HashSet来说就是一个可以保持顺序的Set集合。HashSet是无序的,LinkedHashSet会根据add,remove这些操作的顺序在遍历时返回固定的集合顺序。这个顺序不是元素的大小顺序,而是可以保证2次遍历的顺序是一样的。
类似HashSet基于HashMap的源码实现,LinkedHashSet的数据结构是基于LinkedHashMap。过多的就不说了。
TreeSet:
TreeSet即是一组有次序的集合,如果没有指定排序规则Comparator,则会按照自然排序。(自然排序即e1.compareTo(e2) == 0作为比较)
注意:TreeSet内的元素必须实现Comparable接口。
TreeSet源码的算法即基于TreeMap,具体算法在说明TreeMap的时候进行解释。
总结:
Set实现 使用场景 数据结构
HashSet 无序的、无重复的数据集合 基于HashMap
LinkedSet 维护次序的HashSet 基于LinkedHashMap
TreeSet 保持元素大小次序的集合,元素需要实现Comparable接口 基于TreeMap
4.HashMap、LinkedHashMap、TreeMap和WeakHashMap
HashMap就是最基础最常用的一种Map,它无序,以散列表的方式进行存储。之前提到过,HashSet就是基于HashMap,只使用了HashMap的key作为单个元素存储。
HashMap的访问方式就是继承于Map的最基础的3种方式,详细见上。在这里我具体分析一下HashMap的底层数据结构的实现。
在看HashMap源码前,先理解一下他的存储方式-散列表(哈希表)。像之前提到过的用数组存储,用链表存储。哈希表是使用数组和链表的组合的方式进行存储。(具体哈希表的概念自行搜索)如下图就是HashMap采用的存储方法。
Map实现 使用场景 数据结构
HashMap 哈希表存储键值对,key不重复,无序 哈希散列表
LinkedHashMap 是一个可以记录插入顺序和访问顺序的HashMap 存储方式是哈希散列表,但是维护了头尾指针用来记录顺序
TreeMap 具有元素排序功能 红黑树
WeakHashMap 弱键映射,映射之外无引用的键,可以被垃圾回收 哈希散列表
详细:http://www.jianshu.com/p/047e33fdefd2