用久了,就发现过于简单了,无法全文检索,文章也没有目录导航,但是有很多鸡汤。
本文语雀对应地址
用 Java 编写一个多线程爬虫,完成 HTTP 请求、模拟登录、Cookie 保存、HTML 解析的工作。在获得数据之后,会将它存入数据库中,并使用 Flyway 从 H2 迁移到 MySQL。当数据增长到一定规模之后,再使用 Elasticsearch 处理和分析数据,并完成一个简单的搜索引擎。
涉及技术:Java/HTTP/JSON/HTML/Cookie/jsoup/IDEA/Flyway/MySQL/Elasticsearch
GitHub 项目地址
1. 从零开始做一个项目的原则
待完善...
2. 初始化项目与项目设计流程
GitHub 上开一个新仓库,可以勾选预设的 Java .gitignore 配置、开源协议及 README.md。
初始化:
- mvn archetype
- IDEA -new
- 借鉴
3. Maven 生命周期与使用
官方文档地址
3.1 Build Lifecycle 基础
Maven 基于构建生命周期这一核心概念,有三个内置的 build lifecycles:default,clean 和 site。
build lifecycle 由 不同的 build phase 组成,一个 build phase 对应着 build lifecycle 的一个阶段, 其会依次执行。
build phase 由不同的 plugin goal 组成,通过声明 plugin goal 与 build phase 的绑定来具体的实现在生命周期执行中一些特定任务。
一个插件目标可以绑定到 0 或多个构建阶段上,如果不绑定到任何构建阶段上,也可以在生命周期之外单独调用执行;如果绑定到多个构建阶段上,那该插件目标会分别在这些阶段中被执行。
更进一步,一个构建阶段可以和 0 或多个插件目标相绑定,如果没和任何插件目标相绑定,则该构建阶段将不会被执行,但如果和多个目标相绑定,则会执行所有这些目标。
具体执行顺序的例子如下:
mvn clean dependency:copy-dependencies package
clean 和 package 参数是构建阶段,而 dependency:copy-dependencies 是 dependency 插件的一个目标。
所以运行时的顺序是:
先执行 clean lifecycle 的 clean 及 clean 之前的阶段,然后执行 dependency:copy-dependencies ,最后执行 default lifecycle 的 package 及 package 之前的阶段。
以带有连字符单词命名( pre-* 、 post-* 、 process-* )的构建阶段通常并不直接从命令行中调用,而是在构建过程中内部调用,用于生成对外部来说没什么可用性的中间结果。
3.2 使用
在内建的生命周期中,有些构建阶段会和某些内置插件目标进行默认的绑定,具体有哪些绑定,取决于 jar )。
所以使用方法一是设置
二是在 pom.xml 文件中进行插件配置,一个插件可能会有多个目标,可以分别指定目标和想要绑定的阶段。
4. 使用 H2 数据库实现数据存储与断点续传
4.1 数据库表设计
LINKS_TO_BE_PROCESSED
link
LINKS_ALREADY_PROCESSED
link
NEWS
id
title
content
url
created_at
updated_at
5. 使用 Flyway 数据库自动化迁移工具(v0.1)
数据库解构的版本管理工具,实现新建和数据迁移自动化。
照着官网引入 maven,并且安装约定的目录结构和文件命名写好 SQL 语句:

pom.xml 文件中引入插件,命令行中运行 mvn flyway:migrate 实现一键创建并初始化数据库:
org.flywaydb
flyway-maven-plugin
6.0.8
jdbc:h2:file:${project.basedir}/news
root
root
还可以在 pom.xml 中将 flyway:migrate 这一插件目标绑定到 Maven 的 initialize 阶段,从而在 mvn initialize 的时候自动触发 Flyway 插件:
org.flywaydb
flyway-maven-plugin
6.0.8
test-database-setup
initialize
migrate
jdbc:h2:file:${project.basedir}/news
root
root
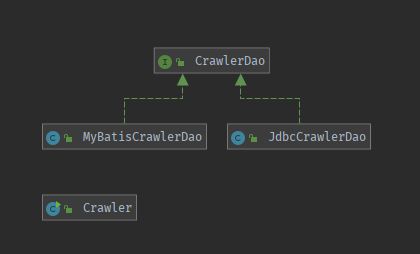
6. 将数据库操作抽取成为 DAO(Data Access Object) 接口
// ...
public class Crawler {
private CrawlerDao dao = new JdbcCrawlerDao();
public static void main(String[] args) throws SQL Exception {
new Crawler().run();
}
private void run() throws SQLException {
String link;
while ((link = dao.getNextLinkThenDelete()) != null) {
if (!dao.isLinkProcessed(link)) {
System.out.println(link);
Document doc = httpGetAndParseHtml(link);
parseUrlsFromPageAndStoreIntoDatabase(doc);
storeIntoDatabaseIfItIsNewsPage(doc, link);
dao.updateLinkIntoDatabase(link, "insert into LINKS_ALREADY_PROCESSED (link) values (?)");
}
}
}
// ...
}
7. ORM(Object Relational Map) 初步(v0.2)
引入 MyBatis,基本跟着官网参照例子就能使用。
pom.xml :
org.mybatis
mybatis
3.5.3
config.xml :
MyMapper.xml :
delete
from LINKS_TO_BE_PROCESSED
where link = #{link}
insert into NEWS (title, content, url, created_at, updated_at)
values (#{title}, #{content}, #{url}, now(), now())
insert into
LINKS_ALREADY_PROCESSED
LINKS_TO_BE_PROCESSED
(link)
values (#{link})
8. 切换到 Docker 和 MySQL(v0.3)
使用 mysql:5.7.28 镜像创建容器并运行,同时分别对数据存储目录和端口做了映射,以实现数据持久化及与外界进行交互:
docker run --name mysql -v ~/Projects/data/mysql-5.7.28:/var/lib/mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7.28
然后就可以使用诸如 SQuirreL SQL Client(小松鼠)数据库管理工具进行连接,该管理工具是一个基于 Java 的程序,所以进行连接时需要配置相应数据库管理系统(MySQL、Postgres、H2 等 )的 JDBC 驱动。此外也可以使用 IntelliJ IDEA 旗舰版自带的 Database 工具进行连接。
MySQL JDBC 连接 url 格式是 jdbc:mysql://localhost:3306 ,默认用户名 root ,密码为刚才启动容器时设置的 root 。
然后创建数据库 news 并且指定字符编码格式:
create database news default character set utf8mb4 collate utf8mb4_unicode_ci;
use news;
# show databases; 可以确认一下是否创建成功
以上创建了数据库,虽然涉及到了 JDBC,但也只是因为本次选择了用 Java 编写出来的数据库管理工具来连接数据库,所以也可以完全使用其他支持 MySQL 的相关管理工具。但是接下来,由于本次爬虫项目就是 Java 写的,所以必须要做一些简单的 JDBC 驱动配置相关的工作。
pom.xml 依赖项中添加 MySQL 相关的 JDBC 驱动,并将 Flyway 的连接 url 更改为 MySQL 格式:
...
mysql
mysql-connector-java
8.0.18
...
org.flywaydb
flyway-maven-plugin
6.0.8
jdbc:mysql://localhost:3306/news?characterEncoding=utf-8
root
root
...
此时可以命令行中运行 mvn flyway:migrate 来重建之前的数据库结构,实现从 H2 迁移到 MySQL,但要注意这里 MySQL 安装完后是默认:区分表名的大小写,不区分列名的大小写,所以应保证代码中涉及到表名的地方要大小写统一。
项目此前引入了 MyBatis,现在又从 H2 迁移到 MySQL,所以 MyBatis 的配置文件 config.xml 也要更改为对应的驱动类名、url 地址、用户名和密码:
注意 MySQL 字符集问题,在 URL 连接地址中也要在参数中指定 utf-8,从而避免提交的字符出现乱码。
**
9. 改造成多线程提高速度
数据库操作本身就能保证原子性,是线程安全的,所以改造非常简单,先令爬虫主逻辑类 Crawler 继承自 Thread 类,并覆盖 run() 方法:
public class Crawler extends Thread {
private CrawlerDao dao;
public Crawler(CrawlerDao dao) {
this.dao = dao;
}
@Override
public void run() {
try {
String link;
while ((link = dao.getNextLinkThenDelete()) != null) {
if (!dao.isLinkProcessed(link)) {
System.out.println(link);
Document doc = httpGetAndParseHtml(link);
parseUrlsFromPageAndStoreIntoDatabase(doc);
storeIntoDatabaseIfItIsNewsPage(doc, link);
dao.insertProcessedLink(link);
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// ...
}
然后注意 DAO 中有个方法进行了两次数据库操作,这里需要保证原子性,最简单的办法就是将该方法声明为 synchronized :
@Override
public synchronized String getNextLinkThenDelete() throws SQLException {
try (SqlSession session = sqlSessionFactory.openSession()) {
String link = session.selectOne("com.github.wangpeng1994.MyMapper.selectNextAvailableLink");
if (link != null) {
deleteProcessedLink(link);
}
return link;
}
}
然后同时创建多个爬虫线程,并通过构造函数传入同一个 DAO:
package com.github.wangpeng1994;
public class Main {
public static void main(String[] args) {
CrawlerDao dao = new MyBatisCrawlerDao();
for (int i = 0; i < 4; i++) {
new Crawler(dao).start();
}
}
}
10. MySQL百万数据与索引优化实战(v0.4)
10.1 mock 数据
现在面临的问题是如何获得百万数据,毕竟现在写的爬虫实测爬取新浪新闻只能得到 1000 多条。所以现在可以根据这些原始数据 mock 出剩余的数据。
所以进一步完善了 News 类,补充了以下两个字段,之前是插入数据时,使用 SQL 中的 now() 生成,但现在 mock 假数据时,当然是短时间内批量生成,所以后面需要在 Java 中进行修改:
private Instant createdAt;
private Instant updatedAt;
MockMapper.xml :
insert into NEWS (title, content, url, created_at, updated_at)
values (#{title}, #{content}, #{url}, #{createdAt}, #{updatedAt})
注意 Java 变量命名规范是驼峰式,而 SQL 中字段名是下划线分割,所以还需要配置 MyBatis 启用自动转换,同时引入另一个 Mapper, config.xml :
然后请参考源码中用于 mock 数据的 MockDataGenerator 工具类。
10.2 清理数据并创建索引
先处理一下数据,将日期中的时分秒抹零为 2019-11-11 00:00:00 的格式,方便后续查询时加快对比:
update NEWS set created_at = date(created_at), updated_at = date(updated_at);
然后尝试根据没有索引的字段查询(用时 12s):
select * from NEWS where created_at = '2019-11-11';
MySQL 中为字段创建索引(用时 14s),并查看已创建的索引:
create index created_at_index on NEWS (created_at);
show index from NEWS;
再次使用同样语句查询,有了索引后,速度大幅提升!用时 0.06s。再一次使用同样语句查询,用时 0.01s 更快了!因为数据库缓存生效了。
10.3 EXPLAIN 优化查询检测
EXPLAIN 可以帮助开发人员分析 SQL 问题, explain 显示了 mysql 如何使用索引来处理 select 语句以及连接表,可以帮助选择更好的索引,写出更优化的查询语句。
使用方法,在 select 语句前加上 explain 就好了:
explain select * from NEWS where created_at = '2018-11-27';
可以看到 type 为 ref,ref 在 type 中优先级很高。
type: range -- 区间索引(在小于1990/2/2区间的数据),这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,const代表一次就命中,ALL代表扫描了全表才确定结果。一般来说,得保证查询至少达到range级别,最好能达到ref。
如果根据没有建立索引的字段来查询,可以看到返回结果中 type 是 ALL,这是最坏的结果,最坏情况下,可能扫描到第100万条记录时才匹配到:
explain select * from NEWS where updated_at = '2018-11-27';
10.4 联合索引和最左匹配原则
先删除前面创建的单个索引,以免对接下来的演示造成干扰:
drop index created_at_index on NEWS;
接下来创建用多个字段组成的联合索引 craeted_at + updated_at :
create index created_at_updated_at_index on NEWS (created_at, updated_at);
再次查看索引,会发现分别创建了两个索引,对于经常用 a 条件或者 a + b 条件去查询会有帮助,而如果也经常单独使用 b 条件去查询,则建立两个单列索引会更好。
在Mysql建立多列索引(联合索引)有最左前缀的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
如果我们建立了一个2列的联合索引(col1,col2),实际上已经建立了两个联合索引(col1)、(col1,col2);
如果有一个3列索引(col1,col2,col3),实际上已经建立了三个联合索引(col1)、(col1,col2)、(col1,col2,col3)。
然后测试以下查询条件:
select * from NEWS where created_at = '2017-12-27' and updated_at < '2019-05-01'
发现非常快,0.02s,根据最左匹配原则, created_at = '2019-11-27' 有索引。
对上面的语句 explain 一下,会发现 type 是 range,因为在联合索引中范围以后的索引会导致索引失效,但 range 也比 ALL 要好。
颠倒一下刚才的查询语句条件:
explain select * from NEWS where created_at < '2017-12-27' and updated_at = '2019-05-01'
根据最左匹配原则, created_at < '2017-12-27' 没有可以应用的索引,所以 type 是 ALL。
索引并不是越多越好,否则更改、插入和删除数据时,也要涉及索引的更新,所以是越符合高频的查询需求越好。
参考 MySQL 索引优化全攻略 | 菜鸟教程
11. Elasticsearch 原理与数据索引实战(v1.0)
mysql 长处对于非文本的数据比如文本中的局部字符串,没能有很好的支持:
select * from NEWS where content like '%乔碧萝%';
所以接下来使用 Elasticsearch 对亿级数据进行搜索。
传统 B+ 树是判断相等,而全文搜索的需求是判断是否包含关键字,Elasticsearch 使用了倒排索引的存储方式,它适用于快速的全文搜索,一个倒排索引由文档中所有不重复词的列表构成。
举个简单的例子,如果让你尝试背诵出李白的《静夜思》一定能够轻松背出,但是假如一开始是尝试背诵出带有“月”字的诗句,那可能就要思考一会了,即使成功背出了《静夜思 》,那如果再让背诵另一首带有“月”字的诗句呢?
倒排索引就相当于为每个关键字都记录了一份古诗词表:
月 --> 《静夜思》、《枫桥夜泊》
雨 -->《长恨歌》、《渭城曲》
...
使用 docker 安装运行 elasticsearch,git bash 有坑,下面这句 windows 中最好别用 git bash 运行,用cmd/powershell 等:
docker run -d --name crawler-elasticsearch -v elasticsearch-data:/usr/share/elasticsearch/data -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.4.2
ES 的 REST API 中数据读写操作都是通过 json 来完成的,现在访问 localhost:9200 能看到返回的 json 数据,表明成功启动了 ES:
{
"name": "b861a828684b",
"cluster_name": "docker-cluster",
"cluster_uuid": "SlFqgDTTSdu8XvdqkuS1Uw",
"version": {
"number": "7.4.2",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date": "2019-10-28T20:40:44.881551Z",
"build_snapshot": false,
"lucene_version": "8.2.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
接下来为了感受 ES 全文搜索对比 MySQL 数据库的速度,本次插入 1000 万条数据到 ES 中,为数据建立索引是个 IO 密集型的操作,所以使用了 多线程,但不断地进行网络请求依然有些慢,所以进一步使用 ES 的批处理操作 Bulk API,在一个 API 调用中执行多个索引或删除操作。这减少了开销,并可以极大地提高索引速度。
然后调用以下接口查看目前数据总量:
http://localhost:9200/_count
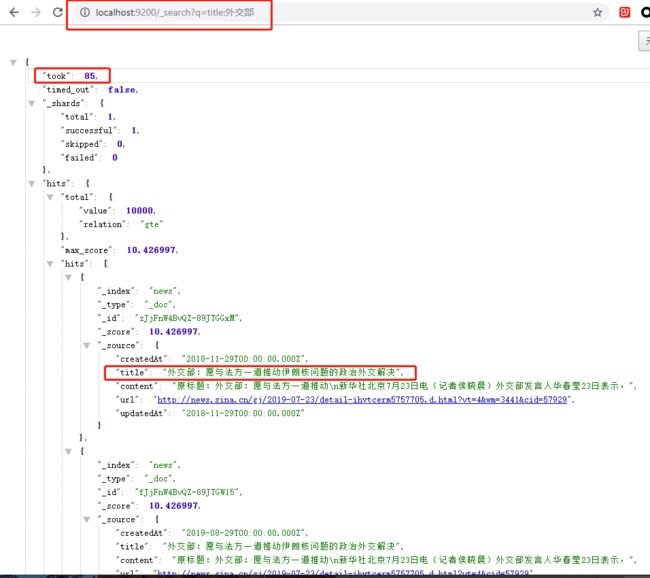
插入了 1000 万数据到 ES 集群中后,查询速度依旧飞起,第二次查询还会有缓存机制,用时只有几十毫秒。可以调用以下接口进行查询,关键字会被分词,返回的数据会根据命中率分数由高到低排序,所以数据未必是100%匹配,这和日常的搜索引擎类似:
http://localhost:9200/_search?q=title:外交部
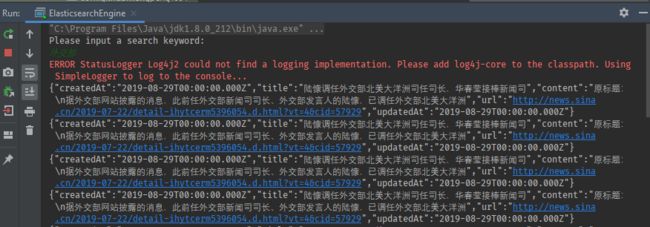
最后,使用了 ES 的 Search API 写一个简单的命令行搜索引擎:
GitHub 项目地址