首先简单介绍GPGPU programming
和CPU Random Memory Accesses(随机内存获取)不同,GPU是用平行架构处理 大量的并行数据,例如vertex和fragment就是分开计算的。使用GPU并利用这种特性来进行非图形计算被称为GPGPU编程(General Purpose GPU Programming)。大量并行无序数据的少分支逻辑(少if)适合GPGPU,例如粒子间互不影响的粒子系统。GPGPU平台或接口有DirectCompute,OpenCL,CUDA等。
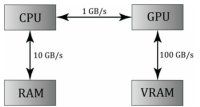
从此图可以看出 CPU和GPU之间的数据传输是瓶颈。故当使用GPGPU时,对Texture的逐像素处理不需要传回CPU,因而速度比较快。
Compute Shader
Compute Shader下文简称cs
【概念】
Compute Shaders是在GPU运行却又在普通渲染管线之外的程序。用于运行GPGPU program。
平行算法被拆分成很多线程组,而线程组包含很多线程。例如一个线程处理一个像素点。而一定要注意这种处理是无序的随机的,并不一定是固定的处理顺序,例如不一定是从左到右挨个处理像素点。
线程组
A Thread Group 运行在一个GPU单元 (A single multiprocesser),如果GPU有16个
multiprocesser,那么程序至少要分成16个 Thread Group使得每个multiprocesser都参与计算。
组之间不分享内存。
线程
一个线程组包含n个线程,每32个thread称为一个warp(nvidia:warp=32 ,ati:wavefront=64,因此未来此数字可能会更高)。从效率考虑,一个线程组包含的线程数最好的warp的倍数,256是一个比较合适的数字。
【实现步骤】
(1)在compute shader里 通过对贴图或者buffer进行数据读写
(2)在cs脚本里设置shader的贴图或者buffer并运行
【规则语法】1 Compute Shaders的文件后缀为.compute
2 使用#pragma指出内核。
一个Compute Shader至少需要一个内核。
例如#pragma kernel FillWithRed
也可以接宏定义
#pragma kernel KernelOne SOME_DEFINE DEFINE_WITH_VALUE=1337 #pragma kernel KernelTwo OTHER_DEFINE
3 函数语法
下面通过一个完整简单的ComputeShader演示
#pragma kernel FillWithRed
RWTexture2D< float4 > res;
[numthreads(1,1,1)]
void FillWithRed (uint3 id : SV_DispatchThreadID)
{
res[id.xy] = float4(1,0,0,1);
}
这一段代码只是输出红色至res贴图.
一 前缀
在核的前缀用三个纬度,定义了一个线程组内线程的数量,如果只用2个纬度那么,最后一个参数为1即可
[numthreads(thread_group_size_x,thread_group_size_y,1)]
GroupID:线程组id
ThreadIID:组内线程idDispatchThreadID:线程DispatchId(DispatchThreadID=GroupID*组内线程数 +ThreadId)
这些id都是从0开始二 资源类型
cs可以读取两种类型的资源:buffer ,texture
【buffer】
例如顶点缓冲就是一种buffer,很多时候我们去定义struct数组并作为buffer传入cs
自己定义buffer(必须是固定size):
struct Data
{
float x;
};
StructuredBuffer< Data > b;
RWStructuredBuffer< Data > b;
buffer的添加是append,消耗是consume
texture:
只读 Texture2d< float4 > xx;
读写 RWTexture2d< float4 > xx;RWTexture2d< float2 > xx;//RG_int在Unity里读写的只能是RenderTexture并且支持随机读写(RenderTextureenableRandomWrite=true)
三 其他
1 每个线程都有一个对应的id:SV_DispatchThreadID
对贴图进行采样不能用Sample 而是SampleLevel,额外的参数是mipmap level ,0为最高级,1为次级,2...
2 int格子转换至[0,1]uv范围
例如一张512x512的贴图
Texture2d tex;
tex.SampleLevel(samPoint,float2(id.x,id.y)/512)
blur需要所有所有像素都sample完,因此需要同步:
GroupMemoryBarrierWithGroupSync();[例一:基本贴图计算]

将一张贴图所有像素点赋予红色,很简单。
CS脚本
usingUnityEngine;
usingSystem.Collections;
publicclassSetTexColor_1:MonoBehaviour{
publicMaterialmat;
publicComputeShadershader;
voidStart()
{
RunShader();
}
voidRunShader()
{
////////////////////////////////////////
//RenderTexture
////////////////////////////////////////
//1新建RenderTexture
RenderTexturetex=newRenderTexture(256,256,24);
//2开启随机写入
tex.enableRandomWrite=true;
//3创建RenderTexture
tex.Create();
//4赋予材质
mat.mainTexture=tex;
////////////////////////////////////////
//ComputeShader
////////////////////////////////////////
//1找到computeshader中所要使用的KernelID
intk=shader.FindKernel("CSMain");
//2设置贴图参数1=kid参数2=shader中对应的buffer名参数3=对应的texture,如果要写入贴图,贴图必须是RenderTexture并enableRandomWrite
shader.SetTexture(k,"Result",tex);
//3运行shader参数1=kid参数2=线程组在x维度的数量参数3=线程组在y维度的数量参数4=线程组在z维度的数量
shader.Dispatch(k,256/8,256/8,1);
}
}
Compute Shader
//1定义kernel的名称
#pragmakernelCSMain
//2定义buffer
RWTexture2DResult;
//3kernel函数
//组内三维线程数
[numthreads(8,8,1)]
voidCSMain(uint3id:SV_DispatchThreadID)
{
//给buffer赋值
//纯红色
//Result[id.xy]=float4(1,0,0,1);
//基于uv的x给颜色
floatv=id.x/256.0f;
Result[id.xy]=float4(v,0,0,1);
}
[例二:Buffer使用]

这个例子并不是讲实现粒子系统,而只是演示简单的Buffer使用和传递。
步骤:
shader:
1 定义struct结构体
2 声明struct变量
3 函数里计算
c#:
1 定义对应的struct结构体
2声明struct数组3创建bufferComputeBufferbuffer=newComputeBuffer(count,40);
参数1是 数组长度(等于2个三维的乘积),参数2是结构体的字节长度如float=4
4 初始化结构体并赋予buffer
buffer.SetData(values);
参数是struct数组
5 Dispatch
还是FindKernel->SetBuffer->Dispatch
Compute Shader
#pragmakernelCSMain
structPBuffer
{
floatlife;
float3pos;
float3scale;
float3eulerAngle;
};
RWStructuredBufferbuffer;
floatdeltaTime;
[numthreads(2,2,1)]
voidCSMain(uint3id:SV_DispatchThreadID)
{
intindex=id.x+id.y*2*2;
buffer[index].life-=deltaTime;
buffer[index].pos=buffer[index].pos+float3(0,deltaTime,0);
buffer[index].scale=buffer[index].scale;
buffer[index].eulerAngle=buffer[index].eulerAngle+float3(0,20*deltaTime,0);
}
CS脚本
usingUnityEngine;
usingSystem.Collections;
usingSystem.Collections.Generic;
//Buffer数据结构
structPBuffer
{
//size40
publicfloatlife;//4
publicVector3pos;//4x3
publicVector3scale;//4x3
publicVector3eulerAngle;//4x3
};
publicclassParticles_2:MonoBehaviour{
publicComputeShadershader;
publicGameObjectprefab;
privateList
intcount=16;
privateComputeBufferbuffer;
voidStart()
{
for(inti=0;i GameObjectobj=Instantiate(prefab)asGameObject; pool.Add(obj); } CreateBuffer(); } voidCreateBuffer() { buffer=newComputeBuffer(count,40); PBuffer[]values=newPBuffer[count]; for(inti=0;i PBufferm=newPBuffer(); InitStruct(refm); values[i]=m; } buffer.SetData(values); } voidInitStruct(refPBufferm) { m.life=Random.Range(1f,3f); m.pos=Random.insideUnitSphere*5f; m.scale=Vector3.one*Random.Range(0.3f,1f); m.eulerAngle=newVector3(0,Random.Range(0f,180f),0); } voidUpdate() { //运行Shader Dispatch(); //根据Shader返回的buffer数据更新物体信息 PBuffer[]values=newPBuffer[count]; buffer.GetData(values); boolreborn=false; for(inti=0;i if(values[i].life<0){ InitStruct(refvalues[i]); reborn=true; }else{ pool[i].transform.position=values[i].pos; pool[i].transform.localScale=values[i].scale; pool[i].transform.eulerAngles=values[i].eulerAngle; //pool[i].GetComponent } } if(reborn) buffer.SetData(values); } voidDispatch() { shader.SetFloat("deltaTime",Time.deltaTime); intkid=shader.FindKernel("CSMain"); shader.SetBuffer(kid,"buffer",buffer); shader.Dispatch(kid,2,2,1); } voidReleaseBuffer() { buffer.Release(); } privatevoidOnDisable() { ReleaseBuffer(); } }