错误1:
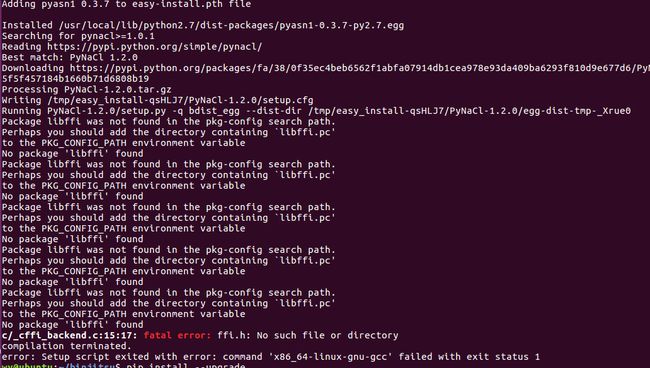
解决方案:
网站:http://blog.csdn.net/u010049282/article/details/52916668
解决方法:
执行命令sudo apt-get install libffi-dev
错误2:
解决方案:
找到并且杀掉所有的apt-get 和apt进程
运行下面的命令来生成所有含有 apt 的进程列表,你可以使用ps和grep命令并用管道组合来得到含有apt或者apt-get的进程。
ps -A | grep apt
找出所有的 apt 以及 apt-get 进程
$ sudo kill -9 processnumber
或者
$ sudo kill -SIGKILL processnumber
比如,下面命令中的9是 SIGKILL 的信号数,它会杀掉第一个 apt 进程
$ sudo kill -9 进程ID
或者
$ sudo kill -SIGKILL 进程ID
错误3:
解决办法:
ubuntu下缺少了部分如下的组件,安装一下即可
sudo apt-get install libssl-dev
But in CentOS the package is named "openssl-devel". So try:
yum install openssl-devel
成功:
####################################################
相关知识点:
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
Python 字典(Dictionary) items()方法
描述
Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。
语法
items()方法语法:
dict.items()
Python enumerate() 函数
描述
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
语法
以下是 enumerate() 方法的语法:
enumerate(sequence, [start=0])
参数
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置。
返回值
返回 enumerate(枚举) 对象。
实例
以下展示了使用 enumerate() 方法的实例:
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 小标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
普通的 for 循环
>>>i = 0
>>> seq = ['one', 'two', 'three']
>>> for element in seq:
... print i, seq[i]
... i +=1
...
0 one
1 two
2 three
for 循环使用 enumerate
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, seq[i]
...
0 one
1 two
2 three
>>>
Python Tuple(元组) tuple()方法
描述
Python 元组 tuple() 函数将列表转换为元组。
语法
tuple()方法语法:
tuple( seq )
参数
seq -- 要转换为元组的序列。
返回值
返回元组。
实例
以下实例展示了 tuple()函数的使用方法:
实例 1
>>>tuple([1,2,3,4])
(1, 2, 3, 4)
>>> tuple({1:2,3:4}) #针对字典 会返回字典的key组成的tuple
(1, 3)
>>> tuple((1,2,3,4)) #元组会返回元组自身
(1, 2, 3, 4)
- append() 方法向列表的尾部添加一个新的元素。只接受一个参数。
- extend()方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中。
Python isinstance() 函数
描述
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
语法
isinstance(object, classinfo)
参数
object -- 实例对象。
classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组。
返回值
如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
实例
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
type() 与 isinstance()区别:
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False
Python 字典(Dictionary) get()方法
描述
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
语法
get()方法语法:
dict.get(key, default=None)
参数
key -- 字典中要查找的键。
default -- 如果指定键的值不存在时,返回该默认值值。
返回值
返回指定键的值,如果值不在字典中返回默认值None。
实例
以下实例展示了 get()函数的使用方法:
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 27}
print "Value : %s" % dict.get('Age')
print "Value : %s" % dict.get('Sex', "Never")
以上实例输出结果为:
Value : 27
Value : Never
repr() 函数
描述
repr() 函数将对象转化为供解释器读取的形式。
语法
以下是 repr() 方法的语法:
repr(object)
参数
object -- 对象。
返回值
返回一个对象的 string 格式。
实例
以下展示了使用 repr() 方法的实例:
>>>s = 'RUNOOB'
>>> repr(s)
"'RUNOOB'"
>>> dict = {'runoob': 'runoob.com', 'google': 'google.com'};
>>> repr(dict)
"{'google': 'google.com', 'runoob': 'runoob.com'}"
>>>
zip函数
zip()函数的作用就是在多个等长的序列中,每次循环都从每个序列分别取出一个元素,之后进行元素的聚合。举例如下:
s1 = [1,2,3]
s1 = [4,5,6]
s3 = [7,8,9]
for (a,b,c) in zip(s1, s2, s3)
print (a,b,c)
输出结果为:
(1,4,7)
(2,5,8)
(3,6,9)
说明:每次循环时,zip()函数从每个序列分别从左到右取出一个元素,合并所有元素构成一个tuple并将tuple元素赋值给a, b, c。
Python strip()方法
描述
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法
strip()方法语法:
str.strip([chars]);
参数
chars -- 移除字符串头尾指定的字符序列。
返回值
返回移除字符串头尾指定的字符生成的新字符串。
实例
以下实例展示了strip()函数的使用方法:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = "00000003210Runoob01230000000";
print str.strip( '0' ); # 去除首尾字符 0
str2 = " Runoob "; # 去除首尾空格
print str2.strip();
以上实例输出结果如下:
3210Runoob0123
Runoob
With语句是什么?
有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。
如果不用with语句,代码如下:
file = open("/tmp/foo.txt")
data = file.read()
file.close()
这里有两个问题:
一是可能忘记关闭文件句柄;
二是文件读取数据发生异常,没有进行任何处理。
下面是处理异常的加强版本:
try:
f = open('xxx')
except:
print 'fail to open'
exit(-1)
try:
do something
except:
do something
finally:
f.close()
虽然这段代码运行良好,但是太冗长了。
这时候就是with一展身手的时候了。除了有更优雅的语法,with还可以很好的处理上下文环境产生的异常。
下面是with版本的代码:
with open("/tmp/foo.txt") as file:
data = file.read()
map()函数
描述
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法
map() 函数语法:
map(function, iterable, ...)
参数
function -- 函数,有两个参数
iterable -- 一个或多个序列
返回值
Python 2.x 返回列表。
Python 3.x 返回迭代器。
以下实例展示了 map() 的使用方法:
实例
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
namedtuple
namedtuple是继承自tuple的子类。namedtuple创建一个和tuple类似的对象,而且对象拥有可访问的属性。
例子:
from collections import namedtuple
# 定义一个namedtuple类型User,并包含name,sex和age属性。
User = namedtuple('User', ['name', 'sex', 'age'])
# 创建一个User对象
user = User(name='kongxx', sex='male', age=21)
# 也可以通过一个list来创建一个User对象,这里注意需要使用"_make"方法
user = User._make(['kongxx', 'male', 21])
print user
# User(name='user1', sex='male', age=21)
# 获取用户的属性
print user.name
print user.sex
print user.age
# 修改对象属性,注意要使用"_replace"方法
user = user._replace(age=22)
print user
# User(name='user1', sex='male', age=21)
# 将User对象转换成字典,注意要使用"_asdict"
print user._asdict()
# OrderedDict([('name', 'kongxx'), ('sex', 'male'), ('age', 22)])
dict与dir()的区别:
dir()是一个函数,返回的是list;
__dict__是一个字典,键为属性名,值为属性值;
dir()用来寻找一个对象的所有属性,包括__dict__中的属性,__dict__是dir()的子集;
并不是所有对象都拥有__dict__属性。许多内建类型就没有__dict__属性,如list,此时就需要用dir()来列出对象的所有属性。
__dict__属性
__dict__是用来存储对象属性的一个字典,其键为属性名,值为属性的值。
结论
dir()函数会自动寻找一个对象的所有属性,包括__dict__中的属性。
__dict__是dir()的子集,dir()包含__dict__中的属性。
以上这篇基于Python __dict__与dir()的区别详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
startswith()方法:
描述
startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
语法
startswith()方法语法:
str.startswith(str, beg=0,end=len(string));
参数
str -- 检测的字符串。
strbeg -- 可选参数用于设置字符串检测的起始位置。
strend -- 可选参数用于设置字符串检测的结束位置。
返回值
如果检测到字符串则返回True,否则返回False。
实例
以下实例展示了startswith()函数的使用方法:
#!/usr/bin/python3
str = "this is string example....wow!!!"
print (str.startswith( 'this' ))
print (str.startswith( 'string', 8 ))
print (str.startswith( 'this', 2, 4 ))
以上实例输出结果如下:
True
True
False
导入模块,加载路径
>>> import sys
>>> sys.path.append('/Users/michael/my_py_scripts')
高级编程:
python
https://blog.csdn.net/m18903718781/article/details/78428878