4.机器学习基础
4.1机器学习的四个分支
4.1.1监督学习
- 监督学习是目前最常见的机器学习类型。给定一组样本(通常由人工标注),它可以学会将输入数据映射到已知目标[也叫标注(annotation)]
- 监督学习主要包括分类和回归,但还有更多的变体,主要包括如下几种 :
- 序列生成(sequence generation)。给定一张图像,预测描述图像的文字。序列生成有时可以被重新表示为一系列分类问题,比如反复预测序列中的单词或标记
- 语法树预测(syntax tree prediction)。给定一个句子,预测其分解生成的语法树
- 目标检测(object detection)。给定一张图像,在图中特定目标的周围画一个边界框。这个问题也可以表示为分类问题(给定多个候选边界框,对每个框内的目标进行分类)或分类与回归联合问题(用向量回归来预测边界框的坐标)
- 图像分割(image segmentation)。给定一张图像,在特定物体上画一个像素级的掩模(mask)
4.1.2无监督学习
- 无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,其目的在于数据可视化、数据压缩、数据去噪或更好地理解数据中的相关性
- 降维(dimensionality reduction)和聚类(clustering)都是众所周知的无监督学习方法。
4.1.3自监督学习
- 自监督学习是没有人工标注的标签的监督学习,你可以将它看作没有人类参与的监督学习。标签仍然存在(因为总要有什么东西来监督学习过程),但它们是从输入数据中生成的,通常是使用启发式算法生成的
- 自编码器(autoencoder)是有名的自监督学习的例子,其生成的目标就是未经修改的输入 。同样,给定视频中过去的帧来预测下一帧,或者给定文本中前面的词来预测下一个词,都是自监督学习的例子[这两个例子也属于时序监督学习(temporally supervised learning), 即用未来的输入数据作为监督]
4.1.4强化学习
在强化学习中, 智能体(agent)接收有关其环境的信息,并学会选择使某种奖励最大化的行动
4.2评估机器学习模型
4.2.1训练集、验证集和测试集
- 开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置
- 信息泄露(information leak)。每次基于模型在验证集上的性能来调节模型超参数,都会有一些关于验证数据的信息泄露到模型中
- 模型一定不能读取与测试集有关的任何信息,既使间接读取也不行
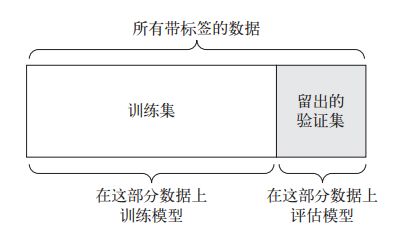
1. 简单的留出验证 (hold-out validation )
- 示意图
- 示例代码
num_validation_samples = 10000
np.random.shuffle(data)
validation_data = data[:num_validation_samples]
data = data[num_validation_samples:]
training_data = data[:]
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
# 现在你可以调节模型、重新训练、评估,然后再次调节……
model = get_model()
model.train(np.concatenate([training_data,
validation_data]))
test_score = model.evaluate(test_data)
- 缺点:如果可用的数据很少,那么可能验证集和测试集包含的样本就太少,从而无法在统计学上代表数据
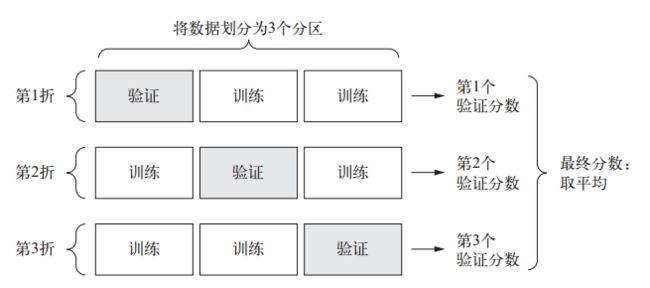
2. K 折验证
- K 折验证(K-fold validation)将数据划分为大小相同的 K 个分区。 对于每个分区 i,在剩余的 K-1 个分区上训练模型,然后在分区 i 上评估模型。最终分数等于 K 个分数的平均值
- 示例代码
k = 4
num_validation_samples = len(data) // k
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
validation_data = data[num_validation_samples * fold:
num_validation_samples * (fold + 1)]
training_data = data[:num_validation_samples * fold] +
data[num_validation_samples * (fold + 1):]
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
validation_scores.append(validation_score)
validation_score = np.average(validation_scores)
model = get_model()
model.train(data)
test_score = model.evaluate(test_data)
3. 带有打乱数据的重复 K 折验证
- 如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复 K 折验证(iterated K-fold validation with shuffling)
- 具体做法是多次使用 K 折验证,在每次将数据划分为 K 个分区之前都先将数据打乱。最终分数是每次 K 折验证分数的平均值。注意,这种方法一共要训练和评估 P×K 个模型(P是重复次数),计算代价很大
4.2.2评估模型的注意事项
- 数据代表性(data representativeness)。你希望训练集和测试集都能够代表当前数据。因此,在将数据划分为训练集和测试集之前,通常应该随机打乱数据
- 时间箭头(the arrow of time)。如果想要根据过去预测未来(比如明天的天气、股票走势等),那么在划分数据前你不应该随机打乱数据,因为这么做会造成时间泄露(temporal leak):你的模型将在未来数据上得到有效训练。在这种情况下,你应该始终确保测试集中所有数据的时间都晚于训练集数据
- 数据冗余(redundancy in your data)。如果数据中的某些数据点出现了两次(这在现实中的数据里十分常见),那么打乱数据并划分成训练集和验证集会导致训练集和验证集之间的数据冗余 。一定要确保训练集和验证集之间没有交集
4.3数据预处理、特征工程和特征学习
4.3.1神经网络的数据预处理
向量化:神经网络的所有输入和目标都必须是浮点数张量(在特定情况下可以是整数张量)。无论处理什么数据(声音、图像还是文本),都必须首先将其转换为张量,这一步叫作数据向量化(data vectorization)
-
值标准化:一般来说,将取值相对较大的数据(比如多位整数,比网络权重的初始值大很多)或异质数据(heterogeneous data,比如数据的一个特征在 0~1 范围内,另一个特征在 100~200 范围内)输入到神经网络中是不安全的。这么做可能导致较大的梯度更新,进而导致网络无法收敛 。输入数据应该具有以下特征 :取值较小:大部分值都应该在 0~1 范围内;同质性(homogenous):所有特征的取值都应该在大致相同的范围内。更严格的标准化方法:将每个特征分别标准化,使其平均值为 0 ;将每个特征分别标准化,使其标准差为 1
# 假设 x 是一个形状为 (samples, features) 的二维矩阵 x -= x.mean(axis=0) x /= x.std(axis=0) 处理缺失值:一般来说,对于神经网络,将缺失值设置为 0 是安全的,只要 0 不是一个有意义的值。网络能够从数据中学到 0 意味着缺失数据,并且会忽略这个值。如果测试数据中可能有缺失值,而网络是在没有缺失值的数据上训练的,应该人为生成一些有缺失项的训练样本:多次复制一些训练样本,然后删除测试数据中可能缺失的某些特征
4.3.2特征工程
特征工程(feature engineering)是指将数据输入模型之前,利用你自己关于数据和机器学习算法(这里指神经网络)的知识对数据进行硬编码的变换(不是模型学到的),以改善模型的效果
特征工程的本质:用更简单的方式表述问题,从而使问题变得更容易
4.4过拟合与欠拟合
机器学习的根本问题是优化和泛化之间的对立
优化(optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习)
泛化(generalization)是指训练好的模型在前所未见的数据上的性能好坏
训练开始时,优化和泛化是相关的:训练数据上的损失越小,测试数据上的损失也越小。这时的模型是欠拟合(underfit)的,即仍有改进的空间,网络还没有对训练数据中所有相关模式建模
但在训练数据上迭代一定次数之后,泛化不再提高,验证指标先是不变,然后开始变差,即模型开始过拟合。这时模型开始学习仅和训练数据有关的模式,但这种模式对新数据来说是错误的或无关紧要的
最优解决方法是获取更多的训练数据。次优解决方法是调节模型允许存储的信息量,或对模型允许存储的信息加以约束
降低过拟合的方法叫作正则化(regularization)
4.4.1减小网络大小
减少模型中可学习参数的个数(这由层数和每层的单元个数决定)
在深度学习中,模型中可学习参数的个数通常被称为模型的容量(capacity)
直观上来看,参数更多的模型拥有更大的记忆容量(memorization capacity),因此能够在训练样本和目标之间轻松地学会完美的字典式映射,这种映射没有任何泛化能力
另一方面,使用的模型应该具有足够多的参数,以防欠拟合,即模型应避免记忆资源不足
一般的工作流程是开始时选择相对较少的层和参数,然后逐渐增加层的大小或增加新层,直到这种增加对验证损失的影响变得很小
4.4.2添加权重正则化
简单模型比复杂模型更不容易过拟合。简单模型(simple model)是指参数值分布的熵更小的模型(或参数更少的模型)
-
强制让模型权重只能取较小的值,从而限制模型的复杂度,这使得权重值的分布更加规则(regular)。这种方法叫作权重正则化(weight regularization),其实现方法是向网络损失函数中添加与较大权重值相关的成本(cost):
- L1 正则化(L1 regularization):添加的成本与权重系数的绝对值[权重的 L1 范数(norm)]成正比
- L2 正则化(L2 regularization):添加的成本与权重系数的平方(权重的 L2 范数)成正比。神经网络的 L2 正则化也叫权重衰减(weight decay)
4.4.3添加 dropout 正则化
对某一层使用 dropout,就是在训练过程中随机将该层的一些输出特征舍弃(设置为 0)。 dropout 比率(dropout rate)是被设为 0 的特征所占的比例,通常在 0.2~0.5范围内。测试时没有单元被舍弃,而该层的输出值需要按 dropout 比率缩小,因为这时比训练时有更多的单元被激活,需要加以平衡
-
为了实现这一过程,还可以让两个运算都在训练时进行,而测试时输出保持不变
layer_output *= np.random.randint(0, high=2, size=layer_output.shape) layer_output /= 0.5 核心思想是在层的输出值中引入噪声,打破不显著的偶然模式(Hinton 称之为阴谋)。如果没有噪声的话,网络将会记住这些偶然模式
4.5机器学习的通用工作流程
4.5.1定义问题,收集数据集
你的输入数据是什么?你要预测什么?只有拥有可用的训练数据,你才能学习预测某件事情。比如,只有同时拥有电影评论和情感标注,你才能学习对电影评论进行情感分类。因此,数据可用性通常是这一阶段的限制因素
你面对的是什么类型的问题?是二分类问题、多分类问题、标量回归问题、向量回归问题,还是多分类、多标签问题?或者是其他问题,比如聚类、生成或强化学习?确定问题类型有助于你选择模型架构、损失函数等
有一类无法解决的问题你应该知道,那就是非平稳问题(nonstationary problem)
4.5.2选择衡量成功的指标
- 对于平衡分类问题(每个类别的可能性相同),精度和接收者操作特征曲线下面积(area under the receiver operating characteristic curve, ROC AUC)是常用的指标
- 对于类别不平衡的问题,你可以使用准确率和召回率
- 对于排序问题或多标签分类,你可以使用平均准确率均值(mean average precision)
- 自定义衡量成功的指标也很常见
4.5.3确定评估方法
- 留出验证集。数据量很大时可以采用这种方法
- K 折交叉验证。如果留出验证的样本量太少,无法保证可靠性,那么应该选择这种方法
- 重复的 K 折验证。如果可用的数据很少,同时模型评估又需要非常准确,那么应该使用这种方法
4.5.4准备数据
- 如前所述,应该将数据格式化为张量
- 这些张量的取值通常应该缩放为较小的值,比如在 [-1, 1] 区间或 [0, 1] 区间
- 如果不同的特征具有不同的取值范围(异质数据),那么应该做数据标准化
- 你可能需要做特征工程,尤其是对于小数据问题
4.5.5开发比基准更好的模型
这一阶段的目标是获得统计功效(statistical power),即开发一个小型模型,它能够打败纯随机的基准(dumb baseline)
-
要记住你所做的两个假设:
- 假设输出是可以根据输入进行预测的
- 假设可用的数据包含足够多的信息,足以学习输入和输出之间的关系
-
需要选择三个关键参数来构建第一个工作模型:
- 最后一层的激活。它对网络输出进行有效的限制
- 损失函数。它应该匹配你要解决的问题的类型
- 优化配置。你要使用哪种优化器?学习率是多少?大多数情况下,使用 rmsprop 及其默认的学习率是稳妥的

4.5.6扩大模型规模:开发过拟合的模型
- 要搞清楚你需要多大的模型,就必须开发一个过拟合的模型,这很简单:添加更多的层;让每一层变得更大;训练更多的轮次
- 如果你发现模型在验证数据上的性能开始下降,那么就出现了过拟合。下一阶段将开始正则化和调节模型,以便尽可能地接近理想模型,既不过拟合也不欠拟合
4.5.7模型正则化与调节超参数
-
你将不断地调节模型、训练、在验证数据上评估(这里不是测试数据)、再次调节模型,然后重复这一过程,直到模型达到最佳性能。你应该尝试以下几项:
- 添加 dropout
- 尝试不同的架构:增加或减少层数
- 添加 L1 和 / 或 L2 正则化
- 尝试不同的超参数(比如每层的单元个数或优化器的学习率),以找到最佳配置
- (可选)反复做特征工程:添加新特征或删除没有信息量的特征
请注意:每次使用验证过程的反馈来调节模型,都会将有关验证过程的信息泄露到模型中。如果只重复几次,那么无关紧要;但如果系统性地迭代许多次,最终会导致模型对验证过程过拟合
一旦开发出令人满意的模型配置,你就可以在所有可用数据(训练数据 + 验证数据)上训练最终的生产模型,然后在测试集上最后评估一次
本章小结
- 定义问题与要训练的数据。收集这些数据,有需要的话用标签来标注数据
- 选择衡量问题成功的指标。你要在验证数据上监控哪些指标?
- 确定评估方法:留出验证? K 折验证?你应该将哪一部分数据用于验证?
- 开发第一个比基准更好的模型,即一个具有统计功效的模型
- 开发过拟合的模型
- 基于模型在验证数据上的性能来进行模型正则化与调节超参数