前言
前几天跟一个朋友聊天,忽然就说到IT技术上来了。作为IT从业者的我,说起自己的本行自然滔滔不绝、天花乱坠。我的这个朋友精通数据库技术和数据处理,而这两个方面正好是我的短板。说到这两个技术,我只有听的份,内心惭愧不已。
一直以来,我对于数据库的研究和使用只局限于逻辑层次的应用与简单的运维,算是入门级别吧,按照招聘术语来划分的话,这应该属于是熟悉的程度。我对于数据库深层次的原理很少去探究,因此,在谈及数据库深层技术时,倍感吃力。在聊天过程中,我的这位朋友说,过去、现在、未来,计算机硬件的运算速度将不再是影响计算机性能的主要因素,一套系统的瓶颈往往出现在对于各种I/O的使用、控制、管理和优化上。这些I/O包括内存I/O、磁盘I/O、网络I/O等。一个数据库的I/O往往会包含内存、磁盘和网络三个层次的I/O,因此,增加数据库方面的知识,对于提高一套系统的性能至关重要。从另外一个方面来说,虽然现在市场上有很多NoSQL,但是,结构化的数据,当然最好还是使用SQL来处理,这有这样才能起到高效快捷管理数据的目的,一味的放弃sql相关知识的学习必将导致知识体系脱节,造成考虑事情不全面等诸多问题。于是,我回到家后,立马找出了封存已久的数据库书籍,应了那句话,书到用时方恨少,看着泛黄的书页,心中五味杂陈。我最终选择了MySql作为我重新学习数据库的突破口,一方面是因为,mysql是开源的,社区的支持力度大,个人的参与度更高。另一方面,是因为淘宝在mysql应用方面树立了榜样。这里简单说一下淘宝的mysql应用进化史。

淘宝起源于2003年的非典,最开始使用的是LAMP架构,那个时候,用的是mysql4.0以下的版本。可能是因为老天的眷顾,2003年的非典,给予了电子商务极大的发展空间和发展动力,到了2003年年底,淘宝网业务井喷,mysql也升级为了基于MyISAM引擎的4.0版本。但是好景不长,之后由于MyISAM引擎对于高并发支持的并不好,淘宝更换了数据库架构,全面改用小型机+oracle的存储架构,就这样,之后几年的淘宝网的发展,都是得力于oracle框架的支持。但是,oracle存在顶配天花板的问题,即使使用了最好的硬件,也是无法突破性能的瓶颈。这个时候,淘宝已经积累了大量的技术经验和财富,于是,果断于2008年,进行了数据迁移,从oracle迁移回mysql。这个时候的mysql已经进化到了基于InnoDB引擎的5.0版本,性能和效率已经不可同日而语。在InnoDB引擎的支持下,淘宝不仅更换了存储架构,还将原有的垂直结构,变更为了水平分布式结构,大大提升了高并发、高数据I/O压力下的数据可用性。淘宝在2009~2012年间,不断的探索和重构,最终将核心交易系统的架构变更为pc+mysql集群的形式,并建立了超过2000个数据库实例。记得看过一个报告,在2012年的光棍节期间,淘宝通过pc+mysql+闪存系统(或固态硬盘系统)集群,已经完成了单库承受6.5万QPS(每秒查询率)的壮举,对了,还有个32个节点的核心集群服务,能承受的总QPS也稳定在86万以上。淘宝的这个例子展示了关系型数据库发展和进化的历史,作为最基础的IT技术,关系型数据库一定会和非关系数据一起撑起一片不一样的天空。
mysql分支与变种

mysql先被sun收购,再被oracle收购。两次转让,出现了好多变种,其中用三个主流变种:Percona Server、MariaDB、Drizzle。
| 变种 | 说明 |
|---|---|
| Percona Server | 为了改进MySql服务器的日志而产生 |
| MariaDB | sun收购mysql后,创始人Monty Widenius因为理念不同而创造了MariaDB |
| Drizzle | 真正的MySql分支,不与mysql兼容 |
Percona Server
Percona Server是一个与MySql向后兼容的替代品,没有改变sql语法、客户端/服务器协议和磁盘文件格式(通过配置可以改变文件格式)。使用Percona Server非常简单,只需要关闭mysql,打开Percona Server即可,不需要导入导出数据。可以使用Percona Server作为调试临时的解决方案。
Percona Server包括向后兼容的Percona XtraDB存储引擎和改进版的InnoDB引擎。创建一个使用InnoDB存储引擎的表,Percona Server能自动识别并用Percona XtraDB代替。
| 目标 | 说明 |
|---|---|
| 透明 | 增加查看服务器内部信息的方法,包含show status的计数器,information_schema中的表,慢查询日志增加详细信息 |
| 性能 | 提高性能的可预测性和稳定性,增加InnoDB的优化 |
| 操作灵活性 | 移除某些限制 |
MariaDB
MariaDB包括了更多对服务器的扩展,这样说吧,Percona Server的不同在于Percona XtraDB存储引擎,而MariaDB的不同,则在于对于服务器层面的改造。例如,增加了查询优化,改变了复制的方法,使用Aria存储引擎替代MyISAM来存储临时表,另外,MariaDB还提供了Sphinx SE和PBXT。
MariaDB是mysql的一个超集,使用MariaDB和使用Percona Server一样,只需要关闭mysql,打开MariaDB即可,不需要导入导出数据。MariaDB对于复制的子查询和多表关联处理的特别好,这也是它存在的价值所在。(MariaDB做了很多查询的优化,如查询执行计划的哈希联合,并修复了动态列、基于角色的访问控制、微秒级的时间戳支持等)
Drizzle
Percona Server和MariaDB是mysql的变种,Drizzle则是mysql的分支,Drizzle不兼容mysql,对于sql语法也做了非常大的修改,并且对于代码内核也做了极大的精简,去除了许多函数和插件。同时,Drizzle是一个社区开发的项目,在开源社区,Drizzle比mysql更加的引人注目。

Drizzle的目标是更好的满足网页应用的核心功能,与mysql相比,Drizzle更简单,提供的功能选择更少,例如,它只使用utf-8作为存储字符集,并且只有一种类型的blob,它主要针对64位硬件编译,且支持ipv6网络。
Drizzle还要消除mysql的异常和遗留行为,例如声明了not null,但是却发现数据库中莫名其妙的存储了null,一些mysql上的烂特性已经被去除,例如触发器、查询缓存、insert on duplicate key update
小结
如果想要与官方mysql版本尽量保持紧密联系,并且想获得更好的性能、指导和有用的特性,那么就应该选择Percona Server,如果想要选择社区支持更好的存储引擎的话,就应该选择MariaDB。如果想要一个轻量级精简版的数据库,又不需要与mysql兼容,则可以选择Drizzle
mysql的历史
| 版本 | 时间 | 说明 |
|---|---|---|
| 3.23 | 2001 | 一般认为是商用mysql的第一版,在flat file上实现sql查询,引入了MyISAM代替ISAM,InnoDB可以通过手工编译的方式引入,还提供了全文索引和复制功能。 |
| 4.0 | 2003 | 增加如union和delete等语法,重写了复制,边单线程复制为多线程复制,InnoDB成为标配,增加了行级锁、外键等特性,引入查询缓存,支持ssl连接 |
| 4.1 | 2005 | 增加如子查询和insert on duplicate key update等语法,支持utf-8字符集,支持二进制协议和prepared语句 |
| 5.0 | 2006 | 增加企业级特性如视图、触发器、存储过程、存储函数,去除ISAM引擎、引入Federated等引擎 |
| 5.1 | 2008 | sun收购mysql后的首个版本,增加分区、基于行的复制、plugin api,去除berkeyDB引擎(最早的事务引擎)、Federated引擎 |
| 5.5 | 2010 | oracle收购sun后的首个版本,增加性能、扩展性、复制、分区、win支持等,去除遗留特性,增加复制、认证、审计api,增加performance_schema库,增加半同步复制(semisynchronous replication)、商用认证插件、thread pooling,InnoDB增加buffer pool等 |
| 5.6 | 2011 | 改进InnoDB,提供nosql访问接口,可通过Memcached的api访问innodb,提升复制性能,改进performance_schema库,为该库增加表锁、表io、表锁等待等特性。提升查询效率。 |
| 5.7 | 2015 | 进一步优化innodb以全部支持大数据、高并发的互联网特性等,调整sql语法、参数,增加安全特性,支持aes加密等模式 |
老的版本的mysql做了很多破坏性创新,因为是社区产品,因此,没有按照企业级应用那样去做。此处给出一个mysql的测试环境,cisco ucs 才50,6核*2cpu,每个核支持两个线程,384gb内存,测试数据2.5gb,buffer pool设置为4gb,采用sysbench-read-only只读压力测试,采用innodb存储引擎,所以数据放入内存,进行cpu-bound(cpu密集型)测试。每次测试持续60分钟,每10秒获取一次吞吐量结果,前900秒用于预热数据,以免预热时的io影响测试结果。测试发现,简单单线程测试,老版本好。其他都是新版本好。(没有做TPC-C测试)。另外,在选择mysql作为生产环境时,要选择GA(Generally Available)版本。另外,很关键的一点,innodb提供了外键解析功能,这个是与很多其他数据库所不一样的。
mysql的架构
mysql是一种非常灵活的轻量级数据库,可以嵌入系统使用,也可以支持高并发、高可用的冗余系统,还可以支持数据仓库、内容索引、在线事务处理等企业级应用。mysql的这种独特之处是因为它的存储引擎架构将query processing、server task和data read-write等功能进行了分离。接下来,我就来详细的说说mysql的架构和设计特点。
逻辑架构
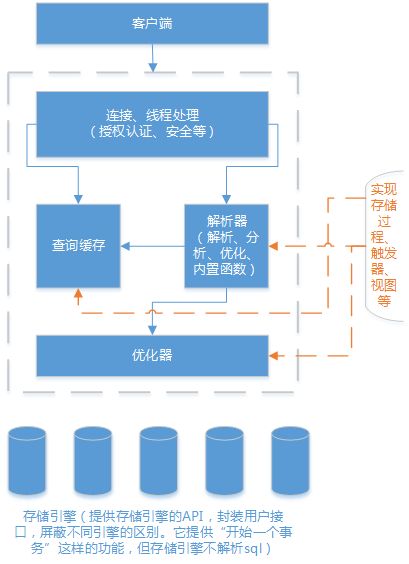
每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个单独的线程中执行,该线程只能轮流在某个cpu核心中运行,服务器会负责缓存线程,因此,不需要为每一个新建的连接创建或销毁线程,或者直接使用线程池功能,来维护大量的可用连接。
当客户端、连接到mysql,服务器需要对其进行认证,认证基于用户名、原始主机信息和密码。使用ssl方式连接还可以增加x.509的证书认证功能,一旦客户端连接成功,服务器还会继续验证该客户端是否具有执行某个特定查询的权限。(x.509设定了一系列严格的CA分级体系来颁发数字证书,任何人,不仅仅是特定的CA,都可以签发并验证其他秘钥证书的有效性)
优化与执行
mysql会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询、决定表的存取顺序、选择合适的索引。用户可以通过特殊的关键字提示(hint)优化器,影响它的决策过程。也可以请求优化器解释(explain)优化过程的各个因素,使用户可以知道服务器是如何进行优化决策的,并提供一个参考基准,便于用户重构查询和schema、修改相关配置,使其高效运行。优化器还会请求存储引擎提供容量或某个具体操作的开销信息,以及表数据的统计信息等,例如某些存储引擎可能对一些特定的查询有优化效果。
对于select,在解析查询前,服务器会先检查查询缓存(query cache),如果能够在其中找到对应的查询,服务器就不必再执行查询解析、优化和执行了,直接返回查询缓存的结果集。
并发控制
并发是因为多个语句需要在同一时间修改数据。在mysql中存在两个层面的并发,服务器层面和存储引擎层面。此处只简单说说mysql如何控制并发读写。
1.读写锁
处理读写并发时,可以实现一个两个类型的锁组成的锁系统来解决问题,一般称作共享锁(shared lock)和排他锁(exclusive lock),也可以称为读锁(read lock)和写锁(write lock)。shared lock = read lock,exclusive lock=write lock。排他锁会进行阻塞其他语句的执行,同一时间内,只有一个排他锁执行某语句,后续语句的执行,需要等待解锁(或者说完成一次写后,才能再次写入并加排他锁)
2.锁颗粒
只会针对修改的数据片进行精确的锁定,不会锁住整个资源(线程)。在给定的资源上,锁定的数据量越少,则系统的并发程度就越高,只要相互之间不发生冲突即可。
另外,加锁也是消耗系统资源的一种行为,例如获得锁、检查锁状态(解锁或锁定)、释放锁等,都会增加系统开销,因此,就需要增加锁策略。其他的数据库,提供的是row-level lock,mysql则不同,mysql的每种存储引擎都可以实现自己的锁策略和锁粒度。在存储引擎的设计中,锁管理是非常重要的,将锁粒度固定在某个级别,可以为某些特定的应用场景提供更好的性能,但同时却会失去对另外一些场景的良好支持。
3.table lock
开销最小的锁策略,锁定整张表,一个用户对表进行写操作(insert、delete、update)前,需要先获得写锁,这会阻塞其他用户对该表的所有读写操作。写锁比读锁拥有更高的优先权,因此,会加塞到读锁前边执行。在read local表锁支持某些并发下,表锁也可能有良好的性能,还有,服务器会为诸如alter table之类的语句使用表锁,而忽略存储引擎的锁机制
4.row lock
最大限度的支持并发,当然开销也比table lock大。行级锁在存储引擎中实现(innodb或者xtradb等)
事务
事务就是一组原子性sql集合,要么全执行,要么都不执行(这里是事务的ACID概念,原子性(Atomicity)、一致性(Consistency)、隔离性或其他事务不可影响性(Isolation)、持久性(Durability))。因为,实现事务需要更大的开销,因此,对于一些不需要事务的查询,可以选择没有实现ACID的存储引擎来获取更高的性能。
1.隔离级别(ANSI隔离级别)
sql标准中定义了四种隔离级别,每一种级别都规定了一个事务中所作的修改,哪些在事务内部和事务间可见,哪些不可见,较低级别的隔离通常可以执行更高的并发,系统的开销也更低。
| 隔离级别 | 说明 |
|---|---|
| read uncommitted | 也叫dirty read,只要没有提交,就可以读取待提交的数据。不应该使用。 |
| read committed | 也叫nonrepeatable read,除mysql外,基本上都默认这种隔离级别,一个事务开始时,只能看见已经提交的事务所做的修改。 |
| repeatable read | 保证同一个事务中多次读取同样记录的结果一样。但是解决不了phantom read的问题,需要innodb和xtradb通过mvcc(multiversion concurrency control)来解决 |
| serializable | 可串行化,这是最高级别的隔离,强制事务串行执行,在读取的每一行数据上都加锁,会存在超时和锁争用问题,实际应用中,也很少用到。 |

2.死锁
死锁是多个事务在同一资源上相互占用,并请求锁定对方占用的资源的行为,死锁会导致恶性循环。当多个事务视图以不同顺序锁定资源时,就可能发生死锁,多个事务同时锁定同一资源时,也会产生死锁。一般需要外边因素介入才能解决死锁问题。mysql提供了死锁检查和死锁超时机制,在innodb中,可以检测死锁的循环依赖,并返回错误。innodb会将持有最少行级的排他锁事务进行回滚。
锁的行为和顺序是和存储引擎相关的,以同样的顺序执行的语句,有些存储引擎会产生死锁,有些则不会,死锁的产生会有双重原因,有些是因为真正的数据冲突,这种情况通常很难避免,但有些则完全是由于存储引擎的实现方式所导致。死锁发生后,只有回顾一部分事务才能打破死锁,对于事务型的系统来说,这是无法避免的,所以应用程序在设计时,必须考虑如何处理死锁。大多数情况下,只需要重新执行因死锁回滚的事务即可。
3.事务日志
事务日志可以帮助提高事务的效率,使用事务日志,存储引擎在修改表的数据时,只需要修改其内存拷贝,再把该修改行为记录到硬盘上的事务日志中,而不用每次都将修改的数据本身持久化到磁盘。事务日志采用的方式是追加数据,因此,写日志的操作是在磁盘上一小块区域内的顺序io,不需要随机io在磁盘上多个地方移动磁头,所以,采用事务日志的方式相对来说要快得多。事务日志持久化之后,内存中被修改的数据在后台可以慢慢地刷回到磁盘,目前大多数存储引擎都是这样实现的,我们通常称之为write-ahead logging,修改数据需要写两次磁盘。如果只是事务日志持久化,数据本身未写入磁盘,系统崩溃的话,存储引擎在重启时能够自动恢复这部分修改的数据。
4.mysql的事务
基于innodb、ndb cluster、xtradb、pbxt来实现各自存储引擎的事务,一般提供如下功能。
| 功能 | 说明 |
|---|---|
| autocommit | 默认打开,如果不显式的开始一个事务,则每个查询都被当做一个事务,show variables like 'autocommit',set autocommit = 1,1为开启,0为关闭。当关闭时,所以查询都在一个事务中,除非显式的执行commit或者rollback,修改autocommit对非事务型的表,比如MyISAM或者内存表不会有任何影响。另外,如DDL类操作时,比如alter table、lock table,会强制执行commit提交当前的活动事务。 |
| 隔离级别设置 | 通过set transation isolation level来设置不同的ansi 隔离级别 |
| 事务混合引擎 | 一般情况下将事务性表和非事务性表的引擎混合使用会存在,非事务性的表无法回滚的问题。 |
| 隐式和显式锁定 | innodb采用two-phase locking protocol,在执行事务过程中,随时都可以执行锁定,并通过commit or rollback在同一时刻释放锁,这些锁就是1隐式锁,或者自动锁。innodb还可以显式锁定,但是这个不属于sql规范,一般情况下,不需要显式加锁。显式加锁不仅影响效率,还会造成某些问题 |
mvcc-多版本并发控制
oracle、postgresql、mysql都各种用不同方式实现了mvcc。大多数事务都不是简单的行级锁,因此mvcc很有必要。mvcc避免了某种加锁操作,因此,降低了开锁频率,提供性能。通过mvcc可以实现非阻塞读操作和行级锁写操作。
mvcc的实现是通过保存数据快照来实现的。因此,不过执行时间,所以事务在这段时间内看到的数据都是一致的。mvcc有optimistic 并发控制和pessimistic 并发控制两种主要实现方式,下面我们来看看innodb是如何实现mvcc。
innodb的mvcc是通过在每行记录后面保存两个隐藏列来实现的。这两列,一个保存了行的创建时间(创建系统版本号),一个保存行的过期时间(过期系统版本号)。每开始一个新事务,系统版本号都会自动递增,事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。我们来看一下pepeatable read下的mvcc是如何运行的:
select,innodb查询系统版本号小于或等于当前事务的系统版本号的数据行,这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入的或者修改的。行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
insert,每次插入都会保存最新的系统版本号作为行版本号。
delete,每次删除都会保存最新的系统版本号作为删除版本号。
update,innodb会插入一行新纪录,保存最新的系统版本号作为行版本号。同时保存最新的系统版本号作为行版本号作为原来行的删除版本号。
保存着两个额外的系统版本号,可以确保大多数读操作不要加锁。mvcc只在repeatable read和read committed下工作,其他两个隔离级别都和mvcc不兼容。read uncommitted 总是读取最新的数据行,而不是符合当前事务版本的数据行,serializable则会对所有的读取行都加锁。
mysql的存储引擎
mysql将每个数据库(mysql数据库也可以称之为schema)保存为数据目录下的一个子目录。创建表时,mysql会在数据库子目录下创建一个和表同名的.frm文件保存表的定义。因此,表的定义在mysql中是由服务层统一管理的。因此,大小写敏感与具体的平台相关。在win中大小写不敏感,在unix中则是敏感的。
使用show table status或者查询information_schema来显示表的相关信息
show table status like 'user' \g

| 行名 | 说明 |
|---|---|
| name | 表名 |
| engine | 存储引擎 |
| row_format | 行格式,MyISAM的可选值为dynamic、fixed、compressed,dynamic的行长度可变,是被varchae或者blob定义,fixed的行长度固定,被chae或者integer定义,compressed的行则只在压缩表中存在 |
| rows | 表中行数,在myisam中该值为精确值,在innodb中该值是估算值 |
| avg_row_length | 平均每行包含的字节数 |
| data_length | 表数据大小,单位为字节 |
| max_data_length | 表数据的最大容量,与存储引擎有关 |
| index_length | 索引大小,单位为字节 |
| data_free | 对于·myisam表,表示已经分配单目前没有使用的空间,这部分空间包括了之前删除的行,以及后续可以被insert利用到的空间 |
| auto_increment | 记录下一个auto_increment值 |
| create_time | 表的创建时间 |
| update_time | 表的最后修改时间 |
| check_time | 使用check table或者myisamchk工具最后一次检查表的时间 |
| collation | 表的默认字符集和字符列排序规则 |
| checksum | 如果启用,保存的是整个表的实时校验和 |
| create_options | 创建表时指定的其他选项 |
| comment | 额外信息,在myisan中,保存的是表在创建时带的注释。在innodb中,保存的是innodb表空间的剩余空间信息,如果是一个视图,则该列包含view的文本字样。 |
innodb
mysql的默认事务型存储引擎。被设计处理大量的short-lived事务,也就是处理大量提交,很少回滚的事务。innodb被推荐使用,不管是事务型操作还非事务型操作。
innodb有很多特性,例如building index by sorting(利用排序创建索引)、删除或者增加索引时不需要复制全表数据、新的支持压缩的存储格式、新的大型列值blob的存储方式等。
innodb的数据存储在table-space中,table-space是由innodb管理的一个黑盒子,由一系列的数据文件组成。innodb采用mvcc来支持高并发,并实现了四个标准的隔离级别。默认级别是repetable read,并通过next-key locking策略防止幻读的出现。next-key locking使innodb不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定,以防止幻行的插入。
innodb表是基于聚簇索引建立的,聚簇索引对主键查询有很高的性能,不过在二级索引(secondary index,非主键索引)中必须包含主键列,所以主键列很大的话,其他所有索引也都会非常大,因此,弱表上的索引较多的话,主键应该尽可能的小。innodb的存储格式是平台独立的,因此,可以将数据和索引从intel平台复制到powerpc或者sunsparc等任何平台。
innodb还做了很多优化,如从磁盘读取数据时采用的可预测性预读,能够自动在内存中创建hash索引以加速读操作的自适应哈希索引(adaptive hash index),以及能够加速插入操作的插入缓冲区(insert buffer)等。
更多知识需要去阅读官网的innodb事务模型和锁这一节。
innodb通过一些机制和工具支持真正的热备份,例如oracle提供的mysql enterprise backup,percona 提供的xtrabackup
mysql的其他存储引擎不支持热备份,因此,要获取一致性视图需要停止对所有表的写人,而在读写混合场景中,停止写入可能意味着停止读取。
MyISAM
myisam提供全文索引、压缩、空间函数(GIS)等,不支持事务、行级锁,崩溃后不能安全恢复。适用于只读数据,小表,以及可以忍受修复(repair)操作的场景
myisam将表存储在两个文件中,数据文件和索引文件,分别以.myd和.myi作为扩展名。myisam根据表定义来决定表可以包含动态行还是静态行,myisam的表的大小,受限于磁盘大小和操作系统中单个文件的最大尺寸。
通过修改max_rows和avg_row_length可以实现改变表的大小,因为二者相乘就是表可以达到的最大大小。修改这两个参数会导致重建整个表和表的所有索引,这可能需要很长的时间才能完成。
myisam是mysql最早的存储引擎,支持如下特性
| 特性 | 说明 |
|---|---|
| 加锁与并发 | 整表加锁,不管是读数据(共享锁)还是写数据(排他锁)都是整表加锁。可以在读的同时进行concurrent insert |
| repair | 通过check table mytable检查表的错误,并通过repair table mytable修复,如果mysql服务器关闭,也可以通过myisamchk工具检查和修复 |
| 索引 | 即使是blob和text等长字段,都可以根据前500个字符创建索引,也支持全文索引。全文索引是一种基于分词创建的索引,可以支持复制的查询。 |
| delayed key write | 延迟更新索引键,需要在创建表时指定delay_key_write选项,每次修改执行完成时,不会立刻将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区(in-memory key buffer),只有在清理键缓冲区或者关闭表时才将索引写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作,延迟更新索引键的特性,可以在全局设置,也可以为单个表设置。 |
myisam压缩表,如果一个表创建并导入数据后,不会再进行修改操作,那么这样的表适合压缩。使用myisampack对其进行压缩,压缩表也就是不能修改的表,除非先解压缩,修改数据,再次压缩。压缩表可以极大的减少磁盘空间占用,减少磁盘io,提升查询性能,压缩表也支持索引,但是索引时只读索引。
其实以现在的硬件能力,对大多数场景,解压的开销远远低于减少io带来的好处,压缩表中的记录是独立压缩的,所以读取单行的时候,不需要去解压整个表。
myisam引擎设计简单,数据以紧密格式存储,所以在某些场景下的性能很好,另外提供了索引键缓冲区(key cache)的mutex锁,mariadb基于segment的索引键缓冲区机制来避免该问题。
但是myisam最典型的性能问题还是表锁的问题,如果发现所有查询都长期处于locked,那么毫无疑问是因为表锁的问题。
其他存储引擎
| 引擎 | 说明 |
|---|---|
| archive | 支持insert和select操作,支持索引,缓存所有的写,利用zlib对插入进行压缩,索引比myisam的io更少,但是,select查询都要全表扫描。archive适合日志和数据采集类应用,因为支持行级锁和专用缓冲区,因此可以实现高并发插入。会对select进行阻塞,一个时间只有一个select进行查询,以实现一致性读。因此,这是一个高速插入和压缩做了优化的简单引擎 |
| blackhole | 无存储机制,不保存数据。对操作会记录日志,可以用于复制数据到备库,或者只是简单的记录到日志。不推荐使用 |
| CSV | 使用csv文件作为mysql表来处理,但是不支持索引。可以作为mysql与外部工具进行交互的一种工具,excel生产的csv可以直接在mysql里通过csv引擎打开,同理,mysql生产的csv也可以给excel操作。 |
| federated | 访问其他mysql服务器的一个代理,创建一个到远程mysql的客户端连接,并且将查询在远程服务器执行,然后提取或者发送需要的数据。不推荐使用。 |
| memory | 内存数据表,无磁盘io,或者heap表,数据不会被修改,重启之后就会丢失,比myisam快一个数量级,适合使用内存数据的应用场景。memory可以在很多场景下发挥作用,例如lookup or mapping表,将邮编和州名做映射的表这样的场景,还有缓存周期性聚合数据(periodically aggregated data)的结果,还可以用于保存数据分析中产生的中间数据。memory表支持hash索引,因此查找操作非常快。memory表是表级锁,因此,写入性能较低,也不支持blob or text类型的列,并且每行的长度是固定的,所以即使指定了varchar列,实际存储时,也会转换为char,这可能导致部分内存的浪费。如果mysql在执行查询的过程中需要使用临时表来保存中间结果,内部使用的临时表就是memory表,如果中间结果太大超出了memory表的限制,或者含有blob or text字段,则临时表会转换成myisam表。此处要注意,临时表是使用create temporary table语句创建的表,它可以使用任何存储引擎,因此与memory表不是一回事。临时表只在单个连接中可见,当连接断开时,临时表也将不复存在 |
| merge | merge是由多个myisam表合并而来的虚拟表,如果mysql用于日志或数据仓库类应用,该引擎可以发挥作用。但引入分区后,该引擎已经被放弃 |
| ndb集群引擎 | mysql集群-mysql cluster:mysql服务器、ndb集群存储引擎,分布式、share-othing、容灾的、高可用的ndb数据库的组合 |
第三方存储引擎
oltp类引擎
percona xtradb存储引擎是基于innodb引擎的一个改进版本,已经包含在percona server和mariadb中,xtradb主要改进点是提供性能、可测量性和操作灵活性方面。xtradb可以作为innodb的完全替代品。
另外还有innodb非常类似的oltp类存储引擎,都支持acid事务和mvcc。例如pbxt,支持引擎级别的复制、外键约束,并且以一种比较复杂的架构对ssd提供了适当的支持,还对较大的值类型如blob也做了优化。
tokudb引擎使用了一种新的叫做分形树(fractal trees)的索引数据结构。该结构是缓存无关的,因此,即使其大小超过内存性能也不会下降,也就没有内存生命周期和碎片的问题。tokudb是一种大数据存储引擎,因为其拥有很高的压缩比,可以在很大的数据量上创建大量索引。
rethinkdb,采用只能追加的写时复制B树(append-only copyon-write b-tree)作为索引的数据结构。
面向列的存储引擎
| 名称 | 说明 |
|---|---|
| infobright | 为数据分析和数据仓库设计的存储引擎,面向处理TB级的数据而设计,因为数据量巨大,因此,索引也就没啥用处了。 |
| infinidb | 在集群间做分布式查询 |
| luciddb | 知道有这么个存在即可 |
| monetdb | 知道有这么个存在即可 |
社区存储引擎
| 社区存储引擎 | 说明 |
|---|---|
| aria | 之前的名字是maria,所以,这个是mariadb存在的 |
| groonga | 全文索引,号称提供准确而高效的全文索引 |
| oqgraph | 支持图操作,比如查找两点之间的最短路径,用sql很难实现该类操作 |
| q4m | 在mysql内部实现了队列操作,使用sql很难在一个语句实现这类队列操作。 |
| sphinxse | 为sphinx全文索引搜索服务器提供sql接口 |
| spider | 该引擎可以将数据切分成不同的分区,比较高效透明的实现了分片(shard),并且可以针对分片执行并行查询(分片可以分布在不同的服务器上) |
| vpformysql | 该引擎支持垂直分区,通过一系列的代理存储引擎实现。垂直分区指的是可以将表分成不同列的组合,并且单独存储。但对查询来说,看到的还是一张表。该引擎和spider的作者是同一个人。 |
选择合适的存储引擎
推荐innodb,全文索引的话,使用innodb+sphinx,如果不在乎扩展,崩溃后数据恢复的话,还可以用myisam(也就是说,如果不需要事务,只有select和insert操作的话,那么就用myisam吧)
如何转变表的引擎
如果想更换存储引擎的,就需要转换表的引擎。我们使用如下三种方法来进行转换。
| 方法 | 说明 |
|---|---|
| alter table | alter table mytable engine=innodb,使用该方法会消耗很长的时间,会有复制、锁表等一系列的问题。 |
| 导出导入 | 用mysqldump来导出,然后修改create table语句,还有修改表名,因为,一个mysql库中表名不能重复 |
| 综合法 | create table innodb_table like myisam_table,alter table innodb_table engine=innodb,insert into innodb_table select * from myisam_table |
虽然可以更好存储引擎,但是还是不推荐使用的
尾记
选择合适的引擎
首选,优先选择innodb。其他的可以这样搭配,如果用到全文索引,可以用innodb+sphinx。但是不建议混合使用多种存储引擎。
mysql拥有分层的架构,上层是服务器层的服务和查询执行引擎,下层则是存储引擎。理解mysql,就是理解存储引擎和服务层之间处理查询时是如何通过api来回交互的,这个是mysql的核心基础,也是架构精髓。
我们要思考的问题
要按照mysql的方式来思考,关注可靠性和正确性
理解mysql为什么会这样做,而不是mysql做了什么
给出的mysql的内部结构和操作,对于实际应用能带来什么帮助?为什么能有这样的帮助?如何让mysql适合或者不适合特定的需求。
| 问题集合 | 说明 |
|---|---|
| baron schwartz | www.xaprb.com/blog |
| peter zaitsev | |
| vadim tkachenko | |
| percona | percona 公司,percona server5.5 以及他的XtraDB存储引擎都很nb |
| 架构 | 理解架构设计的关键 |
| 存储引擎设计的关键 | |
| 基准测试 | 服务器可以处理的工作负载的类型、处理特定任务的速度,通过基准测试评估服务器在不同负载下的表现,明白在什么情况下基准测试不能发挥作用 |
| 故障诊断+性能分析 | 性能优化、剖析,面向响应时间的方法和cary millsap方法 |
| 索引 | 数据库物理设计 |
| 数据库逻辑设计 | 表设计原则、针对不同数据类型的设计细节差别,数据的处理 |
| 查询 | 分析查询如何执行,利用查询优化器,写查询利用好mysql的特性 |
| 高级特性 | 存储引擎、触发器、字符集 |
| 配置 | 软硬件结合,进行数据库软硬件性能优化,让mysql和应用程序以及硬件良好的一起工作,配置mysql,更好的利用硬件,提供可靠性和鲁棒性 |
| 内部实现 | 如何让操作系统和硬件更好的工作,固态硬盘、高可扩展的硬件配置建议,mysql内部实现,理解行为背后的原理 |
| 复制 | 设置多个服务器从一台主服务器上同步数据,如何复制 |
| 可扩展性 | 高可扩展设计,高可用 |
| 稳定性 | 保证mysql稳定而正确的持续运行 |
| 云技术 | mysql在云技术中的应用 |
| 全栈 | full-stack optimization,从前端到后端的优化,从用户体验开始到数据库的优化 |
| 灾备 | 备份、恢复,抵御停电,攻击、bug,程序员低级错误 |
| 工具 | 学习管理、监控mysql的工具 |
| 版本 | 主版本、percona server、mariadb |
| 检测 | 检测mysql服务器,从服务器获取状态信息,了解状态代表的意义(show innodb status) |
| 大文件复制 | 大文件复制,管理大量数据 |
| explain | explain的正确使用和理解 |
| 锁 | |
| sphinx | 一个基于mysql的高性能全文索引系统 |
| 官方指南 | dev.mysql.com/doc |
| perl | mysql很多工具是perl写的 |
| percona toolkit | percona toolkit是不可多得的mysql公里工具 |
| 其他 | dbi、dbd::mysql |
| 好网站 | www.highperfmysql.com,mysqlperformanceblog.com |
| 宁海元 | www.ningoo.net,weibo.com/NinGoo |
| 周振兴 | orczhou.com |