[TOC]
最近在研究数据采集相关的知识,需要用到Sqoop把关系型数据库的数据导入到Hive里,这里记录下自己的使用心得,更多的是需要注意的地方。
环境准备
OS: MacOS
Hadoop: 2.7.2
Hive: 1.0.0
Sqoop: 1.4.6
根据Sqoop官网说法,Sqoop2 目前还未开发完,不建议在生产环境使用,所以这里选的是Sqoop的稳定版 1.4.6
Hadoop和Hive的安装与配置可以参考网上的资料,Sqoop环境配置注意修改 ${SQOOP_HOME}/conf/sqoop_env.sh ,如果使用MySQL,还要将MySQL的驱动jar包拷贝到 ${SQOOP_HOME}/lib 目录下
Sqoop简介
Sqoop是一个用于Hadoop和关系型数据库或主机之间的数据传输工具。它可以将数据从关系型数据库import到HDFS,也可以从HDFS export到关系型数据库,通过Hadoop的MapReduce实现。
Sqoop命令
执行 $sqoop help, 可以看到Sqoop支持的命令:
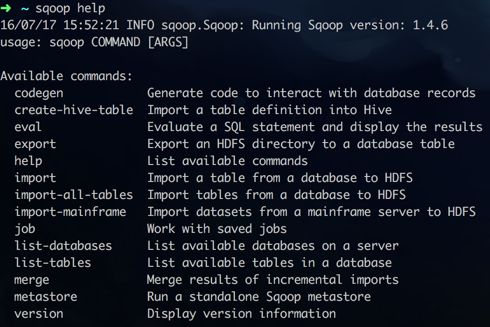
具体使用方法参见官方文档, 这里我们主要介绍下 import 命令的注意点
sqoop-import 注意点
import 可能会用到的参数:
| Argument | Described |
|---|---|
| --append | Append data to an existing dataset in HDFS |
| --as-sequencefile | import序列化的文件 |
| --as-textfile | import plain文件 ,默认 |
| --columns |
指定列import,逗号分隔,比如:--columns "id,name" |
| --delete-target-dir | 删除存在的import目标目录 |
| --direct | 直连模式,速度更快(HBase不支持) |
| --fetch-size |
一次从数据库读取 n 个实例,即n条数据 |
| -m,--num-mappers |
建立 n 个并发执行task import |
| -e,--query |
构建表达式 |
| --split-by |
根据column分隔实例 |
| --autoreset-to-one-mappe | 如果没有主键和split-by 用one mapper import (split-by 和此选项不共存) |
| --table |
指定表名import |
| --target-dir |
HDFS destination dir |
| --warehouse-dir |
HDFS parent for table destination |
| --where |
指定where从句,如果有双引号,注意转义 \$CONDITIONS,不能用or,子查询,join |
| -z,--compress | 开启压缩 |
| --null-string |
string列为空指定为此值 |
| --null-non-string |
非string列为空指定为此值,-null这两个参数are optional, 如果不设置,会指定为"null" |
如果是分布式环境,
--connect参数不要写成localhost,应该写TaskTracker节点的地址数据库登录密码可以指定文件
--password-file ${user.home}/.password这个文件可以放到local或者hdfs上,注意:此文件不能有空格,echo -n "secret" > password.file尽量别用
--password,不安全(ps命令可以获取到此参数), 可以用-P输入console方式, 注意:密码可以设置别名:--password-alias-m并发数默认是4 task, 并发数n不要超过可用的MapReduce集群数,也不要超过数据库支持限度。并发原理:假定split-column = id,数据库中 id = 0-1000,sqoop默认4个task,切成0-250,251-500 ... 不支持多列 split. (可以看到hdfs里有按并发数切了4个切片)当使用Oozie启动Sqoop job时,添加
--skip-dist-cache参数,Oozie会cache job需要的lib包--warehouse-dir可以指定父级目录,与 --target-dir 不共存--map-column-java, --map-column-hive指定某几列映射成Java或Hive的列属性支持增量
--incrementalmode指定为append或lastmodified,还要指定列增量的值,感觉不是很好用,万一数据是更新怎么办?导出数据文件分两种 delimited 和 序列化文件,还可以-z压缩
如果列含有BLOB或CLOB等大型数据列,
--inline-lob-limit可以限制下,暂时先不研究其他涉及到import export特殊字符转义的先不考虑,如果需要可以参见 Table6、7 Format
-
数据导入Hive
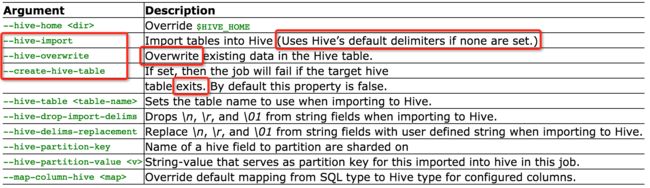
--hive-overwrite: 全表overwrite(需配合
--hive-import使用,如果Hive里没有表会先创建之)--create-hive-table: 自动推断表字段类型直接建表,overwrite功能可以完全替代掉了(但hive里此表不能exist,所以在import前要先drop下)
--hive-import - -hive-overwrite 这两个参数组合很不错 (直接overwrite也可以,但是考虑到如果表结构有变化,hive里是不会感知到的,所以还是先drop吧)
如果含有特殊字符,需要转义可以用
-detlims参数,这个参数只能用于hive默认分隔符默认用"null" 代替 NULL,而Hive
\N标识 NULL值,可以使用--null-string '\\N' --null-non-string '\\N'解决这个问题, 没什么特殊要求就加上吧Hive也可以使用
--compress压缩,但是缺点是很多解码器不支持并行任务的split,貌似lzop解压可以,但是要求颇多,不建议使用Hive里不支持 SQL 类型:bit(2),这样是不妥的,应该改成 bit(1)
- Sqoop支持import到 HBase,Accumulo 时间关系,暂不研究
- 支持额外的参数
conf/sqoop-site.xml自己配置去(-…-)
sqoop-import-all-tables 注意点
-
import-all-tables可以整库的import,但有以为下限制条件:
- 每个表都必须有一个单列主键,或者指定
--autoreset-to-one-mapper参数 - 每个表只能import全部列,即不可指定列import
- 不能使用非默认的分隔符,不能指定 where 从句
-
--exclude-tables此参数可以 exlude掉不需要import的表(多个表逗号分隔) - 不可以使用
--table, --split-by, --columns, --where,--delete-target-dir等等参数 - 不支持
--class-name,可以用--package-name指定package - 一旦执行过程中有异常抛出,会立即停止
sqoop-import-mainframe
直接import主机!这个命令过于暴力,和import-all-tables差别不大,等有需要在研究研究吧。
sqoop-job 注意点
Sqoop可以将import任务保存为job,可以理解为起了个别名,这样方便的Sqoop任务的管理。
参数列表:
| Argument | Described |
|---|---|
| --create |
创建一个job,job-id是job名称, |
| --delete |
删除这个job |
| --exec |
执行这个job |
| --show |
Show the parameters for a saved job. |
| --list | List all saved jobs |
| --meta-connect |
Specifies the JDBC connect string used to connect to the metastore |
job存储方案
job的是有两种存储方案的,通过配置--meta-connect或者在conf/sqoop-site.xml 里配置 sqoop.metastore.client.autoconnect.url 参数来指定是否使用metastore-client
方案A(推荐):不使用metastore-client
如果job信息放到 ${HOME}/.sqoop 目录下,此目录下有两个文件:
metastore.db.properties:metastore的配置信息
metastore.db.script:job的详细信息,通过sql语句存储
方案B: 不使用metastore-client
此时,job的信息会存储到配置的 autoconnect.url 的 SQOOP_SESSION 表里,但是此方案会有个bug,我本地在执行创建job的时候报错:
ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Invalid metadata version
上网查了下解决方案,发现 SQOOP_ROOT 表需要插入条数据:
INSERT INTO SQOOP_ROOT VALUES(NULL,'sqoop.hsqldb.job.storage.version','0');
所以,还是使用方案A吧,这样也不会对数据库造成入侵
注意: 如果使用Oozie执行sqoop-job的话,务必将sqoop-site.xml 中的 sqoop.metastore.client.record.password参数设置为true
其他命令
- sqoop-export:HDFS export 到关系型数据库,目标table必须存在,可分为insert和update模式
- sqoop-metastore:指定metadata仓库,可在配置文件中设置
- sqoop-merge:合并两个数据集,一个数据集的记录应该重新旧数据集的条目
- sqoop-codegen:将数据集封装成Java类
- sqoop-create-hive-table:Sqoop单独提供了针对Hive的命令,可以代替
sqoop import --hive-import, 其他参数一样 - sqoop-eval:执行sql语句,结果会打印在控制台,可以用来校验下import的查询条件是否正确
- sqoop-list-databases,sqoop-list-tables:列出数据库,列出表
以上命令暂时没用到或很简单,等以后需要的时候再去研究吧
HCatalog
HCatalog提供表和存储管理服务,使不同的Hadoop数据处理工具如:Pig,MapReduce,Hive更容易读取和写入数据网格
看文档比较复杂,暂时用不到,等以后需要的时候再去研究吧o(╯□╰)o
需要注意的地方
- MySQL
- MySQL允许Date类型字段出现'0000-00-00',Sqoop有三种方式处理这种情况:1. 转成NULL(默认),2. 抛出异常 3. 置成'0001-01-01', 配置zeroDateTimeBehavior参数设置,跟在connect string后面
- UNSIGNED 列, MySQL 范围:0 ~ 2^32 ,Sqoop范围:-2^31~ +2^31-1, 注意不要越界
- Hive
- DATE, TIME, TIMESTAMP 类型转换到Hive里会被处理为 String
- NUMERIC, DECIMAL 类型转换到Hive里会被处理为 DOUBLE
- Sqoop会打印warn日志警告可能会丢失精度
-
--direct参数目前只有MySQL和PostgreSQL(import) 支持,不支持BLOB, CLOB, LONGVARBINARY 列 -
--direct不支持视图
最佳实践
根据我的个人需求,配置了适合我的最佳Sqoop参数(∩_∩)
单表import到Hive:
sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/database_name \
--username root \
--password 123456 \
--table table_name \
--outdir \${HOME}/.sqoop/java \
--delete-target-dir \
--hive-import \
--hive-overwrite \
--null-string '\\N' \
--null-non-string '\\N' \
-m 8 \
--direct
整库import到Hive:
sqoop import-all-tables \
--connect jdbc:mysql://127.0.0.1:3306/database_name \
--username root \
--password 123456 \
--outdir \${HOME}/.sqoop/java \
--hive-import \
--hive-overwrite \
--null-string '\\N' \
--null-non-string '\\N' \
-m 8 \
--direct
说明:
--out-dir:指定Java文件的路径
--delete-target-dir:删除HDFS目录
--hive-import:直接导入的Hive
--hive-overwrite:全表覆盖(如果表不存在会直接创建表)
--null-string:指定String列如果为NULL转换到Hive里也为NULL
--null-non-string:指定String列如果为NULL转换到Hive里也为NULL
-m 8:8个并发
--direct:直连模式,使用mysqldump加快速度(本地测试13W条数据,74M, 快了10%左右)
最后
通过几天对Sqoop的研究,掌握了Sqoop import的基本用法,更高级的用法还有待探索,最近在写个Sqoop的Java工具类,希望能通过API的形式执行Sqoop命令,以后也会加入Oozie对Sqoop job的管理。
PS:Sqoop2 有很多新特性, 支持命令行、Web UI、REST API,支持server模式同时也更安全易用,所以很期待Sqoop的 2.0 版!