重新复习一下算法图解这本算法入门书,整理一下学习的笔记。一旦开始就不要停下,一旦停下你就不知道自己要停多久了,翻翻上一次记得的笔记,居然已经是一个月前,时间好可怕!
1.二分查找
关于二分查找,就像我们从小玩的猜谜游戏一样,说一个从0到100之间的数字,让你去猜,假如这个数字是79,你第一次说50,我说小了,你就继续说一个大的值,比如75,我说小了,你就说一个88我说大了,你就往小了猜,知道猜到。
用算法的表示就是如果大了,就把右边的边界缩小,如果是小了,就把左边的边界缩小,就是这么简单,但是它的时间复杂度却是logn,比我们遍历查找要高效的多。
下面看代码:
//获取排好序的数组
const getArray = (count)=>{
const array = [];
for(let i = 0;i<=count;i++){
array[i] = i;
}
return array;
}
/**
* 二分查找元素
* @param array 需要查询的数组
* @param element 二分查找的元素
*
* 什么是二分查找,我们从1~100,找一个数,每一次都从数组的中间取,来判断是否相等,
* 如果是大于,则把右边的边界挪到中间,如果是小于,就把左边的边界挪到中间,依次类推,知道找到这个值。
*
* Math.floor() 向下取整
*/
const findElement=(array,element)=>{
let start_index = 0 ;
let end_index = array.length -1;
//左边的边界小于等于右边的边界
while (start_index <= end_index){ //控制缩小的范围
let middle_index = Math.floor((start_index+end_index)/2);//取中间的值
let middle_value = array[middle_index]; //只检查中间的值
console.log("middle_index==",middle_index)
if(middle_value === element){//如果相等,则返回
return middle_index;
}
if(middle_value > element){//猜的数字大了,缩小右边的边界
end_index = middle_index - 1;
}else{
start_index = middle_index + 1;
}
}
return -1;
};
const array = getArray(100);
console.time();
console.log(findElement(array,79));
console.timeEnd();
//输出
middle_index== 50
middle_index== 75
middle_index== 88
middle_index== 81
middle_index== 78
middle_index== 79
79
default: 3.758ms
需要注意的是 javascript中的/无法自己向下取整,所以我们需要用Math.floor()方法来向下取整一下。
2.大O表示法
大O表示法指出的是最糟糕的情况下的运行时间。
一些常见的大O运行时间:
-
O(log n):也叫对数时间,这样的算法包括二分查找。 -
O(n):也叫线性时间,这样的算法包括简单查找。 -
O(n * log n):这样的算法包括快速排序,一种速度较快的排序算法。 -
O(n2):这里是n * n,一种速度较慢的排序算法。 -
O(n!):旅行商问题的解决方案,一种非常慢的算法。
给我们的启示
- 算法的速度是指的并非时间,而是操作数的增速。
- 谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
- 算法的运行时间用大
O表示法表示。 -
O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
3.选择排序
算法图解这本书着重的并不是算法,而是相关的概念描述,让你不知不觉中明白,哦,原来是这么回事儿。推荐阅读。
内存的工作原理
假如你有一天去看演出,需要把东西寄存,寄存处有一个柜子,柜子里很多的抽屉,每一个抽屉可以放一样东西,你有两样东西要寄存,因此要两个抽屉,一个抽屉放雨伞,一个抽屉放兔子,现在你可以看演出了,这大致就是计算机内存的工作原理,计算机就像很多抽屉的集合体,每个抽屉都有地址。
数组和链表
数组是什么?
是内存这个大柜子里,一排连续的抽屉。因为需要每个抽屉相连接,如果你一开始预订了10个抽屉,后来发现放不下了,你就需要往后面扩展,可是如果后面的抽屉被占用了,那么你就只能去其他的地方放,整体的搬过去。
就像你和你的朋友去网吧开黑5联排一样,如果网吧里没有5个相连的电脑,那么你就无法和你的朋友坐在一起了。
如果来一位新朋友,需要坐在你们中间,那么就要后面的朋友都向右移动一位,可是如果没有位置了呢?就需要总体搬迁,非常麻烦。
这样就说道了数组的缺点:
- 你额外请求的位置可能根本就用不上,这就是浪费内存,你没有使用,别人也用不了
- 如果你申请了10个位置,用完以后想要扩充,还得整体搬迁。
链表是什么?
链表中的元素可以存储在内存中的任何位置,而不必相连接,链表的每一个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串联在了一起。
在链表中添加一个元素时,并不需要移动元素,只需要把上一个元素的地址存储为插入元素的地址,插入元素的地址存储断开连接的那个地址就可以了。
还可以避免大数组例如100000这样的连续内存地址,可是如果没有呢,用链表就表示我们分开坐,只要内存足够,怎么也坐的下。
下面是数组和链表的操作时间复杂度。
| - | 数组 | 链表 |
|---|---|---|
| 读取 | O(1) | O(n) |
| 插入 | O(n) | O(1) |
| 插入 | O(n) | O(1) |
选择排序
假如我们有一组歌的数据,我们需要按照播放量从大往小排序。
最简单的做法就是,先从这组数据里找到最大的那个,然后把它拿出来,放到另一个数组里,接着再在这个数据里找到最大的那个,拿出来,放到另一个数组里,直到全部走完。
看代码。
//查找最大的元素
const findElement = (arr)=>{
let small_index = -1 ;//存储最大的值的索引
if(Array.isArray(arr) && arr.length>0){
let small_value = arr[0]; //存储最大的值
small_index = 0;
for(let i = 1;i small_value){
small_value = value;
small_index = i;
}
}
}
return small_index;
};
//选择排序数组
const sortArray = (array)=>{
let sort_array = [];
if(Array.isArray(array) && array.length > 0){
let length = array.length;
for(let i = 0;i 可以看到我们的选择排序使用了两个for循环,时间复杂度O(n*n)。
4.递归
学习递归我们往往都是从阶乘开始的,阶乘就是5*4*3*2*1,这就是阶乘。
function factorial(num){
if(num<=1){
return 1;
}else{
return num * arguments.callee(num-1);//严格模式下不支持
}
}
上面是一个简单的阶乘函数,学习递归需要注意两个条件:基线条件和递归条件。
基线条件:就是控制递归什么时候停下来,如果不停下来,就会一直执行下去,直到触发递归爆栈。
递归条件:控制什么时候应该调用递归函数。
上面的是JavaScript的写法,arguments.callee值一个指向正在执行的函数的指针。
更多信息就不在这里描述。
5.分而治之思想--递归的指导思想
分而治之,你学习的第一种通用的问题解决办法。
分而治之,(divide and conquer ,D&C),一种著名的递归式问题的解决方法。
使用分而治之的思路只要有两条:
- 找到基线条件,这种条件必须尽可能的简单。
- 不断的将问题分解(或者说缩小规模),直到符合基线条件。
在算法图解的书中,举了一个切分土地的例子,假如你有一块长168,宽64的土地,想要平均切分出最大的方块,应该怎么弄呢?
//1.计算土地方块的问题,
const getData = (chang,kuan)=>{
//如果长是宽的N数倍,那么它的最大方块数就是宽 * 宽
let result = -1;
if(chang % kuan === 0){
result = kuan;
}else{
//缩小计算范围。
let value = chang % kuan ;
result = getData(kuan,value);
}
return result;
}
console.log(getData(168,64));
// 8
1.找到基线条件,那就是长是宽的整数倍,那么宽的长度就是最大方块的长度。
2.递归条件,不断将问题分解,通过chang % kuan取余数来当作新的函数的宽,而原来的宽则是长。
这个设计到欧几里得算法。即是适用于这小块地的最大方块,也是适用于整块地的最大方块。
这种分而治之的思想其实在上面的二分查找中我们同样用到了,基线条件就是元素和查找的元素相等,接着每一次递归我们都缩小范围,缩小查询的边界。
同样我们可以使用这种思想来实现查找最大数。
//3.分而治之实现查找列表中的最大数字。
//基线条件--数组为空
const findBigElement = (array,big_value)=>{
let big_element = big_value;
if(array.length > 0){
let [first_value,...otherArray] = array;
if(!big_value){
big_element = first_value;
big_element = findBigElement(otherArray,big_element);
}else if(first_value > big_value){
big_element = first_value;
big_element = findBigElement(otherArray,big_element);
}else{
big_element = big_value;
big_element = findBigElement(otherArray,big_element);
}
}
return big_element
};
console.log(findBigElement([-10000,-2,-3,-10,-1000,-99]))
//-2
快速排序
快速排序也使用了分而治之的思想来实现的。下面我们依照书中的解释推理一下。
- 基线条件,当数组只有一个元素或者是空数组时,就不用进行排序了,因为它只有它自己了。这是基线条件
- 如果是两个元素的呢,检查它们的大小,如果大了,就互换位置。
- 如果是三个元素呢,就取一个基准值,大于这个基准值的放到右边,小于的就放到左边。接着拼接数组并返回。
- 如果是4个元素呢?取一个基准值,大于这个放到右边,小于的放到左边,大于的放到一个数组里,小于的放到一个数组里,对他们的子数组进行快速排序,并返回。
- 如果是5个,类似4的步骤。
下面看代码:
const quickSort=(array)=>{
if(array.length <2){//基线条件
return array;
}else{
let [middle_value,...otherArray] = array; //获取中间判断值,
let left_array = otherArray.filter(item=>item < middle_value);//小于中间值的放在左边--缩小范围
let right_array = otherArray.filter(item=>item > middle_value);//大于中间值的放在右边--缩小范围
left_array = quickSort(left_array);//对左边的数组进行快速排序
right_array = quickSort(right_array);//对右边的数组进行快速排序
return [...left_array,middle_value,...right_array];//合并数组
}
}
console.log(quickSort([1,3,10,4,5,7,2]))
//[ 1, 2, 3, 4, 5, 7, 10 ]
总结:
D&C,分而治之思想将问题逐步分解,使用D&C处理列表时,基线条件很可能是空数组或只包含一个元素的数组。实现快速排序时,请随机的选择用作基准值的元素。快速排序的平均运行时间为
O(n log n).大
O表示法中的常量有时候事关重大,这就是快速排序比合并排序快的原因。比较简单查找和二分查找时,常量几乎无关紧要,因为列表很长时,
O(log n)的速度比O(n)快得多。
6.广度优先搜索
算法图解真的是非常好是算法入门级的书籍。里面的很多概念如果扩展开来都可以出现很多的内容,但是这里,仅仅是介绍它的概念,并让你有兴趣自己去做一些深入的研究。
广度优先搜索是用来解决什么问题的呢?
它可以让你能够找出两样东西之间的最短距离,不过最短距离的含义有很多!
- 编写国际跳棋AI,计算最少走多少步可以获胜
- 编写拼写检查器,计算最少编辑多少个地方就可将拼错的单词改成正确的
- 根据你的人机关系网络找到关系最近的医生
- 出去旅游规划最短的旅游路线等。
书中给我们居了一个路线规划的例子,假如你居住在旧金山,要从双子峰前往金门大桥,你想要乘公交车前往,并希望换乘最少.而解决最短路劲问题的算法就叫广度优先搜索。
要确定如何从双子峰前往金门大桥,需要两个步骤:
- 使用图来建立问题模型
- 使用广度优先搜索解决问题。
那么问题来了?
什么是图呢?
说到图是什么,可能想到的是图片,并不是,图形容的是关系,是连接,比如你和你的朋友,你朋友的朋友,组织成的人际关系网,就是图。
图是由节点和边组成,在人际关系中,个体,比如说你就是结点,而你和老田是朋友,那么你们之间就有联系,就是边。这样就组成了图。
我们可以用图来建立上面乘车的模型,也可以模拟其他的。
而广度优秀搜索则是一种用于图的查找算法。它可以帮助我们回答两类问题:
- 从节点A出发,有前往节点B的路劲吗?
- 从节点A出发,前往节点B的路劲中,哪条路劲最短?
下面的例子我们先来回答第一个问题:
假如你想从你的人际关系中找一个卖芒果的人?该怎么找呢?
//图的数据我们通过散列表来存储
const graph = {};
//首先定义一个你对应的人际关系图
graph["you"] = ["alice","bob","claire"];
graph["alice"] = ["peggy"];
graph["bob"] = ["anuj","peggy"];
graph["claire"] = ["thom","jonny"];
graph["peggy"] = [];
graph["anuj"] = [];
graph["thom"] = [];
graph["jonny"] = [];
//现在我们已经存储了图的数据--假如我们需要找的人名字中包含了m
const search=(name)=>{
//1.首先我们从第一层里找,每一次把对应的关系压入队列中,
let search_queue = [];
let has_search_arr = [];//记录已经查过的人
search_queue = search_queue.concat(graph[name]);
while (search_queue.length>0){//如果这个队列有值的话
let person = search_queue.shift(); //取第一个元素
if(person.indexOf("m")!== -1){//
return person;
}else{
let value = graph[person];
search_queue = search_queue.concat(value);
has_search_arr.push(person);
}
}
return -1;
}
console.log(search("you"))
//thom
7.学习迪克斯特拉算法
迪克斯特拉算法只能计算权重的正直,补不能计算负值。
迪克斯特拉算法
这个迪克斯特拉算法和广度优先搜索不同,广度优先搜索是查询两点之间的最短路劲,也就是边数最少。而迪克斯特拉算法则是计算的两个结点之间的权重最少。但是迪克斯特拉算法只能计算权重为正时的图,如果图中包含边为负的,就不能用了,而是使用贝尔曼-福德算法。

下面我们详细描述一下怎么使用这个算法。上面这张图就是有向图,其中每一个数字代表了分钟,为了找到最短路劲,你将要使用迪克斯特拉算法。如果使用广度优先搜索,将找到的是上面的两条边。而实际上最短路劲是2 3 1而不是6 1.
下面我们看一下迪克斯特拉算法的具体步骤:
- 找出最便宜的节点,即可在最短时间内到达的节点。
- 更新该节点的邻居的开销,其含义稍后介绍
- 重复这个过程,知道对图中的每一个节点都这样做了。
- 计算最终路劲。
第一步:
找出最便宜的节点,你从起点出发要去终点,你还不知道要去终点需要多长时间,所以我们假设需要无穷大?我们可以使用一张散列表来保存这些记录。
| 节点 | 耗时 |
|---|---|
| A | 6 |
| B | 2 |
| 终点 | 无穷大 |
为什么要这样假设,这样我们在后面找到具体数值的时候就可以直接和我们一开始假设的比较了呀,比较以后发现比无穷大小,就更新。
现在我们从起点出发,找出最便宜的节点,发现到达A是6分钟,而到达B是2分钟,所以我们选择节点B.
第二步:
计算经节点B前往其各个节点需要的时间。
通过计算 通过节点B到达其他节点的时间中,到达A节点的时间要少于原来的6分钟。
现在我们更新其开销,从6分钟变成5分钟。
同时我们找到了终点,并且发现到达终点的开下是7分钟,它要比无穷大小多了,所以我们更新它的开销。现在我们的表变成了下面这样。
| 节点 | 耗时 |
|---|---|
| A | 5 |
| B | 2 |
| 终点 | 7 |
第三步:重复
重复第一步:找出可在最短时间前往的节点。你对节点B执行了第一步,发现可以最短时间内前往的节点是A,6分钟
重复第二步:更新节点A的所有邻居的开销。也就是经结点A到达其他节点所需要的开销,接着你就发现,通过节点A到达终点的时间是6分钟。更新之。这个时候你就已经知道了最短路劲。
为什么不是7分钟,因为我们之前就已经更新了到达节点A的最短路劲是5分钟,所以我们可以直接从这个。
第四步:计算最终路劲
实际上你在第三步重复的过程中不断更新其到达最终路劲的时间的过程中,就是在不断计算计算最终路劲,知道你找到最短的那条。
下面我们用代码来实现这个过程。
/**
* Created by feiyu on 2020/2/11.
* 千里之行,始于足下
*
* 迪克斯特拉算法
*
* 1.要实现这个算法我们需要三个散列表,
* 2.我们需要实现这个图,也可以使用散列表来实现
*/
//1.首先我们定义一个散列表
const graph = {};
//接着我们定义起点,那起点有两个邻居节点是A和B,A和B他们两个节点有各自对应的权重,
graph["start"] = {};
//接着它有两个邻居
graph["start"]["A"] = 6;
graph["start"]["B"] = 2;
//节点A
graph["A"]={};
graph["A"]["end"] = 1;
//节点B
graph["B"]={};
graph["B"]["A"] = 3;
graph["B"]["end"] = 5;
//节点终点
graph["end"]={};//它没有数据
//2.我们创建一个散列表来保存每个结点的开销。
const costs = {};
costs["A"] = 6;
costs["B"] = 2;
costs["end"] = Infinity; //设置一个无穷大的值
//3.我们创建一个散列表来保存节点的父节点--用来记录最新的数据
const parents={};
parents["A"] = "start";
parents["B"] = "start";
parents["end"] = "";
//4.定义一些变量--
const processed = [];//用于保存已经处理过的节点。
//5.建立一个寻找最短路劲节点的函数
const find_lowest_cost_node=(cost_data)=>{
let lowest_cost = Infinity; //建立一个超大的数,然后和它比较
let lowest_cost_node = null;
Object.keys(cost_data).forEach((key)=>{
let cost = cost_data[key];
if(cost < lowest_cost && !processed.includes(key)){
lowest_cost = cost;
lowest_cost_node = key;
}
})
return lowest_cost_node;
}
//6.实现迪克斯特拉算法
const DikstraAlgorithm =()=>{
//第一步:找到最短路劲的节点
console.log(costs)
let node = find_lowest_cost_node(costs);
while (node){
let cost = costs[node]; //拿到这个最短路劲的值
let neighbors = graph[node];//拿到这个节点的邻居
for(let n of Object.keys(neighbors)){
let new_cost = cost + neighbors[n];//当前节点的值加上到达该邻居节点的值,就是图中起点到B再到Ad 值。
if(costs[n] > new_cost){ //如果这样走比直接到这个节点更近,就更新它
costs[n] = new_cost;
parents[n] = node;
}
}
processed.push(node); //添加到数据里用来判断是否已处理
node = find_lowest_cost_node(costs);//获取最短节点
}
console.log("costs==",costs);
console.log("parents==",parents);
}
DikstraAlgorithm();
//执行结果:
//costs== { A: 5, B: 2, end: 6 }
//parents== { A: 'B', B: 'start', end: 'A' }
通过执行结果我们可以看到,找到最短路劲 6,最短路劲的点.
8.贪婪算法
贪婪算法非常有意思,而且也非常简单。
假如有一天你爸爸拿出一塔钱,他们是无序的,说让你抽6张,你想要拿到最多的钱,怎么办呢?
一种是把钱整理一下从大到小,然后去前面的6张。这一种可行,另一种就是贪婪算法,我只要拿到这一堆钱里最大的那张,抽出来,接着我继续从这堆钱里找到最大的那张,继续抽出来,重复6次,你就拿到了最多的钱。
贪婪算法的意思非常简单:每步都采取最优的做法。
在上面的例子中,你每一次都拿最大的那张,你的每一步操作都是局部最优解,最终得到的就是全局最优解。
//你爸爸给你准备的钱
const money = [100,50,100,20,10,5,1,100,5,50,50,20];
//建立个函数来遍历获取最大值
const getMaxMoney=(array)=>{
if(array.length>0){
let max_index = 0;
let max_value = array[0];
for(let i = 1;i{
//定义一个数组来保存钱
let most_array = [];
for(let i = 0;i 这个代码不就是选择排序吗?原来选择排序就是贪婪算法,每一次选择最大的,然后把它放到另一个数组里。
局部最优解就是全局最优解,但是有些情况下并不是完全准确,但是已经非常接近了,在书中举了另外一个例子:
一个小偷拿着一个大包去一个商品店里偷东西,这个大包能放下35个单位的商品,同样你可以采用贪婪策略:
- 盗窃可装入背包的最贵商品;
- 再盗窃还可以装入背包的最贵商品,以此类推。
现在有以下三个商品:
- 音响 3000美元 30磅
- 笔记本电脑 2000美元 20磅
- 吉他 1500美元 15磅
按照贪婪算法,我们可以得出放入音响,可是实际上笔记本电脑和吉他两个加起来3500实际上更多。
所以在这里,贪婪算法虽然不是最优解,但是却非常接近。而它给我们的启示:
有时候完美是优秀的敌人,有时候,你只需要找到一个能够大致解决问题的算法,此时贪婪算法正好派上用场,因为它们实现起来很容易,得到的结果也非常接近。
9:动态规划
学习动态规划这一章看了有两遍,它是用解决小问题的方式来解决大问题。从小问题着手,来解决大问题。非常有智慧。文章内容来至算法图解。
动态规划
总结书中的结论:
- 需要在给定约束条件下优化某种指标时,动态规划很有用
- 问题可分解为离散子问题,可使用动态规划来解决
- 每种动态规划解决方案都涉及网格
- 单元格中的值通常就是你要优化的值
- 每个单元格都是一个子问题,因此你需要考虑如何将问题分解为子问题
- 没有放之四海皆准的计算动态规划解决方案的公式
那么面对一个动态规划问题,如何开始呢?哦,你好厉害,你居然已经知道了这是一个动态规划问题了。
这个时候可以使用费曼算法来开始,它有以下三个步骤:
- 将问题写下来。
- 好好思考。
- 将答案写下来。
那么我们开始吧.
首先,问题是:你有一个4格的包包(参考魔兽世界),你要拿它去偷东西,现在有三样东西:
- 音响 2000块钱 占3个背包
- 笔记本电脑 3000块钱 站4个背包
- 吉他 1500块钱 占1个背包
怎么偷价值最大?
使用动态规划来解决这个问题,你需要回答自己三个问题:
1.单元格中的值是什么?
单元格中的值是一格包包能放下的最大值
2.如何将这个问题划分为子问题?
寻找这个包包能放下的最大值
3.网格的坐标轴是什么呢?
横坐标是 1,2,3,4
纵坐标是 从小到大 吉他 笔记本 音响
现在你就拿一张白纸,画一张表格。
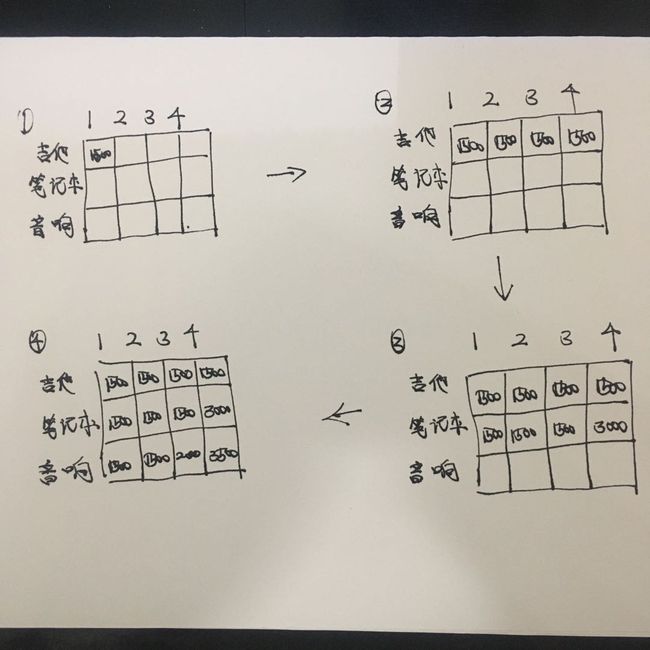
从第一张开始:
- 假设我们现在只有一种商品就是吉他,那么一格包包能放下的最大价值就是吉他,1500.
然后2格包包也是,假设我们每种商品只能偷一个。那么3和4 格包包都一样了。
现在我们多了一种选择,那就是笔记本,它占4格,价值3000,按照前面的推理,1格包包是1500,2格包包是1500,到4格包包的时候,我们终于变成了3000.
- 现在我们又多了一种选择,音响,它占3格,价值2000,按照前面的推理,1格是1500,2格是1500,放不下,3格的时候能放下音响了,更新3格的背包为2000
接着就是最最关键的一步。4格包包的时候,我们发现原来是3000,而有了新的选择音响以后,3格的最新值是2000,而对于4格包包来说,还剩余一格,那么一格的最大值是多少呢? 是1500,所以是两者相加就是3500.
用它和原来的3000想必,发现它更大,更新之。
到这里你就已经知道了该怎么偷了。
而实际上我们计算每一格包包都是像最后一个包包来计算的。
这是算法图解的最后一篇文章,在这篇文章的最后一章中,书中提到了10种没有详细介绍的算法:
- 树:B树,红黑树,堆,伸展树
- 反向索引
- 傅里叶变换
- 并行算法
- MapReduce-分布式算法-归并函数
- 布隆过滤器和HyperLogLog
- SHA算法
- Diffie-Hellman密钥交换
- 线性规划
提供了10种你可能感兴趣的算法。最后列举一句书中的话:
最佳的学习方式是找到感兴趣的主题,然后一头扎进去
over...