任务:
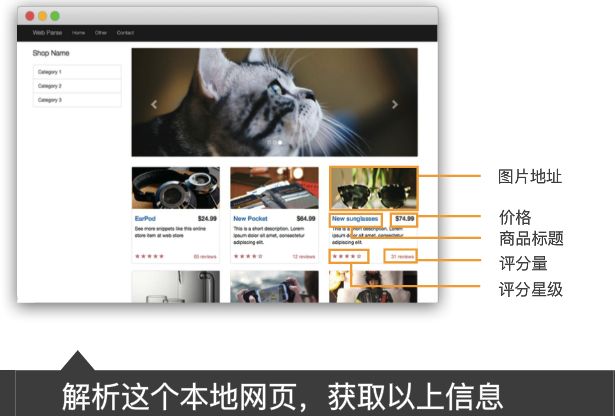
Snip20170521_5.png
成果:
{'Title': 'EarPod', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0000_073a9256d9624c92a05dc680fc28865f.jpg', 'GradeStar': 5, 'Price': '$24.99', 'GradeNum': '65'}
{'Title': 'New Pocket', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0005_828148335519990171_c234285520ff.jpg', 'GradeStar': 4, 'Price': '$64.99', 'GradeNum': '12'}
{'Title': 'New sunglasses', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0006_949802399717918904_339a16e02268.jpg', 'GradeStar': 4, 'Price': '$74.99', 'GradeNum': '31'}
{'Title': 'Art Cup', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0008_975641865984412951_ade7a767cfc8.jpg', 'GradeStar': 3, 'Price': '$84.99', 'GradeNum': '6'}
{'Title': 'iphone gamepad', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0001_160243060888837960_1c3bcd26f5fe.jpg', 'GradeStar': 4, 'Price': '$94.99', 'GradeNum': '18'}
{'Title': 'Best Bed', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0002_556261037783915561_bf22b24b9e4e.jpg', 'GradeStar': 4, 'Price': '$214.5', 'GradeNum': '18'}
{'Title': 'iWatch', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0011_1032030741401174813_4e43d182fce7.jpg', 'GradeStar': 4, 'Price': '$500', 'GradeNum': '35'}
{'Title': 'Park tickets', 'PicLink': 'http://localhost:63342/1_2/1_2answer_of_homework/img/pic_0010_1027323963916688311_09cc2d7648d9.jpg', 'GradeStar': 4, 'Price': '$15.5', 'GradeNum': '8'}
代码:
from bs4 import BeautifulSoup
path = './index.html'
url = 'http://localhost:63342/1_2/1_2answer_of_homework/'
with open(path,'r')as f:
soup = BeautifulSoup(f.read(),'lxml')
PicLinks = soup.select('body > div > div > div.col-md-9 > div > div > div > img')
Prices = soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4.pull-right')
Titles = soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4 > a')
GradeNums = soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p.pull-right')
GradeStars = soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p')
#使用函数对数据进行分割并统计星星数量
def GetStar (GradeStar):
a = str(GradeStar) #将数据类型转换成字符串
b = a.split('\"') #按双引号规则进行分割
num = 0 #设定起始星星数
for c in b:
if c == 'glyphicon glyphicon-star':
num += 1
return num
for PicLink,Price,Title,GradeNum,GradeStar in zip(PicLinks,Prices,Titles,GradeNums,GradeStars[1::2]): #通过GradeStars[1::2]筛选出奇数列数据
data = {
'PicLink': url + PicLink.get('src'),
'Price': Price.get_text(),
'Title': Title.get_text(),
'GradeNum': GradeNum.get_text().split()[0], #采用split方法去除reviews,取数字部分
'GradeStar':GetStar(GradeStar)
}
print(data)
星星统计思路:
第一步对获取的数据列表按奇数进行遍历;
第二步对遍历的数据进行分割;
第三步对分割的数据进行比对,同时进行计数