时序模式是数据挖掘中的第四种应用类别。
时序模式是基于时间序列的历史数据,来预测未来短期内的可能值。
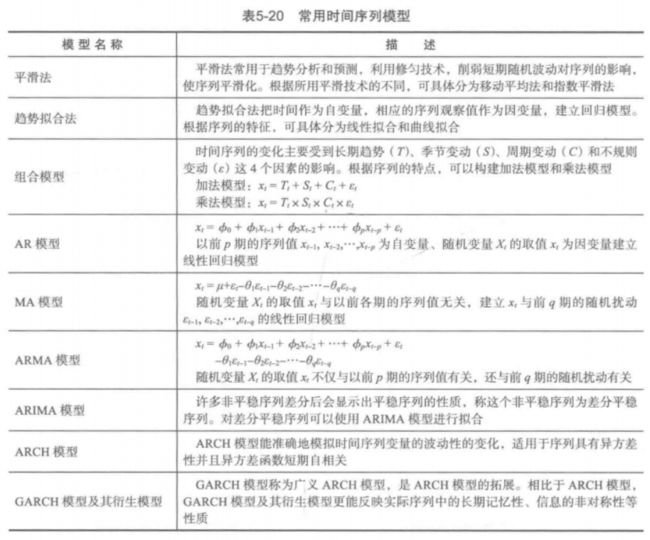
1. 时间序列的预处理
拿到一个观察值序列后,首先要对它的纯随机性和平稳性进行检验,这两个重要的检验称为序列的预处理。根据检验结果可以将序列分为不同类型,对不同类型的序列采用不同的分析方法。
对于纯随机序列,又称为白噪声序列,序列的各项之间没有任何相关关系。序列在进行完全无序的随机波动,可以终止对该序列的分析。因为白噪声序列是没有信息可以提取的平稳序列。
对于平稳非白噪声序列,它的均值和方差是常数,现有一套非常成熟的平稳序列的建模方法,通常是建立一个线性模型来拟合该序列,ARMA模型是最常用的平稳序列拟合模型。
对于非平稳序列,它的均值和方差不稳定。处理方法一般是将其转变为平稳序列。这样就可以应用有关平稳时间序列的分析方法。如果一个时间序列经差分运算后具有平稳性,则该序列为差分平稳序列,可以用ARIMA模型进行分析。
1.1 平稳性检验
对于随机变量X,可以计算其均值和方差,对于两个随机变量X,Y,可以计算其协方差和相关系数,他们度量了两个不同事件之间的相互影响程度。
如何检验某一个序列是否为平稳序列?

具体的检验方法有两种:一种是根据时序图和自相关图的特征做出判断的图检验,该方法操作简单,应用广泛,缺点是带有主观性。另一种是构造检验统计量进行检验,目前最常用的方法是单位根检验。
1.2 纯随机性检验
如果一个序列是纯随机序列,那么它的序列值之间应该没有任何关系,即自相关系数=0,实际上这是一种理论上才会出现的理想状态,实际上纯随机序列的样本自相关系数不会绝对为0,当很接近零,并在0附近随机波动。
纯随机性检验也称为白噪声检验,常用的检验统计量有Q统计量,LB统计量,然后计算出对应的P值,如果P值显著大于显著性水平a,则表示该序列是纯随机性,可以终止对该序列的分析。
2. 平稳时间序列分析
ARMA模型是目前最常用的拟合平稳序列的模型,又可以细分为AR模型,MA模型和ARMA三大类。
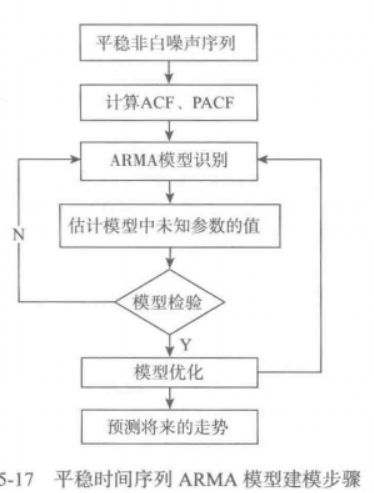
某个时间序列经过预处理后,被判定为平稳非白噪声序列,就可以利用ARMA模型进行建模,计算出该序列的自相关系数和篇自相关系数,再由AP模型,MA和ARMA的自相关系数和偏自相关系数的性质,选择合适的模型。

3. 非平稳时间序列分析
自然界中绝大部分序列都是非平稳的,其分析可以分为确定性因素分解的时序分析和随机时序分析两大类。
确定性因素分解的方法把所有序列的变化都归纳为4个因素(长期因素,季节变动,循环变动和随机波动)的综合影响,其中长期趋势和季节变动的规律性信息通常比较容易提取,而由随机因素导致的波动则非常难确定和分析。
随机时序分析法是为了弥补确定性因素分解方法的不足,可以建立的模型由ARIMA模型,残差自回归模型,季节模型,异方差模型等。
3.1 差分运算
p阶差分:相距1期的两个序列值之间的减法运算称为1阶差分运算。
k步差分:相距k期的两个序列值之间的减法运算称为k步差分运算。
3.2 ARIMA模型
差分运算具有强大的确定性信息提取能力,许多非平稳性差分后会显示出平稳序列的性质,这时称这个非平稳序列为差分平稳序列。这个序列可以用ARMA拟合。ARIMA模型的实质就是差分运算和ARMA模型的组合。
一个案例:
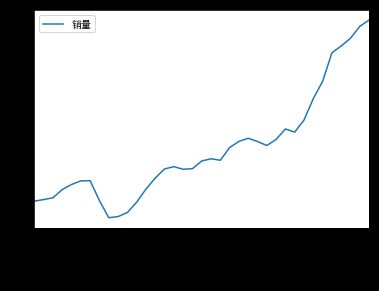
首先判断时序数据是否为平稳性序列:使用时序图,自相关图,自相关系数,p值来判断,比如:
原始序列的时序图为:
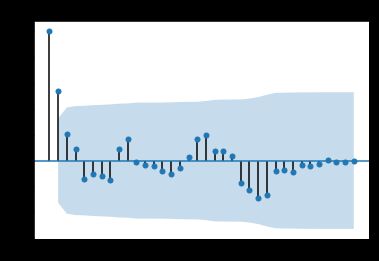
自相关图为:

#自相关图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data).show()
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print('原始序列的ADF检验结果为:', ADF(data['销量']))
#返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore
通过statsmodels的adfuller计算出p值为0.9984.显著大于0.05,表明该序列为非平稳序列。
做一阶差分:
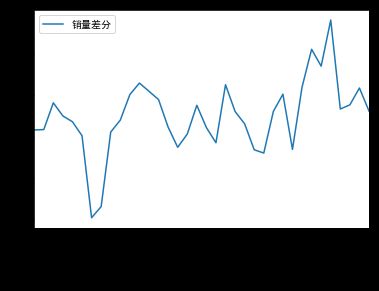
p值为0.0226,小于0.05,故而为平稳序列。
白噪声检验:
p值为0.00077,小于0.05,所以一阶差分后的序列为非白噪声序列。综合为:一阶差分后的序列为平稳非白噪声序列。
故而可以用ARMA模型来拟合。
下面计算ARMA模型中的p,q,当p和q均小于等于3的所有组合的BIC信息量,取其中BIC信息量达到最小的模型阶数。
最终BIC最小的p值和q值为0,1
代码为:
from statsmodels.tsa.arima_model import ARIMA
data[u'销量'] = data[u'销量'].astype(float)
#定阶
pmax = int(len(D_data)/10) #一般阶数不超过length/10
qmax = int(len(D_data)/10) #一般阶数不超过length/10
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(data, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值
p,q = bic_matrix.stack().idxmin() #先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
使用ARIMA模型建模并预测:
model = ARIMA(data, (p,1,q)).fit() #建立ARIMA(0, 1, 1)模型
model.summary2() #给出一份模型报告
model.forecast(5) #作为期5天的预测,返回预测结果、标准误差、置信区间。
array([4873.9665477 , 4923.92261622, 4973.87868474, 5023.83475326,
5073.79082178]
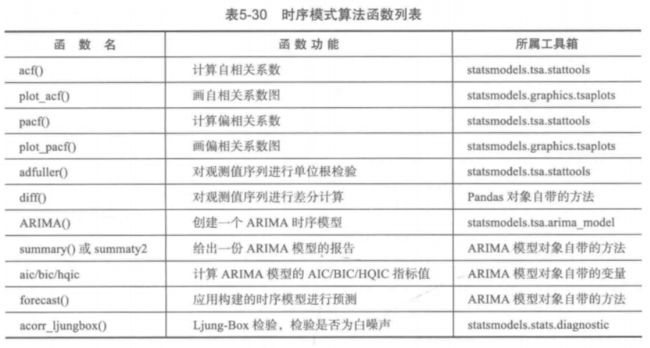
4. 主要时序模式算法
时序模型的库主要是StatsModels,算法主要是ARIMA模型,在使用该模型进行建模时,需要进行一系列判别操作,主要包括平稳性检验,白噪声检验,是否差分,AIC和BIC指标值,模型定阶最后再做预测。
参考资料:
《Python数据分析和挖掘实战》张良均等