注意:本文使用Docker 搭建普通版的Hadoop集群,Docker基础使用以及命令请自行百度,后续会更新高可用的Hadoop集群搭建、
1.在宿主机上下载好安装包:hadoop-2.8.2.tar.gz ; jdk1.8共两个包
2.在Docker仓库中拉去镜像
命令:docker pull 镜像名:Tag //拉取镜像

3.创建容器
命令:
//以镜像centos:centos6来创建名字为 centos6_java的容器 并在后台运行{-d:后台运行参数}
docker -i -t -d --name centos6_java centos:centos6

4.安装java1.8
1.从宿主机拷贝jdk到容器中

2.进入后台运行的容器中
命令:docker exec -it centos6_java bash

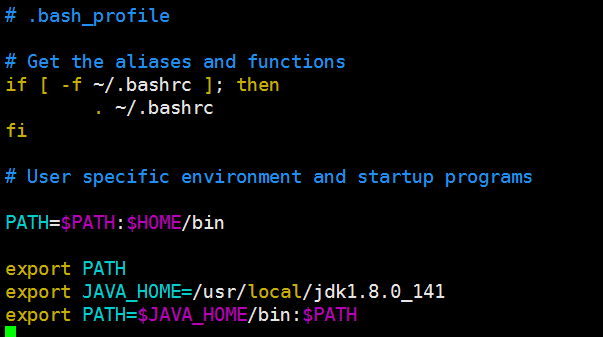
3.找到上传的jdk解压并配置环境变量(配置在/etc/profile):
4.把容器转变为不可变得镜像
此时我们已经配置好了一个具有java环境的容器,可以将其保存为一个镜像,镜像名字为centos6_java:1.8,注意保存的镜像格式 必须为【imageName:Tag】

5.创建Hadoop容器
1. 以刚保存好的java镜像来创建新的容器来安装hadoop

2.将宿主机上的hadoop压缩包传到容器的 /usr/local目录下,并在容器中解压hadoop压缩包
6.配置Hadoop
配置文件都在hadoop-2.8.2/etc/hadoop目录下
首先创建三个文件:
1. mkdir -p /data/tmp #hadoop临时目录
2. mkdir -p /data/hdfs/name #NameNode的存放目录
3. mkdir -p /data/hdfs/data #DataNode的存放目录
1).core-site.xml配置
注意了:hdfs://master:9000,指向的是一个Master节点的主机,此时还未配置,后续做集群配置时再配置
2).hdfs-site.xml配置
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
3).mapred-site.xml配置
at. If "local", then jobs are run in-process as a single map
and reduce task.
4)修改hadoop-env.sh文件
在最下方添加java环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_141
5).格式化namenode
执行命令:hadoop namenode -format,如果命令不存在,执行source /etc/profile,在执行hadoop namenode -format
7.提交容器:
commit centos6_hadoop centos6_hadoop:2.8.2
8.Hadoop集群搭建
用已经创建好的centos6_hadoop:2.8.2 的hadoop镜像来搭建集群
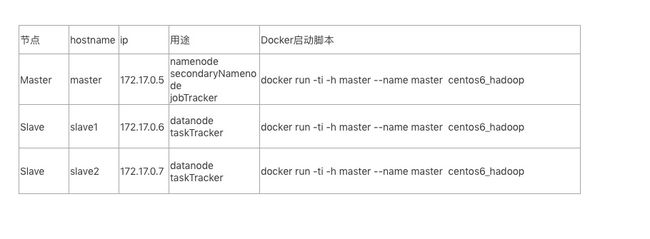
我们所要搭建的集群是一个master节点和两个slave
注意:
Docker容器中的ip地址是启动之后自动分配的,且不能手动更改;hostname、hosts配置在容器内修改了,只能在本次容器生命周期内有效。如果容器退出了,重新启动,这两个配置将被还原。且这两个配置无法通过commit命令写入镜像
1)用创建好的hadoop镜像来创建上图中的master,slave1,slave2三个节点
执行如下命令
docker run -it -h master --name master centos6_hadoop:2.8.2 #创建master节点
docker run -it -h slave1 --name slave1 centos6_hadoop:2.8.2 #创建slave1节点
docker run -it -h slave2 --name slave2 centos6_hadoop:2.8.2 #创建slave2节点
此时以交互式命令创建容器,如果想让容器以后台模式运行有两种方法:
1、在容器中 Ctrl + P + Q 退出容器保持后台运行(按住ctrl和P 再按Q)
2、创建容器时加入 -d 参数
2)配置三个容器的hosts
获取各个节点ip,然后vim /etc/hosts,我的配置如下。
172.17.0.5 master
172.17.0.6 slave
172.17.0.7 slave2
3)配置salve (前面遗留下的未配置项)
在master 容器中 编辑 slaves文件,slaves文件 在hadoop目录下的/etc/hadoop路径下
添加
slave1
slave2
4)配置SSH免密登录
在master 容器中执行:
1. cd ~/
2.ssh-keygen
3.ssh-copy-id -i .ssh/id_rsa.pub [email protected] #复制公钥到其他节点
ssh-copy-id -i .ssh/id_rsa.pub [email protected] #复制公钥到其他节点
ssh-copy-id -i .ssh/id_rsa.pub [email protected] #复制公钥到其他节点
9.启动Hadoop集群
在每个容器中先执行:source /etc/profile
在master容器中执行 start-all.sh
在Master容器中执行jps:
1131 Jps
492 SecondaryNameNode
513 NameNode
1240 ResourceManager
在slave1容器中执行jps:
268 NodeManager
342 Jps
149 DataNode
在slave2容器中执行jps:
371 Jps
247 NodeManager
176 DataNode