这几天看了一篇名为《大前端开发者需要了解的基础编译原理和语言知识》,读完之后深感作者知识面之广,内容之丰富,感谢作者分享如此高质量的文章。
同时,鉴于文章内容较多,自己写下这篇文章,作为心得和笔记。
代码的编译过程往粗了说分为四个阶段:1.预处理(preprocessing)2.编译(compliation)3.汇编(assembly)4.链接(linking)。
往细了说分为七个阶段:1.预处理、2.词法分析、3.语法分析、4.生成中间代码、5.生成目标代码、6.汇编、7.链接。
这里面的主要区别就是编译包括了词法分析、语法分析、生成中间代码和生成目标代码四个部分。
编译器负责预处理、词法分析、语法分析、生成中间代码和生成目标代码五个步骤,编译器的输入是源代码,输出是中间代码。编译器以中间代码为分界又分为编译器前端和编译器后端。编译器前端负责语法分析生成抽象语法树(AST,Abstract Syntax Tree),后端负责将抽象语法树转换为中间代码。
ps:中间代码已经非常接近于实际的汇编代码,它几乎可以直接被转化。主要的工作量在于兼容各种 CPU 以及填写模板。此工作由编译器或汇编器完成。
主流的C/C++的编译器有GCC,这是GNU发布的一款极具影响力的编译器,已经成为Linux和Unix系统的默认编译器。从事iOS开发使用的Xcode目前用的编译器是clang+LLVM。Xcode4之前,用的是GCC编译器,由于GCC对Objective-C的支持不是很好,于是苹果采用了“自家”发起的clang+LLVM作为默认编译器。
这两个编译器的主要区别是GCC直接负责整个编译过程的五个步骤,而clang+LLVM将编译的步骤拆分,clang作为编译器前端(还记得编译器前端的职责么?),LLVM作为编译器的后端两者配合使用。当然历时上也曾经出现过,GCC作为编译器前端,LLVM作为编译器后端的搭配组合。

接下来就以细分的模块为例,总结一下每个模块由什么负责,分别都做了哪些工作。
1.预处理(preprocessing) —— 处理宏定义
预处理主要是处理一些宏定义,比如:#define、#include、**#if **等。预处理的实现有很多种,有的编译器会在词法分析前先进行预处理,替换掉所有 # 开头的宏,而有的编译器则是在词法分析的过程中进行预处理。当分析到 # 开头的单词时才进行替换。虽然先预处理再词法分析比较符合直觉,但在实际使用中,GCC 使用的却是一边词法分析,一边预处理的方案。(以上这些内容是我从《大前端开发者需要了解的基础编译原理和语言知识》直接粘贴过来的)
2.词法分析 —— 输出符号状态
词法分析的主要实现原理是状态机,它逐个读取字符,然后根据读到的字符的特点转换状态。计算机不像人类可以直接识别源代码的内容,它只能一个一个的识别每个单词,词法分析要做的就是把源代码分割开,形成若干个单词,并标记状态为语法分析做准备。比如,a=1” 和 “a==1”,这两个语句,计算机在从左向右识别时,识别到第一个 “=” 时并不能判定该语句是赋值符号还是条件判断符号,必须结合 “=” 之后的字符才能做出正确的判断,若是 “1” 则是赋值符号,若是 “=” 则是条件判断符号,根据识别的不同结果,进行状态标记。具体的案例在原文中讲的很详细,各位读者可以参考。

3.语法分析 —— 输出抽象语法树(AST, Abstract Syntax Tree)
词法分析以后,编译器已经知道了每个单词的意思,但这些单词组合起来表示的语法还不清楚,这时需要编译器前端(如:GCC或者clang)进行语法分析。
实现语法分析的一个简单的思路是模板匹配,即将编程语言的基本语法规则抽象成模板进行匹配,符合相应的模板,即对应相应的意思,同时生成抽象语法树(AST, Abstract Syntax Tree)。
比如有 “int a = 10;” 语句,其实表示了这么一种通用的语法格式:
“类型 变量名 = 常量;”。
而在成功解析语法以后,我们会得到抽象语法树(AST: Abstract Syntax Tree)。
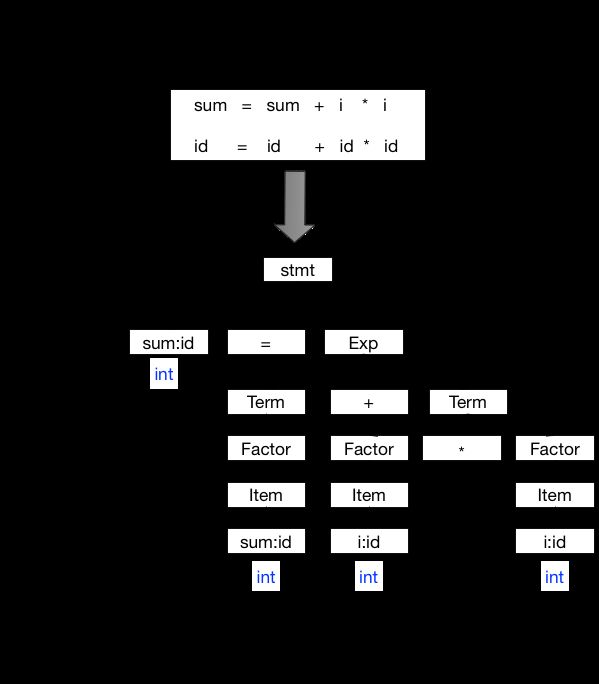
以这段代码为例:
int fun(int a, int b) {
int c = 0;
c = a + b;
return c;
}
它的语法树如下:

语法树将字符串格式的源代码转化为树状的数据结构,更容易被计算机理解和处理。
4.生成中间代码IR(Intermeidate Representation)
其实抽象语法树可以直接转化为目标代码(汇编代码)。然而,不同的 CPU 的汇编语法并不一致,比如《AT&T与Intel汇编风格比较》这篇文章所提到的,Intel 架构和 AT&T 架构的汇编码中,源操作数和目标操作数位置恰好相反。Intel 架构下操作数和立即数没有前缀但** AT&T 架构有。因此一种比较高效的做法是先生成语言无关,CPU 也无关的中间代码(IR)**,然后再生成对应各个 **CPU **的汇编代码。
生成中间代码(IR,Intermediate Representation)是非常重要的一步,一方面它和语言无关,也和 CPU 与具体实现无关。可以理解为中间代码是一种非常抽象,又非常普适的代码。它客观中立的描述了代码要做的事情,如果用中文、英文来分别表示** C 和 Java 的话,中间码某种意义上可以被理解为世界语**。
另一方面,中间码是编译器前端和后端的分界线。编译器前端负责把源码转换成中间代码(IR),编译器后端负责把中间码转换成目标代码(汇编代码)。
抽象语法树生成中间码(IR)的过程大体上分为两步,第一步是生成中间码(IR),第二步是将中间码(IR)最佳化。

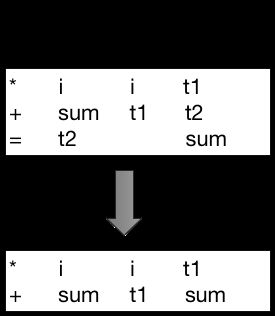
以** GCC** 为例,生成中间代码可以分为三个步骤:(
1.语法树转高端 gimple
2.高端 gimple 转低端 gimple
3.低端 gimple 经过 cfa 转 ssa 再转中间代码
注:使用Xcode 进行iOS 客户端开发时,LLVM 负责将抽象语法树转为中间码(IR)。
** Gimple** 是GCC编译器产生的一种包含最多三个操作数的中间指令,也就是编译原理里讲的四元码(三个操作数,一个操作符),基本上也就是 dst = src1 @ src2 的这种形式。由于** Gimple** 最多只能对两个操作数进行计算,因此一个复杂的表达式会展开为一系列的** Gimple** 指令,这一过程就是** Gimple** 化。
4.1 语法树转高端 Gimple
语法树转高端 Gimple,主要是处理寄存器和栈,比如:“ c = a + b” 并没有直接的汇编代码与之对应,一般来说需要把 a + b 的结果保存到寄存器中,然后再把寄存器赋值给 c。另外,调用一个新的函数时会进入到函数自己的栈,建栈的操作也需要在 Gimple 中声明。
4.2 高端 Gimple转低端Gimple
高端 Gimple转低端 Gimple,主要是把变量定义,语句执行和返回语句区分存储,分配栈空间。
比如:
int a = 1;
a++;
int b = 1;
会被处理成:
int a = 1;
int b = 1;
a++;
这样做的好处是很容易计算一个函数到底需要多少栈空间。
此外,return 语句会被统一处理,放在函数的末尾,比如:
if (1 > 0) {
return 1;
}
else {
return 0;
}
会被处理成:
if (1 > 0) {
goto a;
}
else {
goto b;
}
a:
return 1;
b:
return 0;
4.3 低端Gimple转中间代码
这一步主要是进行各种优化,添加版本号等。
5.生成目标代码(汇编代码)
目标代码也可以叫做汇编代码。由于中间码已经非常接近于实际的汇编代码,它几乎可以直接被转化。主要的工作量在于针对不同的CPU生成不同的汇编代码,兼容各种 CPU 以及填写模板。在最终生成的汇编代码中,不仅有汇编命令,也有一些对文件的说明。

6.汇编(assembly)——汇编器生成二进制机器码
汇编器会接收汇编代码,将它转换成二进制的机器码,生成目标文件(后缀是 .o),机器码可以直接被 CPU 识别并执行。由于目标代码是分段的,最终的目标文件(机器码)也是分段的。这是因为:
- 数据和代码区分开。其中代码只读,数据可写,方便权限管理,避免指令被改写,提高安全性。
- 现代 CPU 一般有自己的数据缓存和指令缓存,区分存储有助于提高缓存命中率。
- 当多个进程同时运行时,他们的指令可以被共享,这样能节省内存。
7.链接(linking)
链接就是将目标文件(.o文件)与其中调用的外部函数所在的目标文件通过重定位关联起来。
在一个目标文件中,不可能所有变量和函数都定义在文件内部。比如** strlen 函数就是一个被调用的外部函数,此时就需要把 main.o 这个目标文件和包含了 strlen 函数实现的目标文件链接起来。我们知道函数调用对应到汇编其实是 jump 指令,后面写上被调用函数的地址,但在生成 main.o 的过程中, strlen() 函数的地址并不知道,所以只能先用 0 来代替,直到最后链接**时,才会修改成真实的地址。
链接器就是靠着重定位表来知道哪些地方需要被重定位的。每个可能存在重定位的段都会有对应的重定位表。在链接阶段,链接器会根据重定位表中,需要重定位的内容,去别的目标文件中找到地址并进行重定位。
有时候我们还会听到动态链接这个名词,它表示重定位发生在运行时而非编译后。动态链接可以节省内存,但也会带来加载的性能问题,这里不详细解释,感兴趣的读者可以阅读《程序员的自我修养》这本书。(以上是从《大前端开发者需要了解的基础编译原理和语言知识》直接粘贴过来的)
写在最后
最后十分感谢《大前端开发者需要了解的基础编译原理和语言知识》的作者能够贡献如此高质量的一篇文章,讲清楚了整个编译过程中的细节。本文有大量内容是直接从该文章中复制过来,最终的版权归原作者所有,本人只是作为一个读后笔记写下本文,若有侵权的地方,烦请告知。
参考文献
- https://mp.weixin.qq.com/s?__biz=MzI0NzI1NzU5NA%3D%3D&mid=2247483740&idx=1&sn=ed505ededdbb970a9094b34c829f25d5&scene=45#wechat_redirect
- http://sp1.wikidot.com/gccpcode
- https://www.slideshare.net/ccckmit/8-73472916?from_action=save