Selenium的Webdriver爬取动态网页效果虽然不错,但效率方面并不如人意。最近一直研究如何提高动态页面爬虫的效率,方法无非高并发和分布式两种。过程中有很多收获,也踩了不少坑,在此一并做个总结。以下大致是这段时间的学习路线。
一、 Scrapy+phantomJS
Scrapy是一个高效的异步爬虫框架,使用比较广泛,文档也很完备,开发人员能快速地实现高性能爬虫。关于Scrapy的基本使用这里就不再赘述了, 这篇Scrapy读书笔记挺不错的。然而Scrapy在默认的情况下只能获取静态的网页内容,因此必须进一步定制开发。
Scrapy结合phantomJS似乎是个不错的选择。phantomJS是一个没有页面的浏览器,能渲染动态页面并且相对轻量。因此,我们需要修改Scrapy的网页请求模块,让phantomJS请求网页,以达到获取动态网页的目的。一番调研之后,发现大致有三种定制方法:
1. 每个url请求两次。在回调函数中舍弃掉返回的response内容,然后用phantomJS再次请求response.url,这次的请求由于没有构造Request对象,当然就没有回调函数了,然后阻塞等待结果返回即可。这个方法会对同一个url请求两次,第一次是Scrapy默认的HTTP请求,第二次则是phantomJS的请求,当然第二次获取到的就是动态网页了。这个方法比较适合快速实现小规模动态爬虫,在默认的Scrapy项目基础上,只需要简单修改回调函数就可以了。
2. 自定义下载中间件(downloadMiddleware)。downloadMiddleware对从scheduler送来的Request对象在请求之前进行预处理,可以实现添加headers,user_agent,还有cookie等功能 。但也可以通过中间件直接返回HtmlResponse对象,略过请求的模块,直接扔给response的回调函数处理。代码如下:
class CustomMetaMiddleware(object):
def process_request(self,request,spider):
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.loadImages"] = False
dcap["phantomjs.page.settings.resourceTimeout"] = 10
driver = webdriver.PhantomJS("E:xx\xx\xx",desired_capabilities=dcap)
driver.get(request.url)
body = driver.page_source.encode('utf8')
url = driver.current_url
driver.quit()
return HtmlResponse(request.url,body=body)
改完代码后,记得修改settings配置。但这个方法有个很大的问题——不能实现异步爬取。由于直接在下载中间件中请求网页,而Scrapy在这里却不是异步的,只能实现阻塞式的逐个网页下载。当然,如果不追求高并发的话,这也是个快速部署动态爬虫的方法。
3.自定义downloader。downloader是Scrapy发起HTTP请求的模块,这模块实现了异步请求,因此自定义downloader是最完美的实现。但是要编写一个自定义的downloader比较麻烦,必须按照Twisted的一些规范,所幸网上有一些开源的downloader,在这基础上改改就比较容易了。 这篇文章详解了downloader的开发,非常不错!
一些坑和心得
通过代码运行Scrapy是个很有用的方法,即通过
CrawlerProcess类运行爬虫,但是给Spider传递settings参数却是一个很大的坑,这个问题绕了我很长时间,最后的解决方法是修改PYTHONPATH和SCRAPY_SETTINGS_MODULE环境变量,加上爬虫项目的目录,这样Python才能找到配置文件。设置
DOWNLOAD_TIMEOUT选项,其默认值是180秒,相对较长,可以设置得短一些提高效率。PhantomJS对多进程的支持极不稳定。具体表现在如果一主机同时开了多个phantomJS进程,单个phantomJS运行结果就会时好时坏,经常出现一些莫名其妙的报错,官方git的issue上也提到phantomJS对多进程的支持很不好。如果真要多进程爬虫的话,推荐chromedriver。
Scrapy的优势在于高效的异步请求框架,由于其本身并不支持动态页面爬取,如果对爬虫的效率没有特别高的要求,也没有必要一定用这个框架,毕竟熟悉框架要一定的时间成本,在框架下编程限制也比较多,对一些比较简单的爬虫,有时还不如自己手撸一个。
二、 Scrapy-splash
由于phantomJS的多并发短板,Scrapy+phantomJS的效率受限,因此,这并不是一个特别好的选择。
又一番调研后,发现splash似乎是个不错的选择。Splash是一个Javascript渲染服务。它是用Python实现的,同时使用了Twisted和QT,并且实现了HTTP API的轻量浏览器,Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。
在Scrapy中使用splash也很简单,详见http://www.cnblogs.com/zhonghuasong/p/5976003.html 。
一般来说,在Scrapy中只需要返回一个SplashRequest对象即可。比如:
yield SplashRequest(url='http://'+url,callback=self.parse,endpoint='render.html',
args={'wait':2},errback=self.errback_fun, meta={ })
同样也可以返回带POST参数的Request对象。更简单地,用urllib等库构造POST请求也没问题,因为这本质上是一个端口代理,可以接受任何的HTTP请求。
splash的内存占用相对较少,但多并发仍然会出现些问题,请求的失败率会大大提高,页面渲染结果偶尔会出现一些问题,同时受制于服务器主机的带宽,速度受限,但总体表现不错,足以应对小规模的动态爬虫。
Splash的优点也很显著,通过HTTP API,其他分布式节点能很容易地获得动态页面,并且使得服务器和其他节点之间的耦合降到了最低,扩展变得特别方便。另外,分布式节点不用配置环境就能获得动态页面,相对phantomJS复杂的配置来说简单太多了!如果想简单地实现动态页面爬虫,splash是一个非常好的选择,但受制于单个服务器带宽,速度有限,并且有时渲染效果不是很理想。
三、 chromedriver并发
无论phantomJS还是splash,稳定性是一方面,在渲染效果和速度上都不及chromedriver,毕竟V8引擎不是盖的!但chromedriver缺点也很明显——特别耗内存,而且是有界面的!
有段时间为了爬百度搜索结果,我一开始用requests库模拟POST请求,虽然效率没问题,但经常被百度封,于是试着改用phantomJS,当时觉得尽管效率低了点,但毕竟是真正的浏览器,百度应该不会封。后来发现作用也不大,还是经常被封,并且phantomJS自身不太稳定,经常报错,多进程并发更是没办法运行。看来只能试一试chromedriver了。以前一直忌惮于内存杀手chrome(开一个chrome浏览器,任务管理器里就有很多个chrome进程),最后无奈只能祭出这大杀器了。跑了一段时间之后,发现chrome的效率还挺不错,占用的内存也没有想象中的大,多并发支持非常好,在我的电脑上同时开20来个也没问题,稳定性也不错,而且百度居然就没封!(震惊!!!chrome居然自带反反爬虫光环!)。但由于程序主要在阿里云主机上跑,有界面的chromedriver当时便没有考虑在内,前不久才知道原来可以通过引入虚拟界面,让chrome在没有界面的主机上跑.....
Python的pyvirtualdisplay库就能引入虚拟界面。
代码实现也非常简单:
from pyvirtualdisplay import Display
display = Display(visible=0,size=(800,600))
display.start()
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
经个人测试,发现chrome对多进程的支持非常好,渲染速度快,就是内存占用相对较大,可以多进程+分布式提高效率,关键chrome不容易被封。
PS. 常用的chromedriver关闭图片选项代码:
chromeOptions = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images":2}
chromeOptions.add_experimental_option("prefs",prefs)
driver = webdriver.Chrome(chromedriver_path,chrome_options=chromeOptions)
driver.get(url)
四、Selenium Grid
Selenium Grid是Selenium的单机扩展,允许用户将测试案例分布在几台机器上并行执行。当然,能实现分布式测试,分布式爬虫当然没问题。
Selenium Grid的机制如图。首先启动一个中央节点(Hub),然后启动多个远程控制节点(rc),并让rc在Hub上注册自己的信息,包括rc自身的系统、支持的webdriver、最大并发数量等,这样Hub节点就知道了所有的rc信息,方便以后调度。
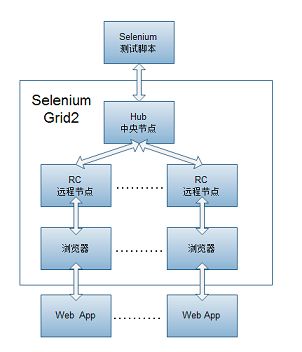
运行环境搭建好之后,测试或爬虫脚本请求Hub的服务端口,Hub主机根据注册的rc节点的当前状态,结合负载均衡原则,将这些测试用例分发到指定的rc节点,rc节点接到命令之后便执行。
from selenium import webdriver
url = "http://localhost:4444/wd/hub"
driver = webdriver.Remote(command_executor = url, desired_capabilities = {'browserName':'chrome'})
driver.get("http://www.baidu.com")
print driver.title
如下图,我在本地建立了一个Hub节点,默认端口是4444,接着用本机注册了两个rc节点,端口分别为5555、6666。通过hub服务端口的控制台可以看到,每个节点可以支持5个Firefox实例、一个IE实例和5个Chrome实例(可以自定义)。由于本机没有安装Opera浏览器,当然也就没有Opera实例了。
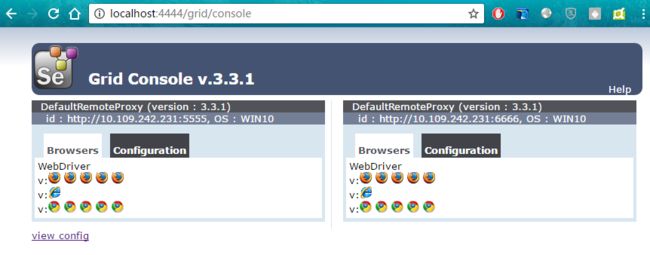
Selenium Grid是个很好的实现分布式测试/动态爬虫的框架,原理和操作也不复杂,有兴趣的同学可以多了解了解。
五、 总结
以上各软件或框架的特点简要如下:
- phantomJS比较轻量,但对多并发支持非常差
- chromedriver渲染速度快,多并发支持较好,但占用内存大
- splash实现了HTTP API,分布式扩展容易,页面渲染能力一般
- Selenium Grid是专业的测试框架,扩展容易,支持负载均衡等高级特性
所以,分布式Scrapy+chromedriver或Selenium Grid是实现分布式动态爬虫较好的选择。