使用线程池的原因
-
无线创建线程的不足
在生产环境中,为每一个任务都分配一个线程这种方法存在一些缺陷:
线程生命周期的开销:线程的创建与销毁都会消耗大量资源,频繁创建与销毁线程会带来很大的资源开销
资源消耗:活跃的线程会消耗系统资源。如果可运行的线程数量大于可用的处理器数量,闲置的线程会占用许多内存,并且频繁的线程上下文切换也会带来很大的性能开销
稳定性:操作系统在可创建的线程数量上有一个限制。在高负载情况下,应用程序很有可能突破这个限制,资源耗尽后很可能抛出OutOfMemoryError异常
-
提高响应速度
任务到达时,不再需要创建线程就可以立即执行
-
线程池提供了管理线程的功能
比如,可以统计任务的完成情况,统计活跃线程与闲置线程的数量等
使用场景
- 不适用场合
-
依赖性任务
在线程池中,如果任务依赖于其他任务,那么可能产生死锁。比如,在单线程的Executor中,如果一个任务将另一个任务提交到同一个Executor,并且等待这个被提交任务的结果,那么通常会引发死锁
-
使用ThreadLocal的任务
ThreadLocal可以存储线程级变量,将变量封闭到特定的线程当中。然而使用线程池时,这些线程都会被自由的重用,在线程池的线程中不应该使用ThreadLocal在任务之间传递值。
当线程本地值的生命周期受限于任务的生命周期时,可以在线程池的线程中使用ThreadLocal,任务结束后调用ThreadLocal.remove方法将已存储的值清除。
-
使用线程封闭机制的任务
在单线程应用程序中,不用考虑对象的并发安全问题,他们都被很好的封闭在单个线程当中。如果将单线程的环境换成线程池,那么这些对象有可能造成并发安全问题,失去线程安全性
-
不同类型或运行时长差异较大的任务
不同类型任务之间很可能存在依赖,并且他们执行的时长也不相同,在线程池中运行时很有可能造成拥塞,甚至死锁
-
适用场合
当任务是同类型且相互独立时,线程池的性能可以达到最佳
网页服务器、文件服务器、邮件服务器,他们的请求往往是同类型且相互独立的
架构
在线程池异常处理方案这篇博客中已经提到了线程池的架构,如图:

Executor:异步任务执行框架的基础
public interface Executor {
void execute(Runnable command);
}
通过使用Executor,将请求处理任务的提交与任务的实际执行解耦,只需要采用另一种不同的Executor实现,就可以改变服务器的行为。比如:
// 为每个任务分配一个线程
public class ThreadPerTaskExecutor implements Executor {
@Override
public void execute(Runnable r) {
new Thread(r).start();
}
}
// 以同步的方式执行每个任务
public class WithinThreadExecutor implements Executor{
@Override
public void execute(Runnable r) {
r.run();
}
}
ExecutorService:ExecutorService扩展了Executor接口,添加了一些用于管理生命周期和任务提交的方法
public interface ExecutorService extends Executor {
// 生命周期管理
void shutdown();
List shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
// 任务提交
Future submit(Callable task);
Future submit(Runnable task, T result);
Future submit(Runnable task);
List> invokeAll(Collection> tasks)
throws InterruptedException;
List> invokeAll(Collection> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
T invokeAny(Collection> tasks)
throws InterruptedException, ExecutionException;
T invokeAny(Collection> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
ExecutorService的生命周期有3中状态:运行、关闭、终止。ExecutorService在初始创建时处于运行状态。shutdown方法执行平缓的关闭过程:不再接受新任务,同时等待已提交的任务执行完成,包括在任务队列中尚未开始的任务。shutdownNow方法将尝试取消所有运行中的任务,并不再启动队列中尚未执行的任务。
所有任务完成后,ExecutorService将转入终止状态。可以调用awaitTermination来等待ExecutorService到达终止状态,或者通过轮询isTerminated来判断ExecutorService是否终止。
AbstractExecutorService ThreadPoolExecutor ScheduledThreadPoolExecutor: 线程池的实现
ThreadPoolExecutor扩展了ExecutorService接口,是线程池的具体实现。ScheduledThreadPoolExecutor支持定时以及周期性任务的执行。
ThreadPoolExecutor支持两种方式的任务提交:exec.execute(Runnable r)以及exec.submit(Runnable r)。关于任务的这两种提交方式在线程池异常处理方案已经提到过了,不再赘述。
定制线程池
先来了解一下线程池的创建:
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
以上是ThreadPoolExecutor的构造函数,看一下每个参数的含义:
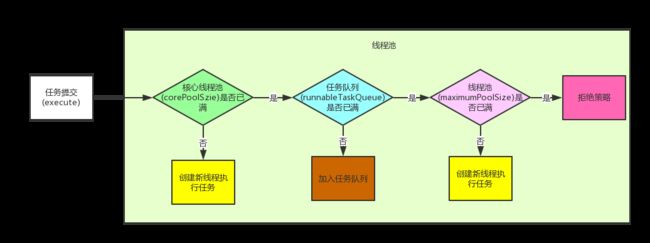
- corePoolSize
corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
-
runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。 可以选择以下几个阻塞队列。
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。下面会有介绍几种饱和策略。
keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
设置线程池的大小
线程池过大,会导致大量的线程在很少的cpu和内存资源上发生竞争,频繁的线程上下文切换也会带来额外的性能开销。线程池过小,导致许多空闲的处理器无法执行工作,降低吞吐率。
- cpu密集型
对于计算密集型的任务,当系统拥有n个处理器时,将线程池大小设置为n+1通常可以实现最优利用率。
- io密集型
对于包含io操作或其他阻塞操作的任务,由于线程不会一直执行,因此线程池的规模应该更大。有这么一个简单的公式:
N[threads] = N[cpu] * U[cpu] * (1 + W/C)
其中,N[threads]是线程池的大小,U[cpu]是cpu的利用率,W/C是任务等待时间与任务执行时间的比值。
可以通过一些监控工具获得cpu利用率等,Runtime.getRuntime().availableProcessors()返回cpu的数目
- 资源依赖
如果任务还依赖一些其他的有限资源,比如数据库连接,文件句柄等,那么这些资源也会影响线程池的大小:计算每个任务对该资源的需求量,用该资源的可用总量除以每个任务的需求量,所得的结果就是线程池大小的上限。
Executors
Executors提供了许多静态工厂方法来创建一个线程池:
newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。
具体情况可以结合Executors源码和ThreadPoolExecutor的构造函数查看。我们也可以模仿Executors的这几个工厂方法来定制自己的线程池执行策略。
扩展ThreadPoolExecutor
- 在线程池异常处理方案这篇总结曾经提到重写ThreadPoolExecutor的afterExecute方法来处理未检测异常,这就是扩展ThreadPoolExecutor的一个例子。除此之外,还可以在这些方法中添加日志、计时、监视等功能。
线程池完成关闭操作后会调用方法terminated。terminated可以用来释放Executor在其生命周期中分配的各种资源,以及执行发送通知、记录日志等操作。
下面编写一个利用beforeExecute、afterExecute和terminated添加日志记录和统计信息收集的扩展ThreadPoolExecutor。
public class TimingThreadPool extends ThreadPoolExecutor{
// 使用ThreadLocal存储任务起始时间,在beforeExecute设置起始时间,在afterExecute中可以看到这个值
private final ThreadLocal startTime = new ThreadLocal<>();
private final Logger logger = Logger.getLogger(TimingThreadPool.class.getName());
private final AtomicLong numTasks = new AtomicLong();
private final AtomicLong totalTime = new AtomicLong();
public TimingThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
logger.fine(String.format("Thread %s: start %s", t, r));
startTime.set(System.nanoTime());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
try {
long endTime = System.nanoTime();
long taskTime = endTime - startTime.get();
numTasks.incrementAndGet();
totalTime.addAndGet(taskTime);
logger.fine(String.format("Thread %s: end %s, time=%dns", t, r, taskTime));
} finally {
super.afterExecute(r, t);
}
}
@Override
protected void terminated() {
try {
logger.fine(String.format("Terminated: avg time=%dns", totalTime.get()/numTasks.get()));
} finally {
super.terminated();
}
}
}
- 扩展ThreadPoolExecutor的newTaskFor方法可以修改通过submit方法返回的默认Future实现FutureTask为自己的实现。在我们自己实现Future的类中可以针对任务做一些操作,比如定制任务的取消行为:
public class CacellingExecutor extends ThreadPoolExecutor {
public CacellingExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
protected RunnableFuture newTaskFor(Callable callable) {
if (callable instanceof CancellableTask) {
return ((CancellableTask)callable).newTask();
}
return super.newTaskFor(callable);
}
}
interface CancellableTask extends Callable {
void cancel();
RunnableFuture newTask();
}
abstract class SocketUsingTask implements CancellableTask {
private Socket socket;
public SocketUsingTask(Socket socket) {
this.socket = socket;
}
@Override
public void cancel() {在并发应用程序中,线程池是很重要的一块。读完《java并发编程实战》以及研究了一遍jdk源代码之后,总结一下线程池方面的知识~
try {
this.socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public RunnableFuture newTask() {
return new FutureTask(this){
@Override
public boolean cancel(boolean mayInterruptIfRunning) {
try {
SocketUsingTask.this.cancel();
} finally {
return super.cancel(mayInterruptIfRunning);
}
}
};
}
}
异常处理
异常处理这部分,在前面的博客中已经总结过了:线程池异常处理方案
饱和策略
当线程池达到饱和以后(maximumPoolSzie),饱和策略开始发挥作用。ThreadPoolExecutor的饱和策略可以通过setRejectedExecutionHandler来修改。当某个任务被提交到一个已经关闭的Executor时,也会用到饱和策略。jdk提供了几种不同的RejectedExecutionHandler实现:
- AbortPolicy
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
AbortPolicy是默认的饱和策略,该饱和策略将抛出未检查的RejectedExecutionException。调用者可以处理这个异常。
- CallerRunsPolicy
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
CallerRunsPolicy将任务回退到调用者,他不会在线程池的某个线程中提交任务,而是在调用execute的线程中运行,从而降低新任务的流量。
- DiscardPolicy
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
DiscardPolicy会悄悄抛弃任务,什么也不做。
- DiscardOldestPolicy
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
DiscardOldestPolicy会抛弃下一个将被执行的任务,然后重新尝试提交任务。
其他
- CompletionService
如果向Executor提交了一组计算任务,并希望在计算完成后获取结果,那么可以保留与每个任务关联的Future,然后轮询这些future的get方法,判断任务是否完成。这种方法虽然可行,但是有些繁琐。
CompletionService将Executor和BlockingQueue的功能融合在一起,可以将任务提交给他执行,然后使用类似于队列的take或poll方法获取已完成结果。
ExecutorCompletionService 实现了CompletionService,他的实现很简单,在构造函数中创建一个BlockingQueue来保存计算完成的结果。当提交某个任务时,该任务首先包装成为一个QueueingFuture,这是FutureTask的一个子类,他改写了done方法,将结果放入BlockingQueue中。ExecutorCompletionService的take和poll方法委托给了BlockingQueue。
- ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor以延迟或定时的方式执行任务,类似于Timer。由于Timer的一些缺陷,可以使用ScheduledThreadPoolExecutor来代替Timer。
Timer在执行所有的定时任务时只会创建一个线程,如果某个任务执行时间过长,就会破坏其他TimerTask的定时准确性。TimerTask抛出异常后,Timer线程也不会捕获这个异常,从而终止定时线程。尚未执行的TimerTask不会再执行,新的任务也不会被调度。
参考
java并发编程实战
聊聊并发(三)——JAVA线程池的分析和使用