5.1
(a)2^10
(b)19*2^7-3
(c)4*2^7=2^9
提示:因为要满足冰山立方体条件“count>=2”前三个维度只能是一下几种情况:
(1)(*,*,d3);(2)(*,d2,*);(3)(d1,*,*);(4)(*,*,*)
所以一共有4*2^7个
(d)共7个:
(1)(a1,d2,d3,d4,…,d9,d10):1
(2)(d1,b2,d3,d4,…,d9,d10):1
(3)(d1,d2,c3,d4,…,d9,d10):1
(4)(*,*,d3,d4,…,d9,d10):2
(5)(*,d2,*,d4,…,d9,d10):2
(6)(d1,*,*,d4,…,d9,d10):2
(7)(*,*,*,d4,…,d9,d10):3
5.3
(a)为了实现最小的个数,我们需要尽可能地“合并”这k个不相同的元组,只有这样在较高层才会有更少的单元(但是在基本方体中总是有k个单元)。我们首先观察两种极端情况:
1.如果当我们删除一个维(记为A),k个元组可以“融合”成一个单元时,这k个元组的形式为:t1=(a1,t'), t2=(a2,t'),..., tk=(ak,t')(其中t'为一个d-1维的元组)。然而,当我们保持属性A,忽略其它属性时却是低效的,因为这时仍然需要维持k个元组,因为k个元组之间无法进行任何合并操作。
2.在第一种情况中,只有忽略维A时才会发生“数量约减”。我们可以设想一下另一种情况:“约减”是以一种分布式的和“平均”式的方式发生。对于这两种情况的处理,我们看一个例子:
假设我们有一个8(A)*8(B)*8(C)的三维立方体,并且k=8。在第一种情况中,有8个基本单元,1(BC方体)+8+8=17 2-D单元,1+1+8(A方体)=10 1-D单元,1个0-D单元。考虑第二种情况,在整个立方体的角落中取一个2*2*2的3维子方体,用8个元组对其填充,我们将得到8个基本单元,4+4+4=12个2-D单元,2+2+2=6个1-D单元,1个0-D单元。因为36=8+17+10+1>8+12+6+1=27,所以情形2比情形1更好。
情形2总是较好的。假如K=4,这时情形1有4个基本单元,1+4+4=9个2-D单元,1+1+4=6个1-D单元,1个0-D单元,所以共有4+9+6+1=20个单元。对于情形2,我们可以建立一个2(B)*2(C)的2维子方体:4个基本单元,2+2+4=8个2-D单元,1+2+2=5个1-D单元,1个0-D单元,共4+8+5+1=18个单元。
对于这一问题的理解,可以按照一种启发式的思路考虑:我们想把k个不同的元组放入一个a*b*c的子方体中,在情形1中是以1*1*k的方式,情形2中是
很明显,a+b+c是1-D单元的数量,求1-D方体的最小数量,我们可以将其转化为给定条件abc=k时,求a+b+c的最小值。
综上所述,当我们把所有的k个元组放入一个x1*x2*....*xD的子方体,并且x1x2...xD=k(或者放宽条件将“=”改为“>=”)时,方体包含的单元的个数最小。单元的总数为

(b)单元个数最大的情况是:k个元组是完全“不相关的”或者“随机的”,即任意两个元组(t11,t12,...,t1D)和(t21,t22,...,t2D)只有忽略所有项才能合并,即:t1i≠t2i,i=1,2,...,D。
这时,不管我们如何选择忽略的维,都会产生k个元组,除非忽略所有的维。所以包含单元的最大个数为:
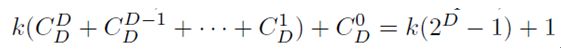
(c)在回答这个问题之前,有一个特殊情况:如果所有的基本单元都包含至少v个元组,那么所有的聚集单元都将满足条件。
1.最少情况:将k个元组放在在一个完全相同的基本单元中。因此,当所有k个元组都在一个基本单元时,共产生2D个单元
2.最大情况:我们如果用
(因为我们最多可以得到个基本方体),按照(b)的方法可得到最终结果
(d)通过(c)的分析,因为在这里只要调整k使k满足:k>=v,那么阈值v可以不用考虑。因此,为方便起见,我们将不考虑阈值v。
1.最少情况:如果我们把所有k个元组都放入一个基本单元中,那么闭单元的个数最少为1。
2.最大情况:给定一个p元组{t1,t2,...,tp},那么最多有一个闭单元。这样,我们可以得到上界
思路:假设有一个2*2*....*2的k维方体,则k个元组基于如下坐标系分布:t1=(1,0,...,0),t2=(0,1,0,...,0),...,tk=(0,0,0,...,0,1)。则(*1,*2,...,*p,0,...,0)是一个闭方体单元(因为把任意一个*变为0或1会导致计数变为p-1或1)。所以一共有2^k-1个闭方体单元。注意到这种情况下k<=D。
5.4
(a)
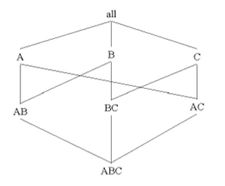
(b)all:1
A:1000000;B:100;C:1000;
小计:1001100
AB:1000000*100=100000000;BC:100*1000=100000;AC:1000000*1000=1000000000;
小计:1100100000
ABC:1000000*100*1000=100000000000
总和:1+1001100+1100100000+100000000000=101101101101*4=404404404404字节
(c)顺序计算,需要最少数量的空间B-C-A。如图所示:

计算二维平面需要的总主内存空间是:
总空间=
(100*1000)+(100000*100)+(100*100000)=20100000单元
20100000单元*4字节/单元=80400000字节
5.5
(a)一个解决稀疏矩阵问题的方法是使用多路数组聚合。第一步包括将基于数组的数据集分割成块或子立方体,使其小到可以装入内存进行方体计算。每一个块都是先压缩除去不含任何有效数据的单元,然后作为一个对象存储在磁盘上。为了用于存储和检索,可以使用“chunkID +偏移量”的单元格地址。第二步涉及通过一个最优顺序(最小化每个单元的重访问次数)访问方体单元并计算其聚集值,从而减少内存访问和存储成本。通过将方体的面按占用空间的大小升序排序并且顺序计算这些“面”,当要计算一个较大的“面”时,并且采用每次取一个方体块放入内存计算的计算方案,则在主存当中可以保留一个较小的面。
(b)为了处理增量数据更新,数据立方体要首先如(a)中描述的那样进行计算。然后,只有那些包含新数据的单元的块会被重新计算,而不需要重新计算整个立方体。因为在增量更新的条件下,一次只有一个块受到影响(被修改)。重新计算的值需要传送到相应的更高层的立方体。因此,可以有效地实现增量数据更新。
5.6
(a)2^101-6
(b)4
分别为:
(a1,a2,*,…,*)
(a1,*,*,…,*)
(*,a2,*,…,*)
(*,*,*,…,*)
(c)
(i)2^101-6
(ii)3个。
分别为:
(a1,a2,a3,…,a100):10
(a1,a2,b3,…,b100):10
(a1,a2,*,…,*):20
5.10
(a)
1、traveller维上卷到概念分层category,并按在category层取值为business切块
2、departure维上卷到概念分层city,并按其取值为L.A.切块
3、departure_time维上卷到概念分层ANY(*)
4、arrival维上卷到概念分层ANY(*)
5、arrival_time维上卷到概念分层ANY(*)
6、flight维上卷到概念分层company,并按其取值为AA切块
7、traveller维下钻到概念分层individual
8、departure_time维下钻到概念分层month
(b)有两个约束:最小支持度为10,平均费用大于500。使用冰山立方体算法,比如BUC,既然avg_fare>500不是反单调性的,应该转换成top-k-avg(反单调的),比如avg10(fare)>500。经过这种转化,就可以使用binning+min_sup进行修剪(先验剪枝)。