Introduction
- I will have failed if I haven’t shown you how school level mathematics and simple computer recipes can be incredibly powerful - by making our own artificial intelligence mimicking the learning ability of human brains.
Part 1 - How They Work
- A human may find it hard to do large sums very quickly but the process of doing it doesn’t require much intelligence at all.
We can process the quite large amount of information that the images contain, and very successfully process it to recognise what’s in the image. This kind of task isn’t easy for computers - in fact it’s incredibly difficult.

When we don’t know exactly how something works we can try to estimate it with a model which includes parameters which we can adjust. If we didn’t know how to convert kilometres to miles, we might use a linear function as a model, with an adjustable gradient.
A good way of refining these models is to adjust the parameters based on how wrong the model is compared to known true examples.
建立含参模型→猜测初始参数值→根据与已知数据集的误差修正参数(误差越大,修正越大)→循环修正过程直至达到误差要求。从神经网络的学习过程可见完美主义以及害怕犯错的问题,即世上并无完美之事,而错误让我们知道离正确有多远。
Visualising data is often very helpful to get a better understand of training data, a feel for it, which isn’t easy to get just by looking at a list or table of numbers.
We want to use the error to inform the required change in parameter
We moderate the updates.
This way we move in the direction that the training example suggests, but do so slightly cautiously, keeping some of the previous value which was arrived at through potentially many previous training iterations.
The moderation can dampen the impact of those errors or noise.
The moderating factor is often called a learning rate.神经网络中使用的学习速率告诉我们,学习时用力过猛会导致前面学过的内容被洗掉,以及犯了错误以后不要矫枉过正。
Traditional computers processed data very much sequentially, and in pretty exact concrete terms. There is no fuzziness or ambiguity about their cold hard calculations. Animal brains, on the other hand, although apparently running at much slower rhythms, seemed to process signals in parallel, and fuzziness was a feature of their computation.
Observations suggest that neurons don’t react readily, but instead suppress the input until it has grown so large that it triggers an output. You can think of this as a threshold that must be reached before any output is produced.
The sigmoid function is much easier to do calculations with than other S-shaped functions.
Interestingly, if only one of the several inputs is large and the rest small, this may be enough to fire the neuron. What’s more, the neuron can fire if some of the inputs are individually almost, but not quite, large enough because when combined the signal is large enough to overcome the threshold. In an intuitive way, this gives you a sense of the more sophisticated, and in a sense fuzzy, calculations that such neurons can do.
It is the weights that do the learning in a neural networks as they are iteratively refined to give better and better results.
The many calculations needed to feed a signal forward through a neural network can be expressed as matrix multiplication.

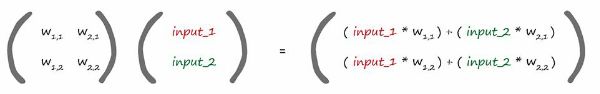
We’re using the weights in two ways. Firstly we use the weights to propagate signals forward from the input to the output layers in a neural network. Secondly we use the weights to propagate the error backwards from the output back into the network. It is called backpropagation.
Trying to vectorise the process: Being able to express a lot of calculations in matrix form makes it more concise to write down, and also allows computers to do all that work much more efficiently.
A matrix approach to propagating the errors back:

Gradient descent is a really good way of working out the minimum of a function.
To avoid ending up in the wrong valley, or function minimum, we train neural networks several times starting from different starting link weights.The final answer that describes the slope of the error function, , so we can adjust the weight :
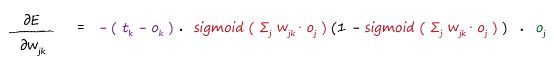
This is the key to training neural networks.
It’s worth a second look, and the colour coding helps show each part. The first part is simply the error. The sum expression inside the sigmoids is simply the signal into the final layer node. It’s just the signal into a node before the activation squashing function is applied. That last part is the output from the previous hidden layer node .The slope of the error function for the weights between the input and hidden layers:
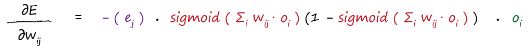
- The updated weight is the old weight adjusted by the negative of the error slope with a learning rate :
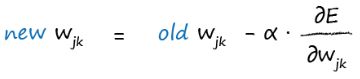
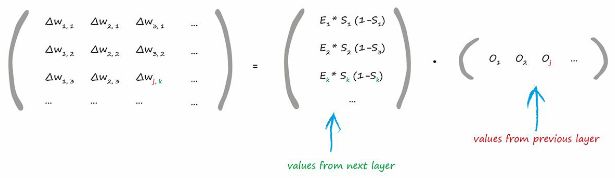
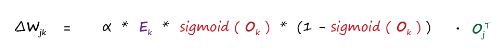
A very flat activation function is problematic because we use the gradient to learn new weights.
To avoid saturating a neural network, we should try to keep the inputs small.
We shouldn’t make it too small either, because the gradient also depends on the incoming signal ().
A good recommendation is to rescale inputs into the range 0.0 to 1.0. Some will add a small offset to the inputs, like 0.01.The weights are initialised randomly sampling from a range that is roughly the inverse of the square root of the number of links into a node. So if each node has 3 links into it, the initial weights should be in the range 1/(√3) = 0.577. If each node has 100 incoming links, the weights should be in the range 1/(√100) = 0.1.
This is sampling from a normal distribution with mean zero and a standard deviation which is the inverse of the square root of the number of links into a node.
This assumes quite a few things which may not be true, such as an activation function like the alternative tanh() and a specific distribution of the input signals.
Part 2 - DIY with Python
- Let’s sketch out what a neural network class should look like. We know it should have at least three functions:
initialisation - to set the number of input, hidden and output nodes
train - refine the weights after being given a training set example to learn from
query - give an answer from the output nodes after being given an input
# neural network class definition
class neuralNetwork:
# initialise the neural network
def __init__():
pass
# train the neural network
def train():
pass
# query the neural network
def query():
pass
Good programmers, computer scientists and mathematicians, try to create general code rather than specific code whenever they can.
A good technique to start small and grow code, finding and fixing problems along the way:
# initialise the neural network
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# learning rate
self.lr = learningrate
pass
# number of input, hidden and output nodes
input_nodes = 3
hidden_nodes = 3
output_nodes = 3
# learning rate is 0.3
learning_rate = 0.3
# create instance of neural network
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate)
Neural networks should find features or patterns in the input which can be expressed in a shorter form than the input itself. So by choosing a value smaller than the number of inputs, we force the network to try to summarise the key features. However if we choose too few hidden layer nodes, then we restrict the ability of the network to find sufficient features or patterns. We’d be taking away its ability to express its own understanding of the training data.
There isn’t a perfect method for choosing how many hidden nodes there should be for a problem. Indeed there isn’t a perfect method for choosing the number of hidden layers either. The best approaches, for now, are to experiment until you find a good configuration for the problem you’re trying to solve.
Overfitting is something to beware of across many different kinds of machine learning, not just neural networks.
神经网络只是机器学习的一种。
过度学习会导致对新事物的接受度下降,变得顽固。Neural network learning is a random process at heart and can sometimes not work so well, and sometimes work really badly.
Do the testing experiment many times for each combination of learning rates and epochs to minimise the effect of randomness that is inherent in gradient descent.
The hidden layers are where the learning happens. Actually, it’s the link weights before and after the hidden nodes that do the learning.
You can’t learn more than the learning capacity, but you can change the network shape to increase the capacity.问题:怎么修改代码,以设置隐藏层数和每个隐藏层的节点数?